Evaluation overview
Enterprise-grade evaluation is essential for deploying AI systems that are reliable, safe, and aligned with business objectives. Evaluation for GenAI output is also inherently challenging, because GenAI model responses are varied and context-dependent.
For example, let's say that you are evaluating a chatbot prototype for external release. The chatbot is supposed to answer questions about different health insurance plans that your company offers. You likely have a set of sample answers from internal testing that you need to evaluate, and the answers are likely quite varied.
An evaluation process that can drive meaningful business decisions and improvements about a GenAI model must be:
- Specialized: Because the potential output of a GenAI model is so varied and context-dependent, evaluation must be customized to suit the specific use case.
- Fine-grained: Evaluations should be detailed and focus on individual criteria that matter.
- Actionable: The results of the evaluation must provide insights that lead to improvements in the model.
Without a structured evaluation framework, it's difficult to assess model performance accurately or improve it effectively. Snorkel's evaluation workflow provides a comprehensive and flexible system to iteratively test and improve AI systems, making them reliable tools for enterprise applications.
Snorkel also provides a quick start option with smart defaults so you can get an initial evaluation immediately. As your evaluation needs evolve, Snorkel's evaluation suite enables you to craft a more powerful and customized benchmark within the same workflow.
This document explains the key concepts and components of GenAI evaluation. You can either jump directly into the evaluation workflow to begin implementing your evaluation, or continue reading to learn more about the conceptual foundation of effective GenAI evaluation.
Benchmark conceptual overview
Your benchmark is the collection of characteristics that you care about for a particular GenAI application, and the measurements you use to assess the performance against those characteristics. You'll run your benchmark multiple times over the life of your GenAI application so you can track improvements and drift in your app.
A benchmark consists of the following elements:
- Reference prompts: A set of prompts used to evaluate the model’s responses.
- Slices: Subsets of reference prompts focusing on specific topics.
- Criteria: Key characteristics that represent the features being optimized for evaluation.
- Evaluators: Functions that assess whether a model's output satisfies the criteria.
Each of these components plays a critical role in effectively measuring model performance.
Let's take a look at the medical insurance chatbot example.
Reference prompts conceptual overview
Gather or generate a set of prompts to be used for evaluation. These can come from:
- User query streams: Real user questions asked to a chatbot.
- Historical query logs: Past queries from users asked to human agents.
- SME annotations: Expert-created gold standard prompts.
- Synthetic generation: AI-generated test cases.
This is the set of questions that you will evaluate with this benchmark over and over again, gauging how the responses change as you work on your GenAI app. For example, you might have a set of questions from internal testing of the medical insurance chatbot, and another set of questions from real user support queries. These questions are your reference prompts that you want the chatbot to do well on.
Slices conceptual overview
A slice is a subset of data. Slices help group reference prompts into interesting subsets. For example, you might want to see how your chatbot performs for customers from a specific geographic region, or with questions in a specific product category. In colloquial terms, slices help you answer the question "How does my LLM system respond when users ask about X?"
Measuring such fine-grained performance helps in finding and fixing errors.
This is the heart of Snorkel's fine-grained approach to evaluation. In addition to getting a score for your GenAI app's overall performance, you'll also get a score for performance in specific types of queries.
Data slices represent specific subsets of the dataset that you want to measure separately. Data slices could be based on:
- Topic (e.g., administrative queries vs. dispute queries)
- Language (e.g., responses in Spanish)
- Custom slices relevant to enterprise-specific use cases
For the medical insurance chatbot example, you might identify one slice that is set of questions about coverage, and another slice that is a set of questions about billing.
A slicing function, which is a user-defined function (UDF), programmatically defines a slice. To learn more about slicing datasets, read Using data slices. You can also manually assign and delete datapoints from a slice.
Criteria conceptual overview
Criteria are the key characteristics that form a high-quality response. Criteria can be broad (e.g., "Correctness") or narrow (e.g., "Does not contain PII").
Potential criteria include:
- Correctness
- Relevance
- Completeness
For the medical insurance chatbot, you might decide to use a single criteria: correctness.
Label schemas for criteria
When you measure your dataset for a particular criteria, you must also define possible outcomes for the measurement.
The simplest criteria uses a yes/no (binary) label schema. Is the answer correct? Yes, it is correct; or no, it's not correct.
However, you can also have evaluators with a ranked or ordinal schema that uses labels and descriptions. For example, the default range for a new criteria uses a scale of 0 to 4, but can be extended or shortened as needed. To see how criteria work, read Create benchmark for evaluation.
Evaluators conceptual overview
A key aspect of building trustworthy, scalable, and repeatable benchmarks is creating the right mix of human and programmatic rating.
Human-generated ratings of your LLM's responses are useful, but they have a short shelf life. They become invalid when a new response set is generated by the LLM. These new responses require new annotations.
Programmatic evaluators, on the other hand, are evergreen.
Evaluators are automated raters for your criteria. They programmatically assess whether or how much responses meet criteria. Common types of evaluators include:
- LLM-as-a-Judge (LLMAJ): An LLM prompted to evaluate responses.
- Heuristic rules: Manually crafted rules that determine correctness.
- Off-the-shelf classifiers: Models detecting specific attributes (e.g., PII detection, toxicity classification).
- Embedding similarity: Comparing new responses to SME-annotated responses using an embedding similarity score.
- Programmatic supervision: Using predictive models built from weak supervision.
Evaluators can combine different techniques as Labeling Functions (LFs). Evaluators are far more scalable, but you also need them to be reliable.
SME-evaluator agreement and ground truth
How do know whether your evaluators are as reliable as your human annotators?
Subject Matter Experts (SMEs) can annotate a selected subset of responses from your GenAI app to create ground truth (GT) labels. Then, you can compare the human rating for that response with the evaluator rating for that same response. The goal is to build a trustworthy evaluator that rates responses like your human raters do. If your SME rates a response as good, the evaluator should rate it as good. If a human rates the response as bad, the evaluator should rate the response as bad.
This requires your evaluators and annotators to work with the same label schemas. When you create your criteria in Snorkel, you'll create a corresponding label schema. Then, when you create an annotation batch for that criteria for your SMEs, they will have the exact same options for labeling each response that the evaluator does. Snorkel can then directly compare the agreement rate, as part of refining the benchmark.
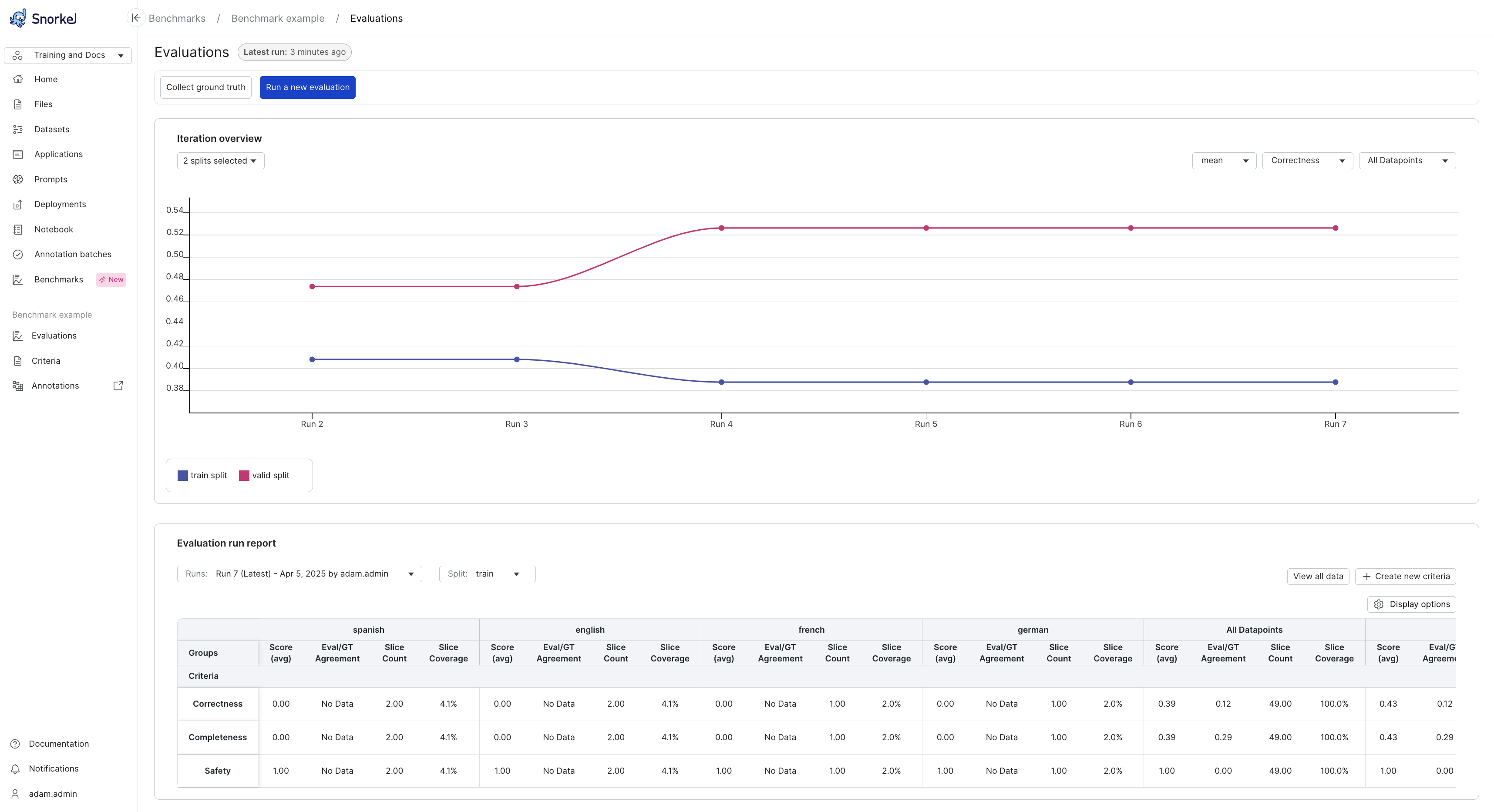
Evaluation results
The evaluation dashboard displays the results of your benchmark runs, organized by criteria. You can analyze performance metrics across different dimensions by using the available filters:
- Criteria filter: Focus on specific evaluation criteria to understand performance in particular areas.
- Data split filter: Compare results between training, validation, and test sets.
- Slice filter: Examine performance across different data segments defined by your slicing functions.
These filtering capabilities enable you to identify patterns, pinpoint areas for improvement, and make data-driven decisions about your GenAI application's performance.
Snorkel displays the evaluation results in a dashboard. Read more about the results in Run an initial evaluation benchmark.
Limits
When using Snorkel for evaluation, there is maximum of < 1k traces and < 100 steps per trace for each dataset.
LLM-as-a-judge (LLMAJ) iteration can only be used on train and valid splits.
You can only export the benchmark configuration via the Snorkel SDK.
Get started with GenAI evaluation
To get started, read the Evaluation workflow overview.