Evaluation workflow overview
Snorkel's evaluation framework follows a comprehensive workflow with these key phases:
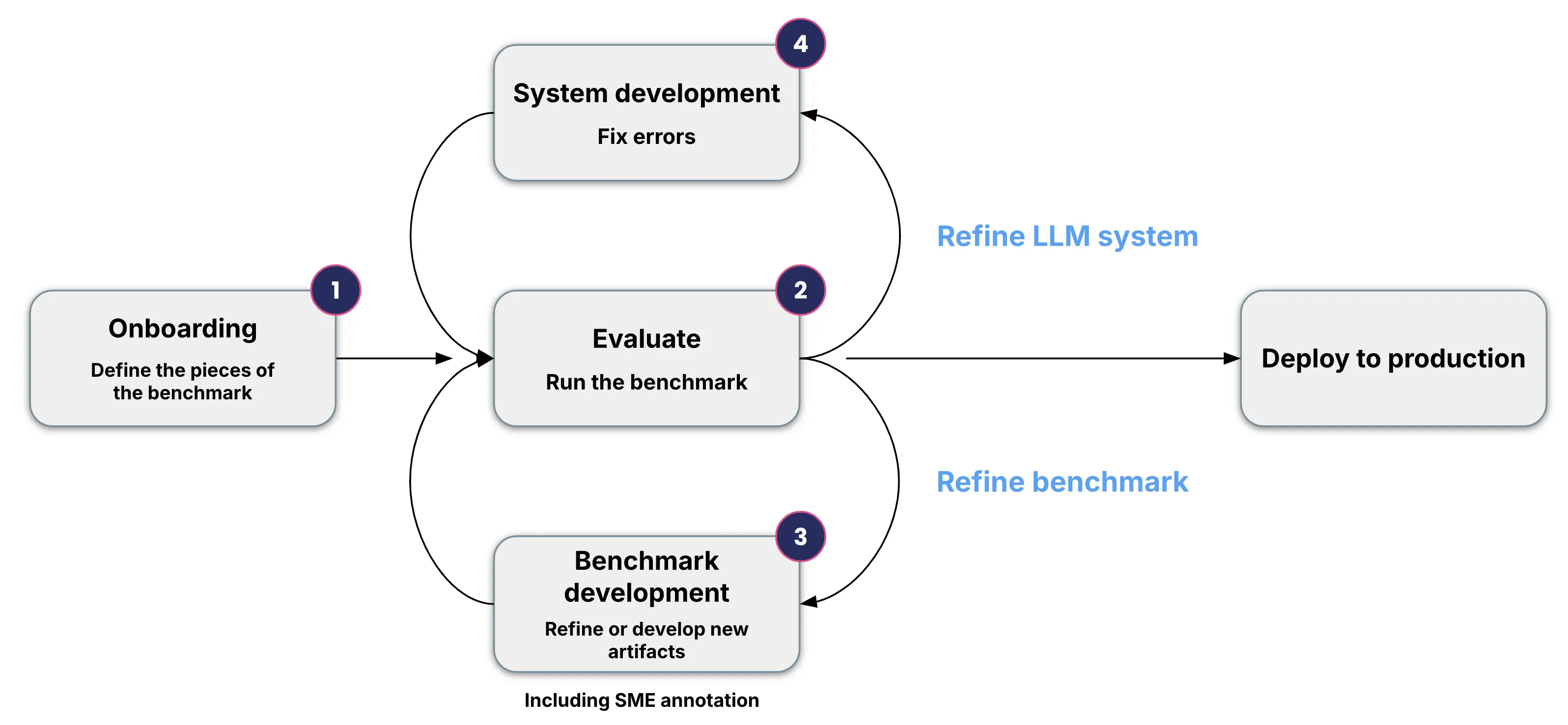
Read a summary of the evaluation workflow below, or dive into the details of each step by following the links:
-
Onboard artifacts: Prepare your evaluation dataset by mapping columns, importing data from external systems, defining data slices, and creating reference prompts.
-
Create benchmark: Define evaluation criteria, select appropriate evaluators (including LLM-as-judge evaluators), and set up your initial benchmark configuration.
-
(Optional) Create and customize LLMAJ evaluators: Add custom evaluators that address the criteria you care about.
-
Run benchmark: Execute the benchmark against your dataset, view performance across slices and criteria, and analyze the agreement between evaluators and ground truth.
-
Refine benchmark: Improve your evaluation by collecting ground truth labels, refining criteria, enhancing evaluators, and creating new data slices for comprehensive coverage.
-
Export benchmark: Export your benchmark configuration for integration with other systems, version control, or sharing across teams.
-
Improve GenAI app: Use evaluation insights to enhance your AI app through prompt development, RAG tuning, or LLM fine-tuning based on identified weaknesses.
This structured process enables organizations to build reliable evaluation systems that provide meaningful, actionable insights. The iterative nature of the workflow ensures that both your evaluation benchmarks and GenAI systems continuously improve, resulting in AI applications that consistently meet business objectives and user needs.