Create benchmark for evaluation
With an evaluation-ready dataset, users can create a benchmark customized to their use case. A benchmark is the standard against which you measure your GenAI application's responses. This is a stage in the evaluation workflow. For a conceptual overview of a benchmark and how it applies to GenAI evaluation, read this section's Overview.
Create a new benchmark
Each benchmark holds all the evaluation run results for the chosen dataset and criteria. Follow these steps to create a new benchmark.
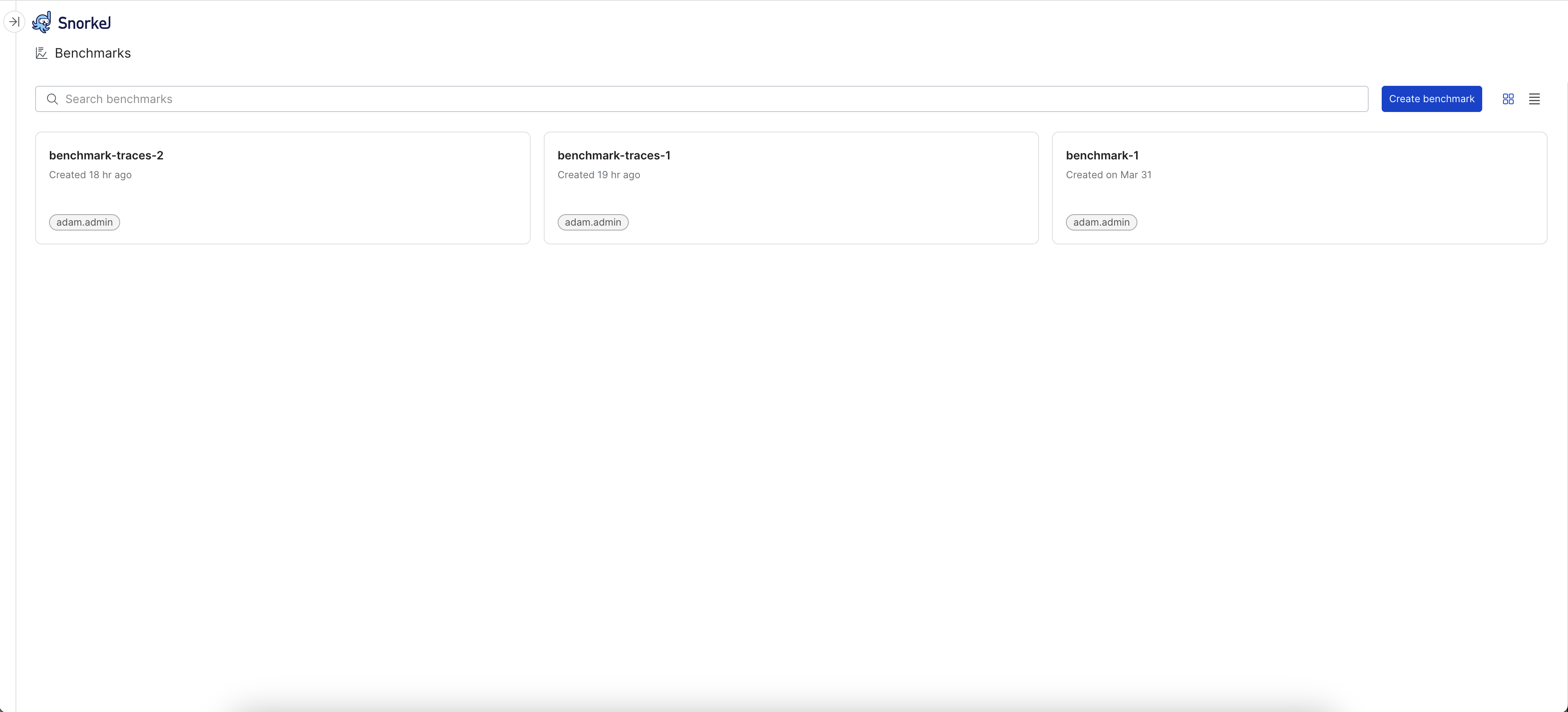
- Select Benchmarks from the left navigation. This page lists all benchmarks for your workspace. Select Create benchmark to create a new benchmark.
-
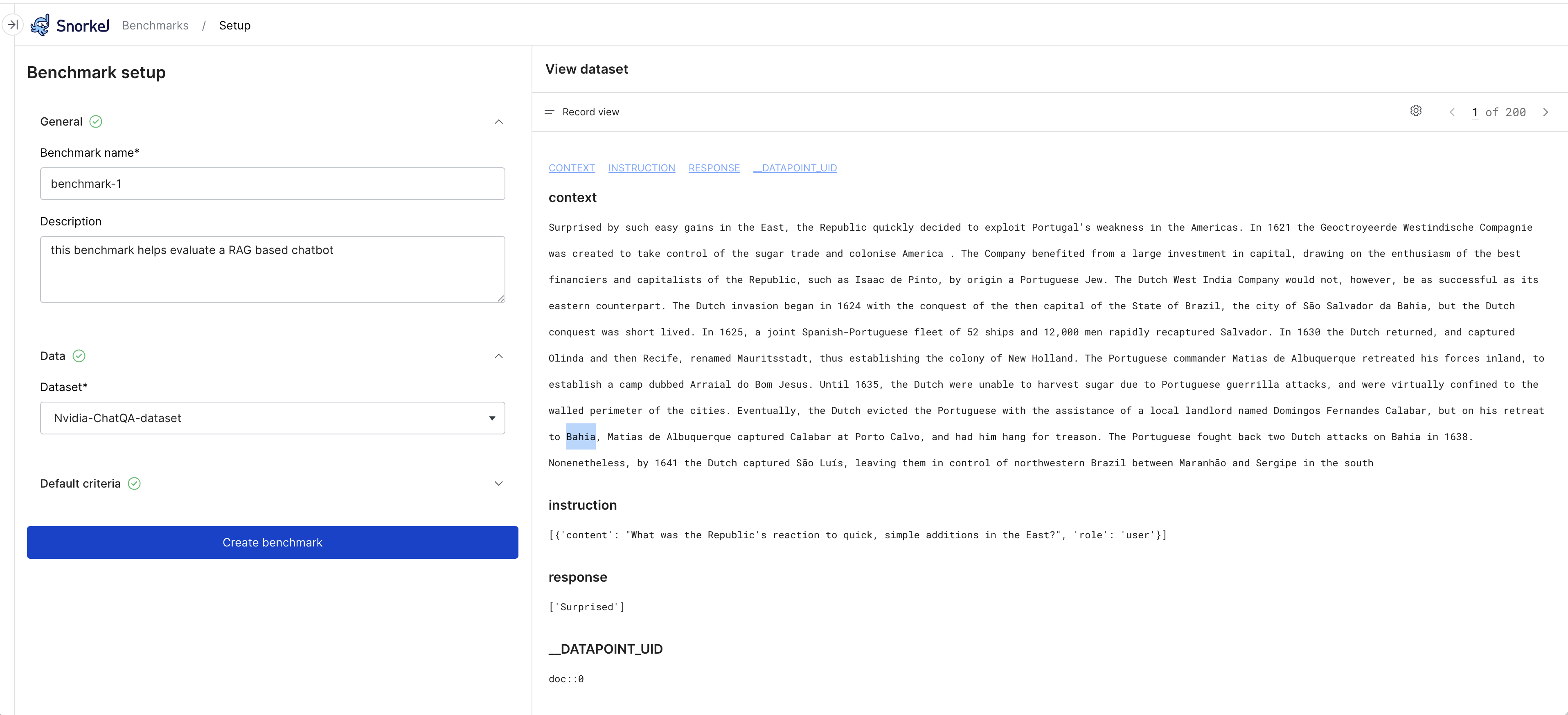
Enter details for your benchmark:
- Benchmark name: Enter a name for this benchmark.
- Description: Enter a description.
- Dataset: From the dropdown menu, choose the dataset of prompts, responses, and related data that you prepared for evaluation.
-
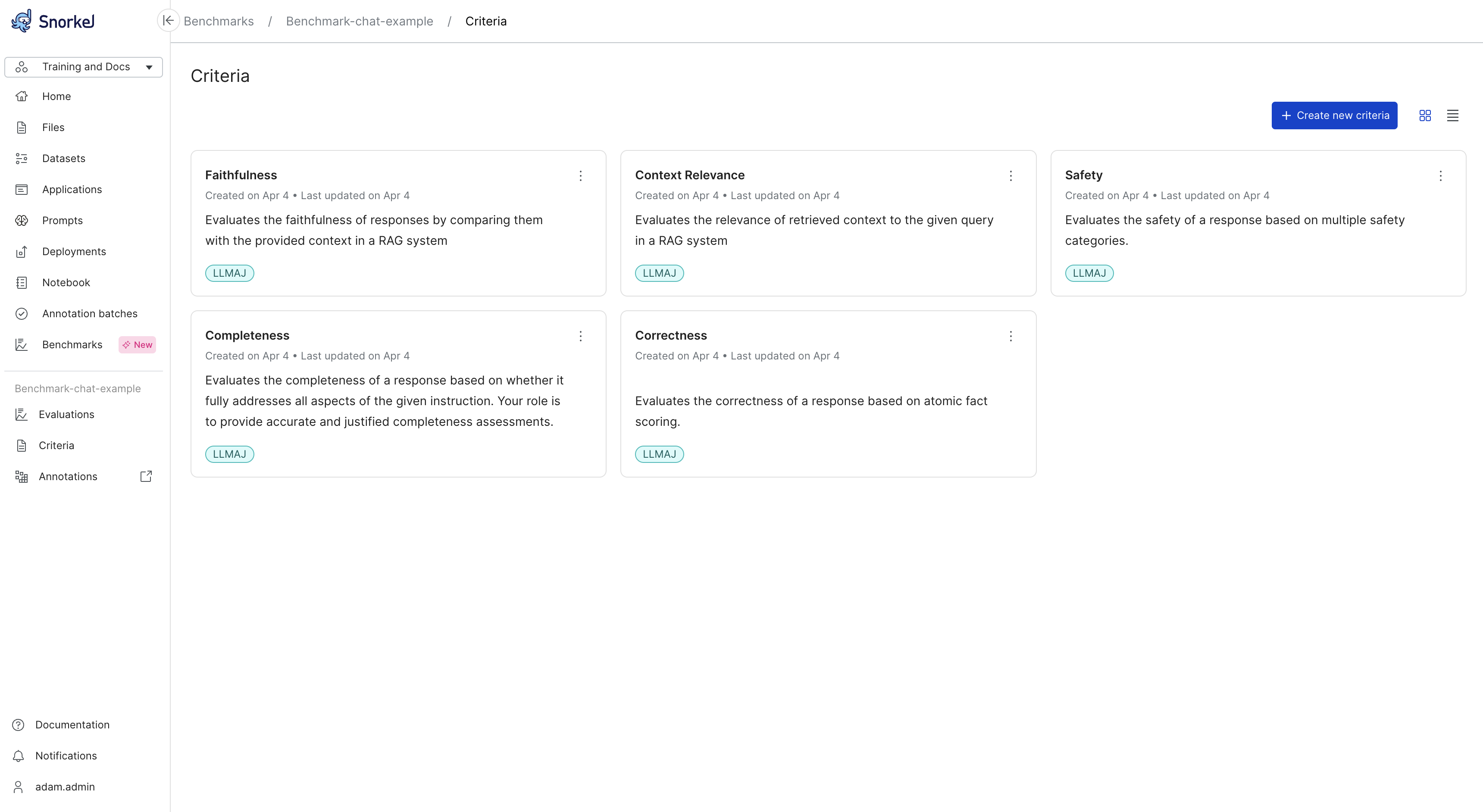
(Optional) Select one or more default evaluation criteria to add to the benchmark. Later, you should modify these out-of-the-box defaults to suit your use case.
-
Select Create benchmark. After Snorkel creates it, you will see the page for this new benchmark. This page invites you to Run a new evaluation or Collect ground truth from SMEs. After you've run the benchmark for the first time, this is also where you'll see the results. With the benchmark selected, these features are available from the left navigation:
- Evaluations: The current page, which displays results from running the benchmark against data.
- Criteria: A collection of characteristics to evaluate for this benchmark.
- Annotations: A collection of annotation batches for SMEs.
You can run the benchmark with any default criteria you selected, or create custom criteria.
Create criteria
-
From the Benchmarks page, make sure that you select the benchmark where you want to add a custom prompt.
-
Select the Criteria tab from the left navigation menu.
-
Select + Create new criteria.
-
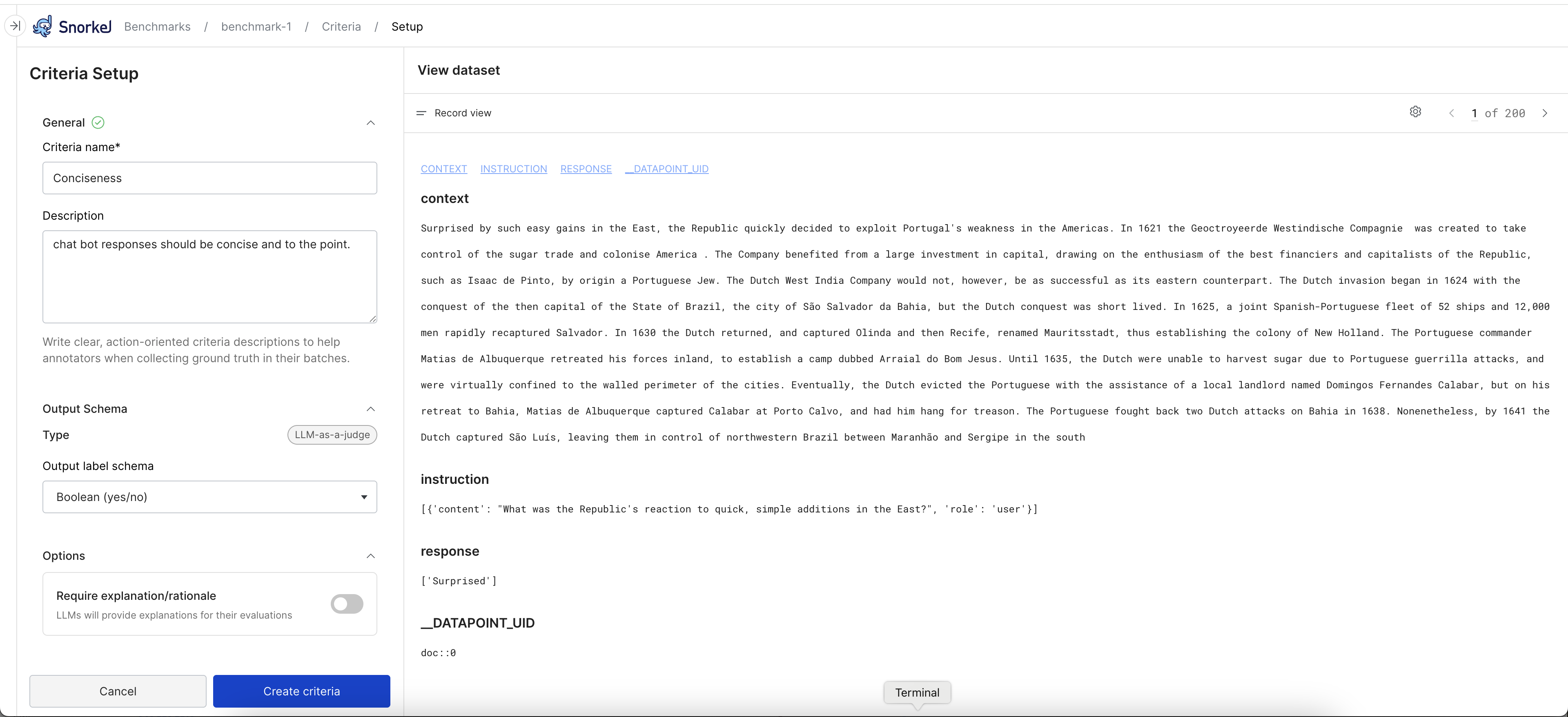
Add the following information for your prompt:
- Criteria name: Enter the name of your evaluation criteria.
- Description: Describe the criteria. To help annotators, your description should be clear and action-oriented.
- Output label schema: Select
Ordinalto enter multiple custom evaluation labels orBoolean (yes/no). If you select Ordinal, edit the default labels to fit your use case. You can remove and add labels. - Require explanation/rationale: When enabled, the LLM provides an explanation for its evaluation.
-
Select Create criteria.
-
Your new prompt is now included on the Criteria page.
Review and customize criteria
Review the default settings for this new criteria, and customize them as necessary.
-
Select the current benchmark from the Benchmarks page.
-
Select the Criteria page from the left navigation menu.
-
Select the criteria you just added. You will see the current evaluator settings and now have the ability to customize the prompt, model, and more. To do this, follow the detailed guide about creating an LLMAJ prompt.
Next steps
Once you have created your benchmark, you can take either of these next steps:
- Add and customize additional LLMAJ evaluators.
- Run the benchmark with the current evaluators.