Refine the evaluation benchmark
This is a beta feature available to customers using a Snorkel-hosted instance of Snorkel Flow. Beta features may have known gaps or bugs, but are functional workflows and eligible for Snorkel Support. To access beta features, contact Snorkel Support to enable the feature flag for your Snorkel-hosted instance.
After running the initial evaluation, you may need to refine it. This is a stage in the evaluation workflow. This step is iterative, with the end goal of having a benchmark that fully aligns with business objectives, so your measurements of the GenAI model's performance against it are meaningful.
Achieve a high quality benchmark by improving the agreement rate between your human subject matter experts (SMEs) and evaluators. That is, when a human gauges your GenAI application's response to be good or bad, the benchmark should similarly agree that the same response is good or bad. This leads to trust in the benchmark.
Collect ground truth from SMEs
You can create an annotation batch for your SMEs to help you gauge how your programmatic evaluators are performing.
-
From the Benchmarks page, select the benchmark for which you want to collect ground truth.
-
From the Evaluations page, select Collect ground truth. A dialog opens.
-
Fill out the details for the annotation batch you want to create:
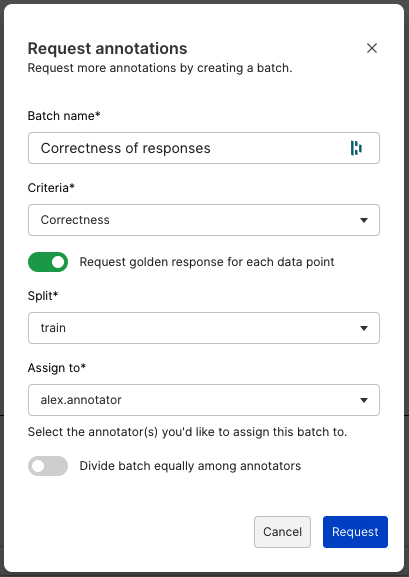
- Batch name: Create a name for this annotation batch.
- Criteria: Use the dropdown menu to select one or more criteria that you want annotators to rate the responses against in this batch.
- Request golden response for each data point: Toggle on if you want the SME to provide a preferred response for each question.
- Split: Select the data split for which you want to collect human feedback.
- Assign to: Choose one or more human annotators to work on this batch.
- Divide batch equally among annotators: Toggle on or off.
-
Select Request to assign the batch to your selected annotators.
Once the batch is complete, you'll be able to see the Eval/GT Agreement metrics for your dataset.
Understand the SME-evaluator agreement rate
To view the Eval/GT Agreement metrics for your dataset, view the Evaluations page for your benchmark.
Snorkel calculates the agreement rate between Subject Matter Expert (SME) outputs and evaluator outputs using specific metrics for binary and ordinal label schemas. Binary label schemas are yes/no, and ordinal label schemas have an arbitrary number of labels.
Let's define:
Datapoint agreement metric
For both binary and ordinal label schemas, the datapoint agreement measure is calculated as:
- Note that the agreement value ranges between 0 and 1.
- This measure reduces to either 0 (disagree) or 1 (agree) for binary label schemas.
Aggregate agreement metric
The aggregate measurement is a mean over the per-datapoint agreement measures.
- This value also ranges between 0 and 1, where higher values indicate greater agreement between SME and evaluator outputs.
- This measure reduces to the agreement rate for binary label schemas.
How to improve the SME-evaluator agreement rate
You can create or refine four types of artifacts to improve your benchmark trustworthiness:
- Ground truth labels: Add ground truth labels to ensure evaluators are accurate.
- Criteria: Adjust the criteria based on performance or new enterprise requirements.
- Data slices: Add new slices to segment your data based on identified gaps or underperforming areas.
- Prompts: Refine prompts to ensure that the evaluation covers all necessary aspects of the use case. See creating an LLMAJ prompt for more information.
For each artifact, here are some refinement steps you might consider.
Ground truth labels
After running the first round of evaluators, Snorkel recommends collecting a small number of ground truth labels for the relevant, defined criteria to ensure the evaluators are accurate. To do this:
- Create a batch with that specific criteria.
- Assign your subject matter experts to review that batch so you can collect ground truth labels from your subject matter experts in that batch.
note
If your evaluators are already validated, you can skip subject matter expert (SME) annotation. For example, an enterprise-specific pre-trained PII/PHI model may not require SME annotation for the use case.
- Commit these SME labels as ground truth. For more, see Commit annotations.
- Add ground truth evaluators and re-run the evaluation.
- Compare the ground truth evaluator with the programmatic evaluator for that criteria.
- If the numbers are similar, you can trust the evaluator going forward and don't need to collect ground truth labels for this criteria in each iteration.
- If the numbers are not similar, compare the places where the ground truth and evaluator disagree and improve the evaluator to better understand these situations.
Ideally, each evaluator reaches trusted status in the early phases of an experiment, and can be used to expedite the iterative development process. Snorkel recommends re-engaging domain experts for high leverage, ambiguous error buckets throughout development and in the final rounds of development as a pipeline is on its way to production.
How to improve evaluators
Certain criteria may be too difficult for a single evaluator. For example, an organization's definition of "Correctness" may be so broad that developers find that an Evaluator does not accurately scale SME preferences. In cases like this, Snorkel recommends one of the following:
- Break down the criteria into more fine-grained definitions that can be measured by a single evaluator.
- Rely on high-quality annotations for that criteria during development.
- Collect gold standard responses and create a custom evaluator to measure similarity to the collected gold standard response.
Criteria
Sometimes new criteria surface, or it becomes clear that the definition of a criteria should be adjusted. You can create a new LLMAJ evaluator, or tweak existing ones.
Reference prompts
If the number of responses in your data set is low within a particular topic, you can add more reference prompts by uploading another data source. For example, you may not have enough examples of Spanish-language queries to your GenAI application to create a useful benchmark. Collect or generate more query-response pairs of this type and add them to your data.
More best practices for refining the benchmark
- If most of your data isn't captured by data slices: Consider refining or writing new slicing functions.
- If a high-priority data slice is under-represented in your dataset: Consider using Snorkel's synthetic data generation modules (SDK) to augment your existing dataset. Also consider retrieving a more diverse instruction set from an existing query stream or knowledge base.
- If an evaluator is innaccurate: Use the data explorer to identify key failure modes with the evaluator, and create a batch of these innaccurate predictions for an annotator to review. Once ground truth has been collected, you can scale out these measurements via a fine-tuned quality model or include these as few-shot examples in a prompt-engineered LLM-as-judge.
- To scale a criteria currently measured via ground truth: From the data explorer dialog inside the evaluation dashboard, select Go to Studio. Use the criteria's ground truth and Snorkel's Studio interface to write labeling functions, train a specialized model for that criteria, and register it as a custom evaluator. These fine-tuned quality models can also be used elsewhere in the platform for LLM Fine-tuning and RAG tuning workflows.
- To increase alignment between LLMAJ and human evaluators: Enable the option to output a rationale for LLMAJ evaluators. This is useful to identify error patterns and fix areas of disagreement.
Next steps
Now that your benchmark is indicative of your business objectives, you can export it.