Create LLM-as-a-judge prompt
Use the evaluator builder to create and customize LLM-as-a-judge (LLMAJ) prompts. LLMs can be efficient and effective tools in your evaluation pipeline. With the right prompt, an LLMAJ can often correctly gauge whether your benchmark criteria is being met. This is an optional stage in the evaluation workflow.
Use Snorkel's evaluator builder to create and customize LLMAJ prompts for your evaluation pipeline.
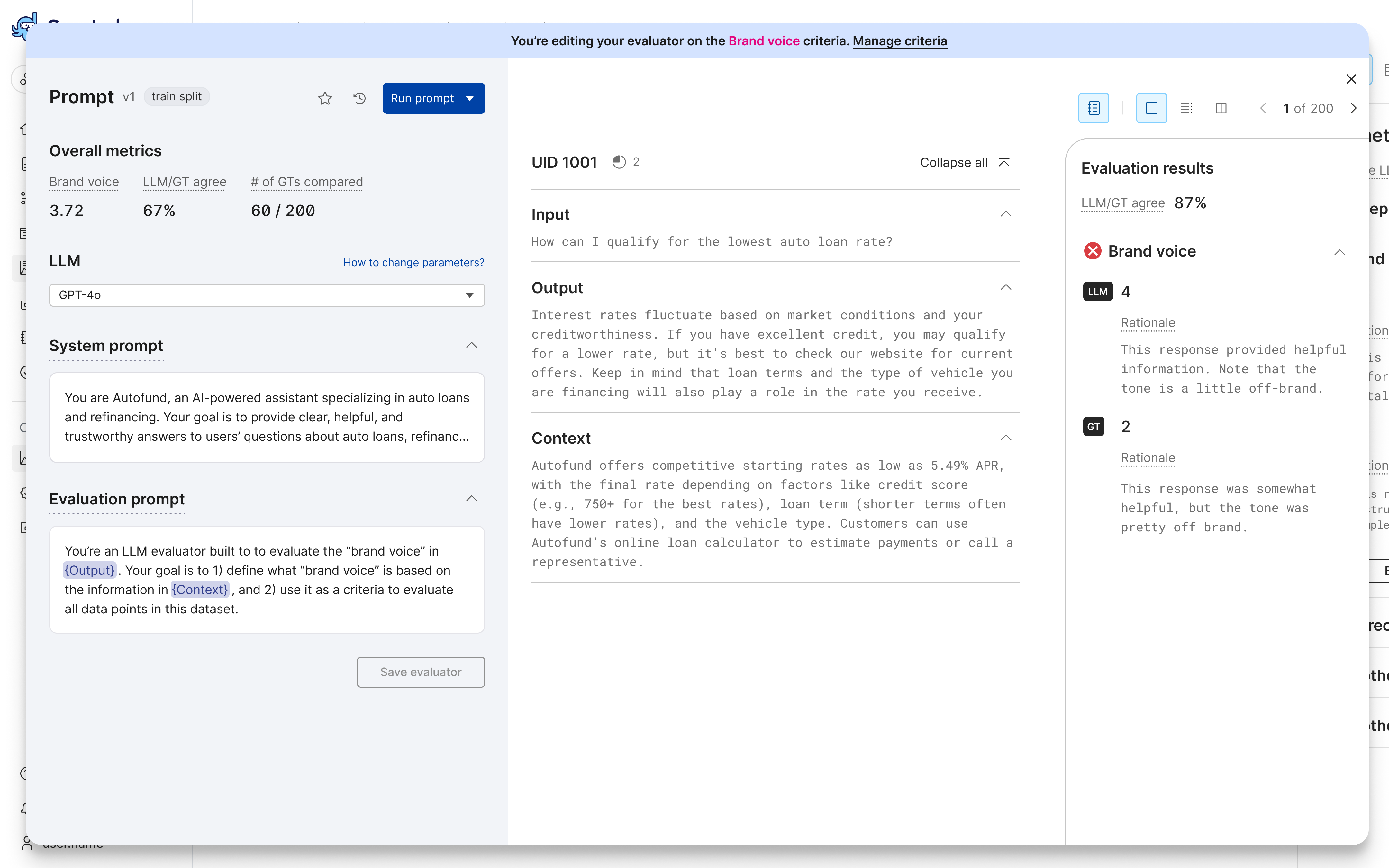
Evaluator builder overview
The evaluator builder provides a comprehensive environment for developing, running, and iterating on prompts to develop an LLM-as-a-judge (LLMAJ). You can experiment with different LLMs, system prompts, and evaluation prompts while tracking performance, ground truth (GT) provided by SME annotations, and scores for all your prompt versions.
Prompt development and management
The evaluator builder helps you develop effective prompts through:
- Experimentation with different LLMs, system prompts, and evaluation prompts.
- Version control to save and compare prompt iterations:
- Side-by-side comparison of different prompt versions and details.
- Ability to favorite and rename versions to track your progress.
- Ability to cancel an in-progress prompt run.
- Performance tracking through LLMAJ scores, rationale, and agreement scores.
- Aggregate metrics to understand overall prompt effectiveness.
- Multiple views (table and individual record) to examine:
- Input data.
- LLM responses, including evaluation score and rationale.
- GT and Eval/GT agreement scores.
Refinement through SME collaboration
Request and view subject matter expert (SME) annotations to improve prompts.
The evaluator builder supports:
- Viewing ground truth from annotators.
- Agreement scores between human and LLMAJ evaluations.
By comparing the evaluation score generated by your LLMAJ to ground truth provided by SME annotations, the Eval/GT agreement score provides a fast way to see how well your LLMAJ is performing and guide your prompt development to build the highest quality LLMAJ evaluator for your criteria.
Default and custom evaluators
The evaluator builder allows you to customize LLMAJ evaluators using out-of-the-box criteria or criteria created from scratch, giving you the flexibility to create evaluators that match your specific needs.
How to create a new LLMAJ prompt
-
From the Benchmarks page, select the benchmark where you want to add a custom LLMAJ prompt.
-
Select the Criteria tab from the left navigation menu.
-
Select + Create new criteria.
-
Add the following information for your prompt:
- Criteria name: Enter the name of your evaluation criteria.
- Description: Describe the criteria. As a best practice, your description should be clear and action-oriented, to help annotators.
- Output label schema: Select
Ordinalto enter multiple custom evaluation labels, orBoolean (yes/no). If you select Ordinal, edit the default labels to fit your use case. You can remove and add labels. - Require explanation/rationale: Option for the LLM to provide an explanation for its evaluation, when enabled.
-
Select Create criteria.
-
Your new prompt is now included on the Criteria page. Continue with the next section to customize the prompt, model, and more.
How to customize an LLMAJ prompt
To customize an LLMAJ prompt as an evaluator for a custom criteria, follow these steps:
-
From the Benchmarks page, select the benchmark where you want to add a custom LLMAJ prompt.
-
Select the Criteria page from the left navigation menu.
-
Select the criteria you want to edit. If you want to create a new one, follow the instructions in the previous section to add a new criteria, then continue here.
-
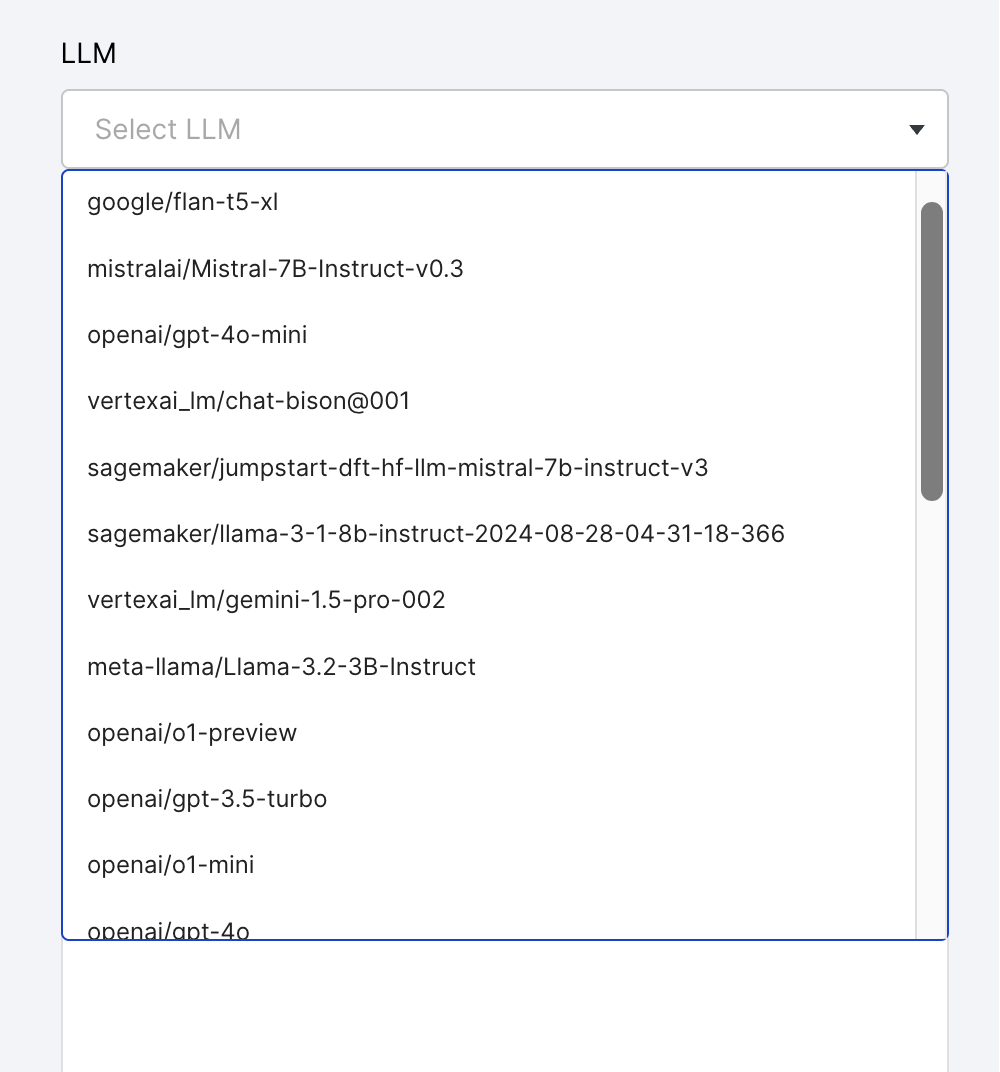
Select an LLM from the dropdown menu.
- Try using different models to optimize results.
- If required, enable additional models via the Foundation Model Suite.
- Try using different models to optimize results.
-
Enter a System Prompt and an Evaluation Prompt in the appropriate fields.
- System Prompt: Sets the overall context, guidelines, and role for the LLM. For example:
You are an expert AI evaluator, tasked with evaluating the correctness of responses based on given instructions. - Evaluation Prompt: Provides the LLM with specific instructions on what and how to evaluate. This might include a task, the steps for evaluation, formatting requirements, and the inputs the LLM should use.
- Note: Be sure to include the JSON formatting requirements in your evaluation prompt. See Best practices below for more information.

-
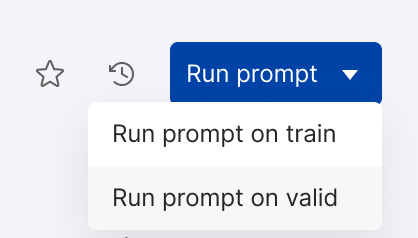
Select Run prompt. If you have both train and valid data splits, use the dropdown menu to choose where to run the prompt.
-
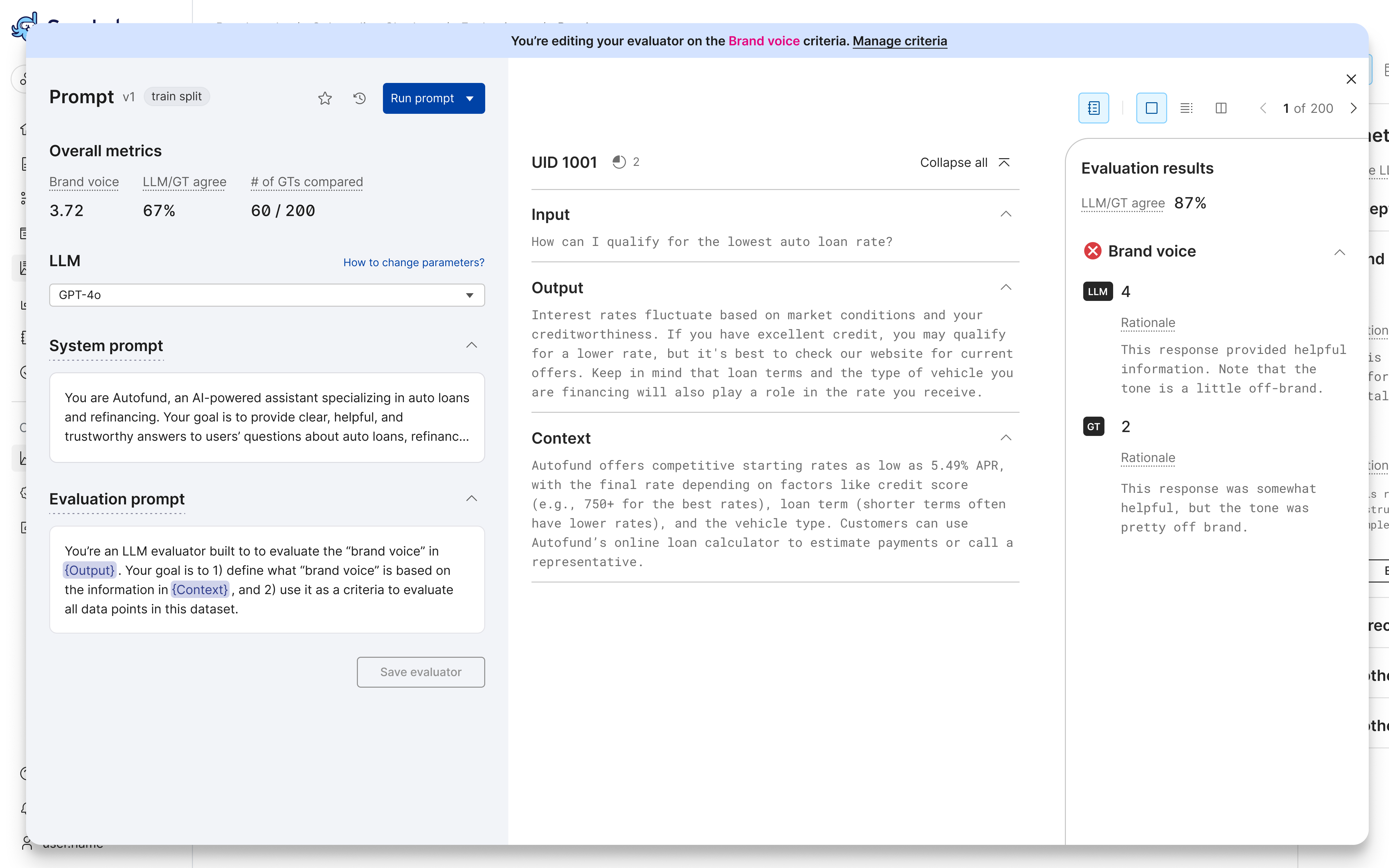
View the results, using the Record View or Table View.
- For each record, results include:
- LLMAJ scores and rationale, if selected for your criteria.
- Eval/GT agreement score that compares the LLM response to the ground truth annotation, if provided.
- Ground truth annotations for criteria score and/or rationale, if provided.
- For the entire dataset, results include:
- Aggregate evaluator metric.
- Failure rate.
- Aggregate Eval/GT agreement metric.
- The number of GTs compared to LLM responses to compute the agreement metric.
For more, see Scores and metrics.
The following steps include some of the actions you can take to help refine your prompt and improve your LLMAJ evaluator. For information on how to interpret the results and what actions you can take to improve the results, see How to improve an LLMAJ.
- For each record, results include:
-
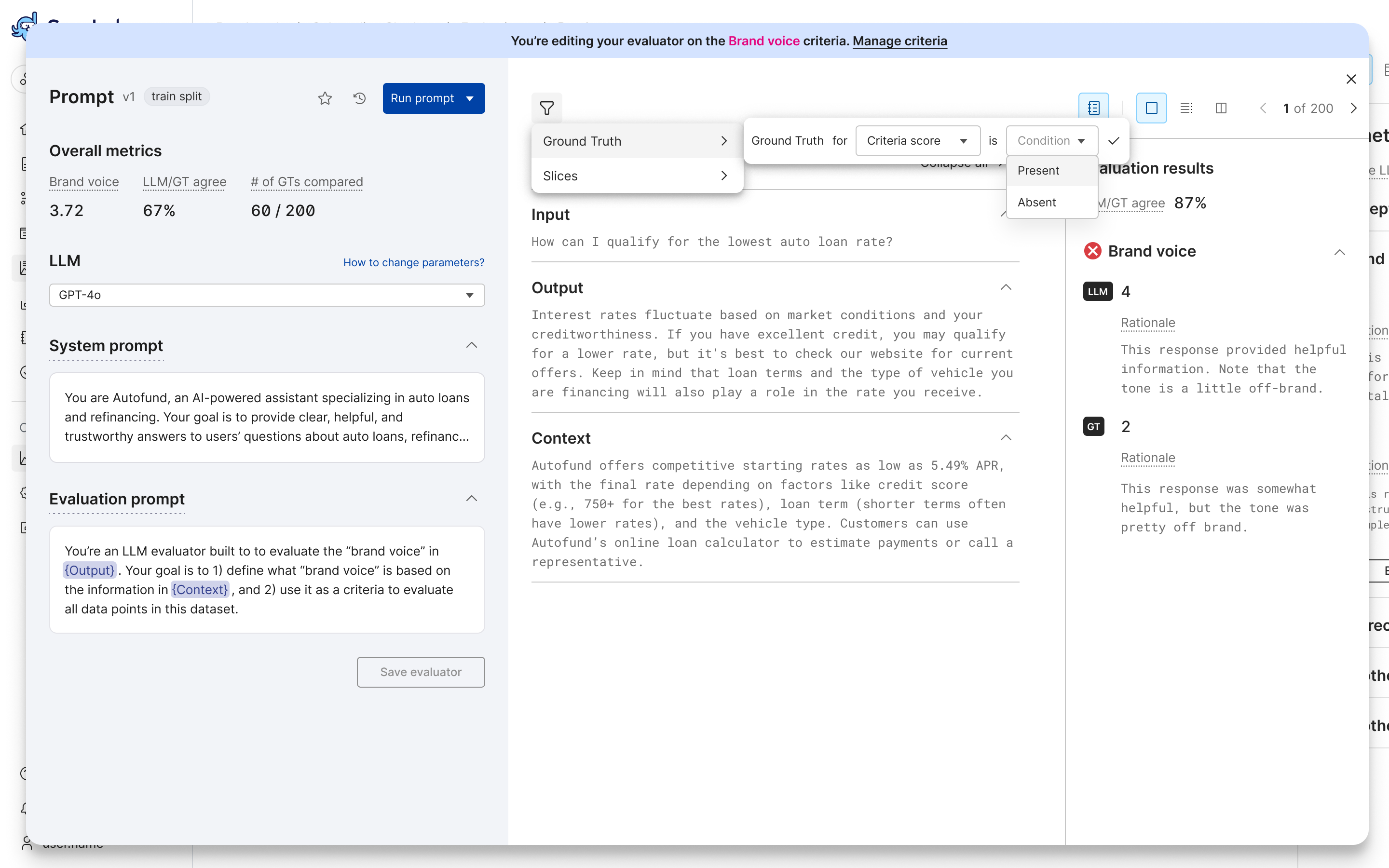
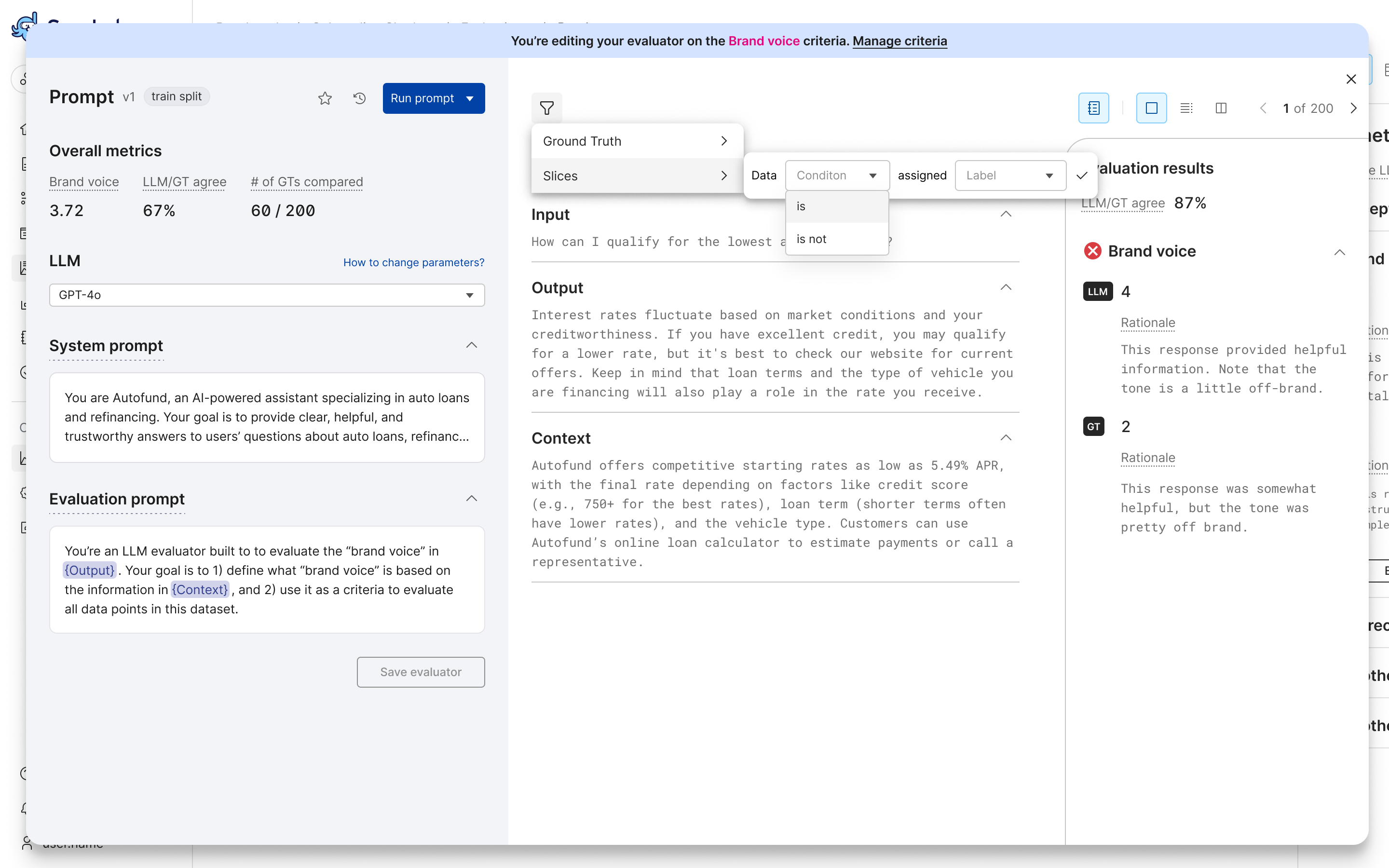
(Optional) Filter the results by ground truth or by slice:
- Filter on whether ground truth is present or absent:
- Filter by slice. For more about why data slices matter for evaluation, see the Evaluation overview.
- Filter on whether ground truth is present or absent:
-
(Optional) Collect ground truth annotations for your criteria by creating an annotation batch for SME feedback.
-
Continue to iterate on your prompt. Adjust the model, system prompt, and/or evaluation prompt as needed. For more, see Prompt tips.
-
Compare your prompt versions to help identify the prompt with the best performance as an evaluator. Viewing one record at a time, review the following details for every prompt version:
- Prompt Version
- Eval Score
- GT Score, if available
- Eval/GT Agreement
- Eval Rationale, if selected for the criteria
- GT Rationale, if available and selected for the criteria
-
Once you're happy with your prompt, select Save evaluator. That prompt version will be used as the LLMAJ evaluator for your benchmark whenever you run it.
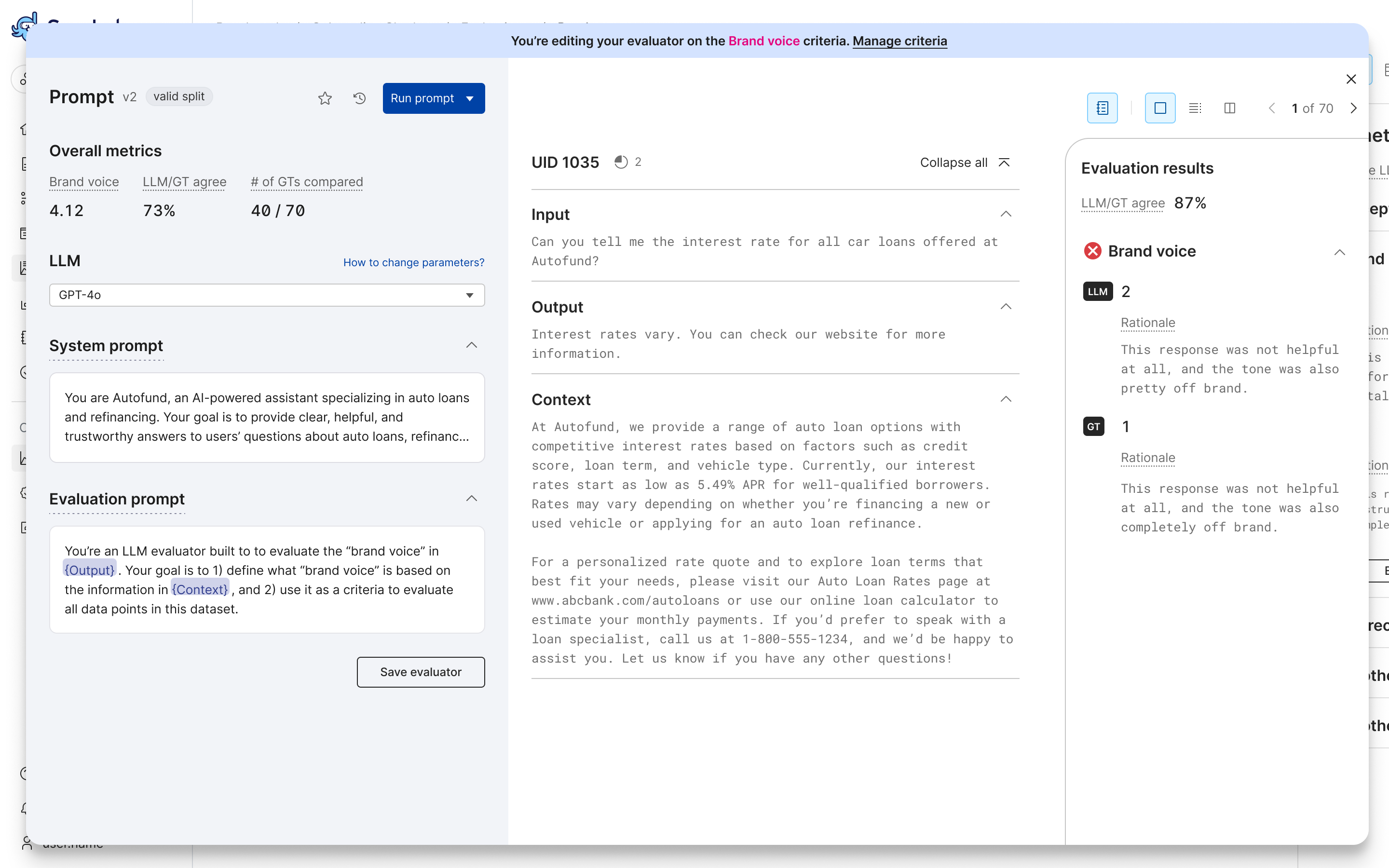
Scores and metrics
The evaluator builder provides a number of metrics to help you understand the performance of your LLMAJ prompt.
Overall metrics
The overall metrics are computed across all records in the prompt run. These metrics include:
- Eval (mean): The mean evaluator score, as generated by the LLMAJ, of all records in the prompt run.
- Failure rate: The percentage of records for which the LLMAJ was unable to generate a score.
- Eval/GT agreement: A weighted Cohen's Kappa score comparing the LLMAJ evaluator scores to the ground truth scores.
- # of GTs compared: The number of records where both ground truth and LLMAJ evaluator scores were present and compared, over the total number of records. This indicates how many data points were used to compute the Eval/GT agreement metric.
Per-record scores
The per-record scores are computed for each record in the prompt run. These scores include:
- Eval score: The score generated by the LLMAJ evaluator for the record, which assesses the criteria according to the instructions provided.
- GT score: The criteria score provided by human annotators for the record, if available.
- Eval/GT agreement: The comparison between the LLMAJ evaluator score and the ground truth score.
- Eval rationale: The LLMAJ generated rationale, explaining the evaluator score for the record, if selected for the criteria.
- GT rationale: The ground truth rationale for the record, if available and selected for the criteria.
How to improve an LLMAJ
SME annotations and GT agreement scores
Your biggest asset in improving your LLMAJ is your collection of evaluator/ground truth agreement scores. This score compares the ground truth (GT) score provided by human evaluators with the LLM-generated score for each record annotated in your dataset. Snorkel also provides an aggregate score for the entire prompt run.
Compare the LLMAJ score with the ground truth evaluation scores provided by SME annotations. When these scores align—that is, the LLM and human rate the same responses in the same way, whether that is a high, low, or medium score—you can confirm that your LLMAJ prompt is generating LLM evaluation scores as expected.
Ideally, you'll have 100% agreement between human and LLM evaluations.
The Eval/GT agreement score gives you a fast way to tell whether your LLMAJ is evaluating as expected. If it isn't, you can use the records with poor agreement scores for inspiration on how to adjust your prompt. You can filter the dataset to show only records where ground truth is present to help focus on the aggreement scores.
You do not need to annotate every record in your dataset. We recommend having a representative set of your data annotated. You can always add more ground truth if needed. To read more about cases whether you might need more or less GT, see Best practices below.
Prompt tips
-
Be specific about the evaluation criteria: Break down what your criteria means and how it should be assessed.
- Avoid vague terms like "better," "worse," or "overall quality."
- Be direct. For example, “Evaluate only the factual correctness of the response. Do not consider tone, style, or completeness unless they affect correctness.”
-
Explicitly specify JSON format response: For the LLM to respond with our expected
{ "Score": ..., "Rationale": ... }format, explicitly state and repeat your expected return.- LLMs are more consistent if you:
- Show the exact JSON structure expected for the response.
- Mention it in both the instructions and in any examples provided.
- See Best practices for examples of JSON formatting instructions.
- LLMs love to explain themselves, outside of JSON. To stop that explanation, say "Do not include any text outside the JSON block" or "Do not provide any information other than Score and Rationale."
- LLMs are more consistent if you:
-
Use clear role instructions: LLMs respond well to roles, which guide tone, rigor, and context. For example, your system prompt might say:
You are an expert AI evaluator, tasked with evaluating the correctness of responses based on given instructions. -
Structure the prompt cleanly: Give the model input in a consistent format. For example, structure your evaluation prompt like:
#### Task
As an AI assistant, your task is to evaluate the **correctness** of a given response based on a specific instruction, using your best judgement. Follow the steps below to perform the evaluation:
#### Evaluation Steps
1. **Understand the Instruction**: Carefully read the Instruction to grasp what is being asked.
2. **Assess Correctness**:
- Identify any errors, inaccuracies, or misconceptions in the facts.
- Determine if the Response provides accurate information relevant to the Instruction, based on the evaluation.
3. **Provide a Score and Rationale**:
- **Score**: Assign a score of 0 (incorrect) or 1 (correct). If there are any errors, inaccuracies, or misconceptions, give a score of 0.
- **Rationale**: Write a brief explanation highlighting why the Response received the score, mentioning specific correct information or inaccuracies.
#### Formatting Requirements
Present the evaluation, strictly, in json object format. Do not provide any information other than Score and Rationale.
```
Score: 0 or 1
Rationale: Your justification here.
```
#### Inputs
**Instruction:**
{instruction}
**Response:**
{response}
Now, proceed to evaluate the Response based on the guidelines above.
Iterating with train and valid splits
If you have multiple splits in your data, you can leverage a train and valid split to optimize your LLMAJ prompt without overfitting it to specific datapoints. You can iterate on the train split until you're happy with your results, then run it on the valid split to confirm that it performs well on data not used for iteration. This ensures you did not over-engineer your prompt specifically for the data in a single split, and that it will provide reliable scores for all splits in your dataset.
Use comparison view
Use the comparison view to easily assess multiple prompt versions at once.
Assess rationale
If you've asked your LLMAJ evaluator to provide rationale along with a score, read the rationale to confirm that it is:
- Logical.
- Includes references to the input data you provided to the LLM.
- Evaluates the specified criteria according to the instructions your provided.
A nonsensical or overly generic rationale response might be an indication that your model does not understand or is not obeying the prompt provided. In that case, try adjusting the prompt or running the same prompt on another model.
Best practices
-
Include JSON formatting requirements in your evaluation prompt. If not, your LLM response will not be parsed properly. For example, for a binary criteria that includes a rationale, your evaluation prompt should instruct the LLM to return responses in the following format:
#### Formatting Requirements
Present the evaluation, strictly, in JSON object format. Do not provide any information other than Score and Rationale.
Score: 0 or 1
Rationale: Your justification here. -
Use brackets (
{ }) when specifying column names in your prompts, e.g.{instruction}. -
Add enough ground truth to your dataset via SME annotation to enable representative Eval/GT agreement scores.
- Cases that often need more GT:
- High variability in the data: If the dataset has many different categories, slices, nuances, edge cases, etc., then more GT can help ensure broader coverage and avoid skewed evaluations.
- Consistent low GT/eval agreement score: More GT can help root cause issues.
- High stakes use cases: In healthcare, finance, and other industries with compliance requirements, more GT can help steer the system.
- Lots of proprietary data: Use cases involving data that most frontier models haven't seen.
- Cases where less GT may suffice:
- Mostly uniform dataset.
- Good enough evaluators.
- Price of mistakes are low.
- Common data similar to data models were trained on.
- Cases that often need more GT:
-
Use the Foundation Model Suite to enable additional LLMs.
Known limitations
These are the known limitations for LLMAJ prompt development:
- Only text datasets are supported.
- Multi-schema annotation must be enabled for all input datasets.
- Datasets can be up to 420MB in size.
- Out-of-the-box prompt templates assume your dataset has columns named
instruction,response, and (optional)context. You can still use a benchmark on a dataset with different column names, but you will need to create custom criteria and customize the prompt manually. - The evaluator builder supports developing a prompt on only the train or valid split. However, you can run the entire benchmark, including your saved evaluator, on train, valid, and test splits.
- The following models and model families support JSON mode. For models that don't
support JSON mode, you must add the JSON formatting requirements to the prompt manually (see Best practices above).
- openai/gpt-3.5-turbo-0125
- openai/gpt-3.5-turbo-1106
- openai/gpt-4-0125-preview
- openai/gpt-4-1106-preview
- openai/gpt-4-turbo-2024-04-09
- openai/gpt-4-turbo-preview
- openai/gpt-4o-2024-05-13
- openai/gpt-4o-2024-08-06
- openai/gpt-4o-2024-11-20
- openai/gpt-4o-mini-2024-07-18
- openai/o1-2024-12-17
- openai/o3-mini-2025-01-31
- openai/gpt-3.5-turbo
- openai/gpt-4-turbo
- openai/gpt-4o-mini
- openai/gpt-4o
- openai/o1
- openai/o3-mini
Next steps
Now that you've added one or more custom evaluators, we recommend running the benchmark to see how they rate your dataset.