Snorkel architecture overview
The Snorkel AI Data Development Platform's architecture is comprised of the components illustrated below.
This document provides a detailed walkthrough of the platform's components, following the typical flow of data and requests through the system.
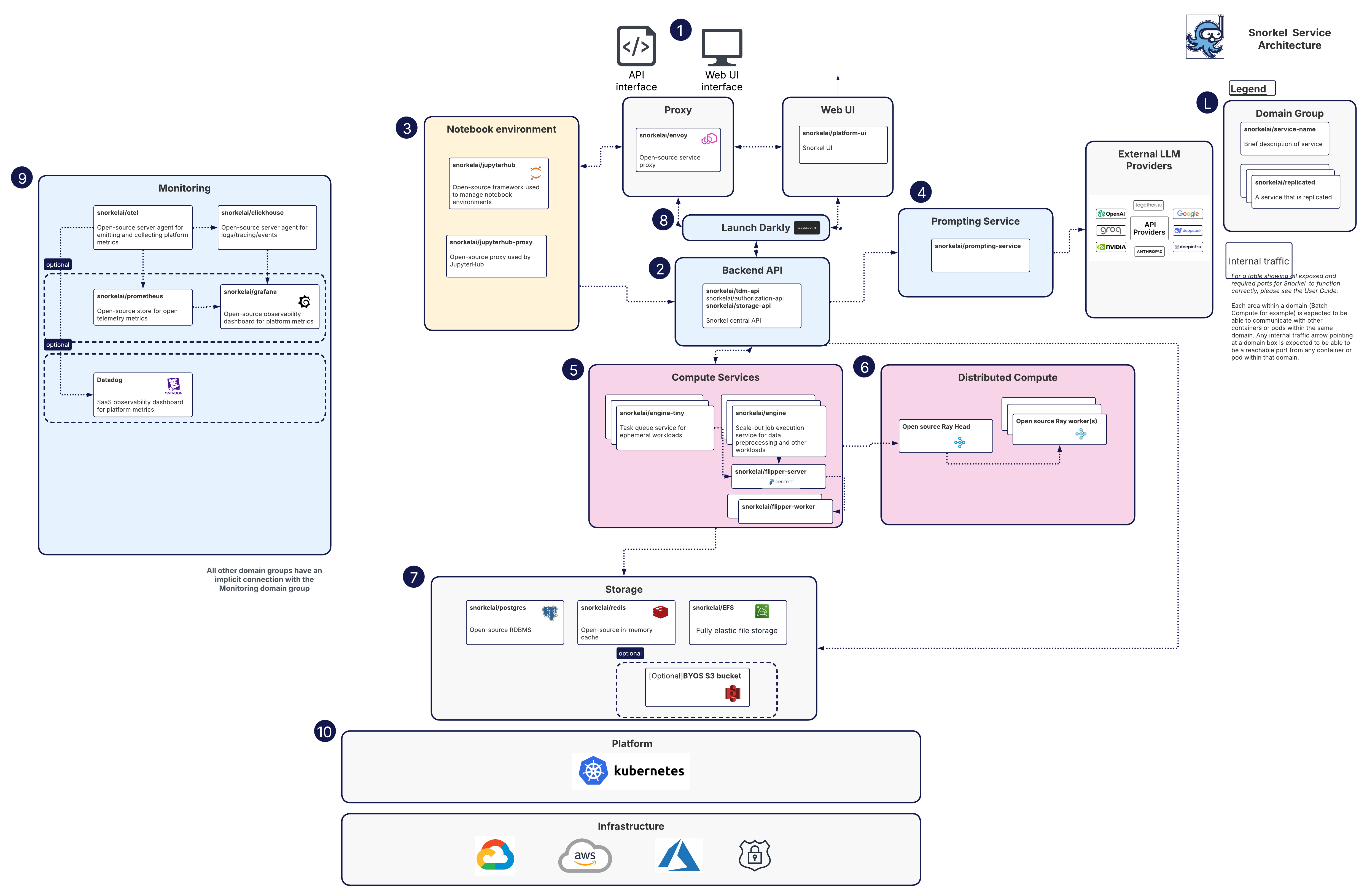
Select image to open full size
L: Legend
- Blue numbered circles (1–10) mark the typical request path and highlight key supporting systems, correlating directly with the numbered sections below.
- Each rounded rectangle on the diagram represents a Domain Group, a logical collection of related services or a distinct functional area within the platform.
- Cards contain a service name and description within a functional area.
- Stacked cards within a domain indicate replicated services for high availability and load balancing, or multiple instances of a component.
User interaction and control plane
1. User entry points & API gateway
Users interact with the Snorkel AI Data Development Platform through two entry points:
the Web UI (snorkelai/platform-ui), designed for interactive workflows,
and a programmatic API, accessible via the SDK and notebooks.
All incoming traffic is routed through Envoy (snorkelai/envoy), which
acts as the central API gateway. Envoy handles critical ingress functions,
including TLS termination for secure communication, intelligent request
routing to the appropriate backend services, and service discovery within
the cluster.
2. Backend API and control plane
All user requests land on the Backend API, which functions as the platform's central control plane. This is a collection of core services responsible for orchestration and policy enforcement:
snorkelai/tdm-api: Manages core application logic.snorkelai/authorization-api: Handles authentication (AuthN) and authorization (AuthZ).snorkelai/storage-api: Mediates access to the data plane.
3. Notebook environment
For users who require code-centric, exploratory workflows, the platform
provides an integrated JupyterHub environment. This includes
snorkelai/jupyterhub and snorkelai/jupyterhub-proxy, which are also
fronted by Envoy to ensure consistent routing and security. Code executed
within notebooks interacts with the same Backend API (Step 2) to ensure
all operations are consistent and secure.
LLM and compute services
4. Prompting service & external LLMs
For workflows involving Large Language Models (LLMs), the Backend API includes prompting APIs that manage secure connections to various External LLM Providers like OpenAI, Anthropic, and Google.
5. Compute services and workflow orchestration
The Backend schedules all major data processing and model training workloads onto the platform's Compute Services. This layer is composed of:
snorkelai/engine-tiny: Optimized for short-lived or ephemeral tasks.snorkelai/engine: Designed for scale-out, longer-running pipelines.
To manage complex, multi-step jobs, these engines use Flipper
(snorkelai/flipper-server and snorkelai/flipper-worker), Snorkel's
internal workflow orchestration service, to execute Directed Acyclic Graphs
(DAGs) and other workloads.
6. Distributed execution on Ray
For tasks that require massive parallelism, Flipper orchestrates workloads on a Ray Cluster (composed of a Ray Head and Ray Workers). Ray provides a highly elastic and distributed compute environment, allowing the platform to efficiently scale processing across multiple nodes.
Data, storage, and platform foundations
7. Data plane and storage
All platform services and compute jobs interact with a robust and multi-faceted data plane for persistence and caching:
- Postgres (
snorkelai/postgres): Serves as the primary relational database for application metadata, user information, and job state. - Redis (
snorkelai/redis): Provides a low-latency cache for frequently accessed data to accelerate performance. - EFS (
snorkelai/EFS): Offers shared elastic file storage for artifacts and datasets that need to be accessed across multiple services. - Bring-Your-Own (BYO) S3 Bucket (Optional): Customers can configure the platform to use their own S3-compatible object storage for full control over their datasets and model artifacts.
8. Feature flag management
To enable rapid iteration and safe rollouts, both client applications and backend services fetch feature flags from LaunchDarkly. This allows new features and workflows to be enabled or disabled dynamically without requiring a full redeployment of the platform.
9. Monitoring and observability
Comprehensive monitoring is a critical cross-cutting concern. Every service domain emits telemetry to the Monitoring group. The stack includes:
- OpenTelemetry (OTel) agents for collecting telemetry data.
- Prometheus for aggregating metrics.
- ClickHouse for storing logs and traces.
- Grafana for creating internal dashboards.
- Datadog is available as a SaaS dashboard option for customers.
10. Infrastructure on Kubernetes
The entire platform runs on Kubernetes, which handles container orchestration, scaling, and service management. This container-native approach ensures that the Snorkel Platform is infrastructure-agnostic and multi-cloud compatible, capable of being deployed on Google Cloud (GCP), Amazon Web Services (AWS), Microsoft Azure, or in on-premises data centers.
Internal traffic
Each area within a domain (Batch Compute for example) is expected to be able to communicate with other containers or pods within the same domain. Any internal traffic arrow pointing at a domain box is expected to be able to be a reachable port from any container or pod within that domain.