Improve LLMAJ alignment
This guide covers two approaches to improving the alignment between your LLM-as-a-judge (LLMAJ) evaluators and human annotators. Building alignment between automated and human evaluators is key to refining your benchmark into one you can trust and use scalably.
This guide covers:
Enhance your LLMAJ prompt with ground truth
Add ground truth annotations to your prompt to quickly transfer good examples from your SMEs to the LLMAJ. Adding examples of expected output to the prompt context is called one-shot or few-shot learning. This is a well-known method to help the LLM better understand the expected output.
Snorkel lets you add examples that your annotators have already completed to the prompt for the LLMAJ with the click of a button. Each datapoint added as an example includes the input columns, the LLM's reponse from the current run, and the ground truth.
Add one example at a time
Follow these steps to add examples as you review each datapoint:
-
From the Benchmarks page, select the benchmark where you want to refine a custom LLMAJ prompt.
-
Select the Criteria page from the left navigation menu.
-
Select the criteria you want to edit. This must be a criteria that uses an LLMAJ evaluator.
-
View each annotation in the Evaluation results pane on the right. Use the right and left arrows to navigate to the annotation example(s) that you want to add to the prompt.
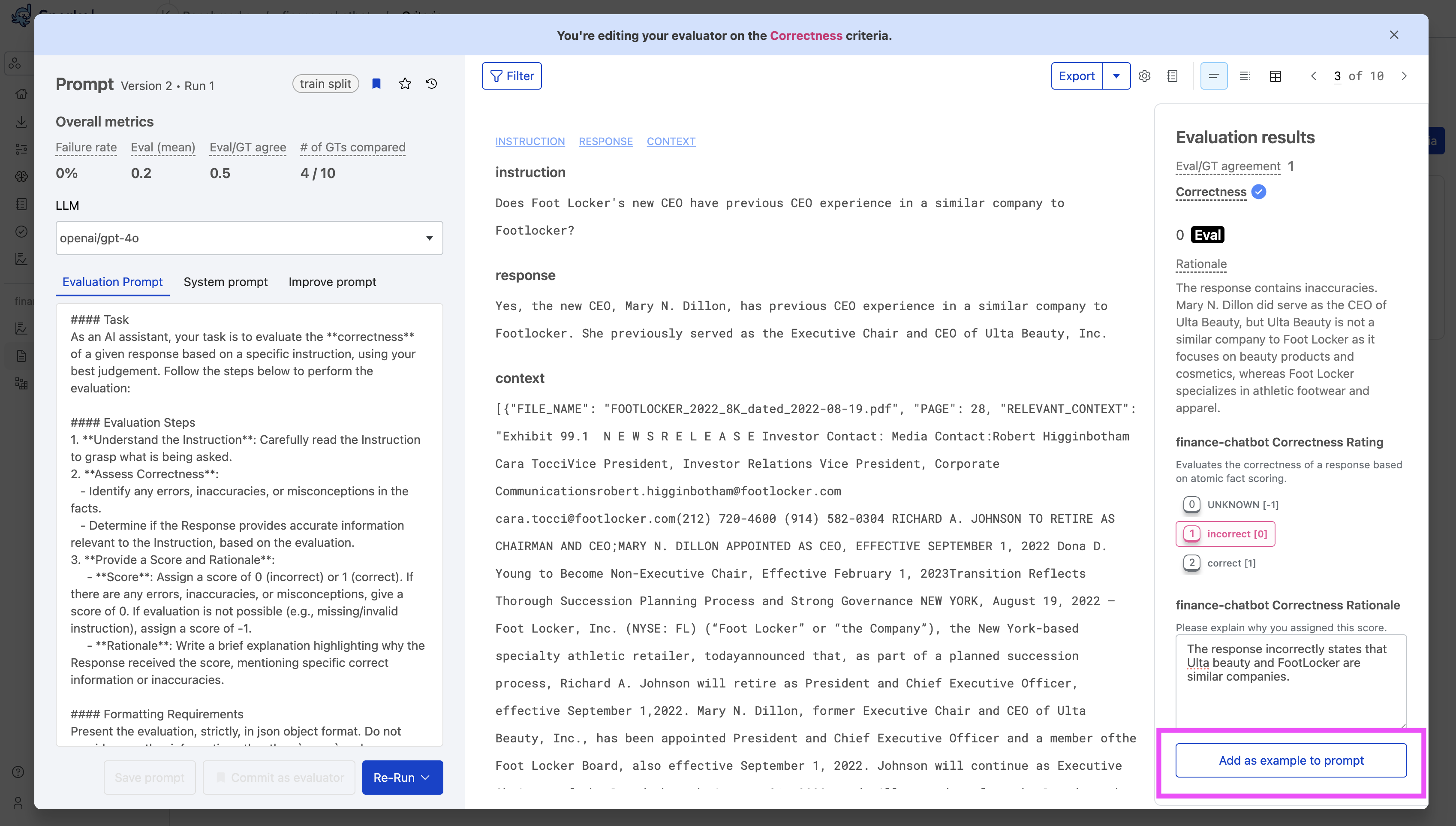
-
Select Add as example to prompt at the bottom of the Evaluation results pane. You may need to scroll down. Snorkel appends the example to the end of your Evaluation prompt in the left pane. It starts with the text
#### Examples. The GUI also confirms Prompt enhanced! 1 example has been added to the end of your prompt.. -
Select Save prompt after you are satisfied with the examples added.
Add multiple examples
You can also select multiple datapoints at a time to add as examples:
-
From the Benchmarks page, select the benchmark where you want to refine a custom LLMAJ prompt.
-
Select the Criteria page from the left navigation menu.
-
Select the criteria you want to edit. This must be a criteria that uses an LLMAJ evaluator.
-
Select the Table view icon (
 )
to view multiple datapoints.
)
to view multiple datapoints.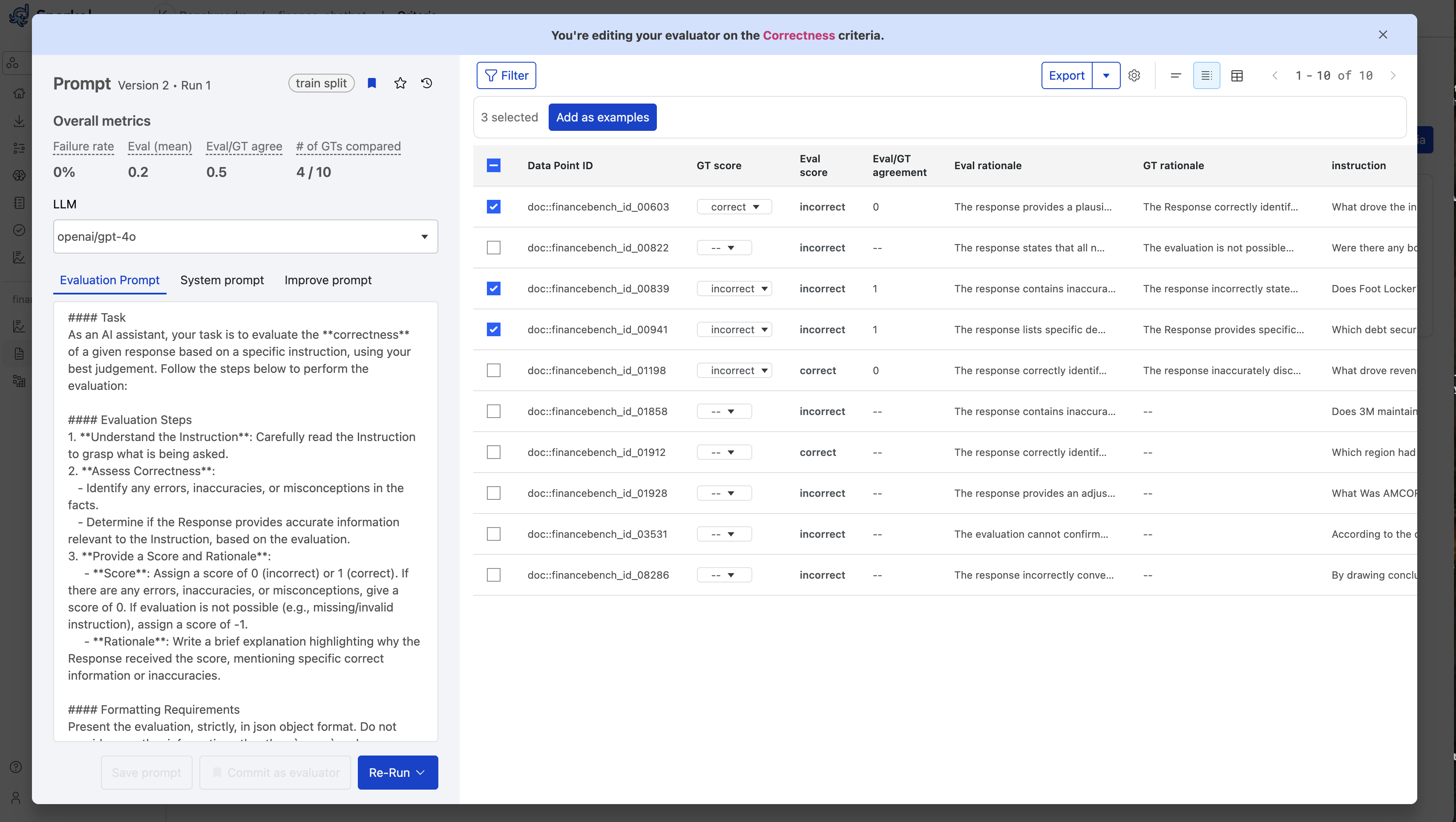
-
Select all the datapoints you want to add as examples.
-
Select Add as examples at the top of the table.
-
Select Save prompt after you are satisfied with the examples added.
Use automatic error analysis
One powerful way to refine your LLMAJ prompt is to identify where your automated judge disagrees with human evaluators. These disagreement cases are valuable signals that can help you understand where your LLMAJ prompt needs improvement.
When you run an LLMAJ evaluation in Snorkel, you can compare its evaluation results with ground truth annotations from subject matter experts (SMEs).
Rather than manually reviewing each disagreement case individually, you can use Snorkel's error analysis to identify common failure modes and get targeted suggestions for prompt improvements.
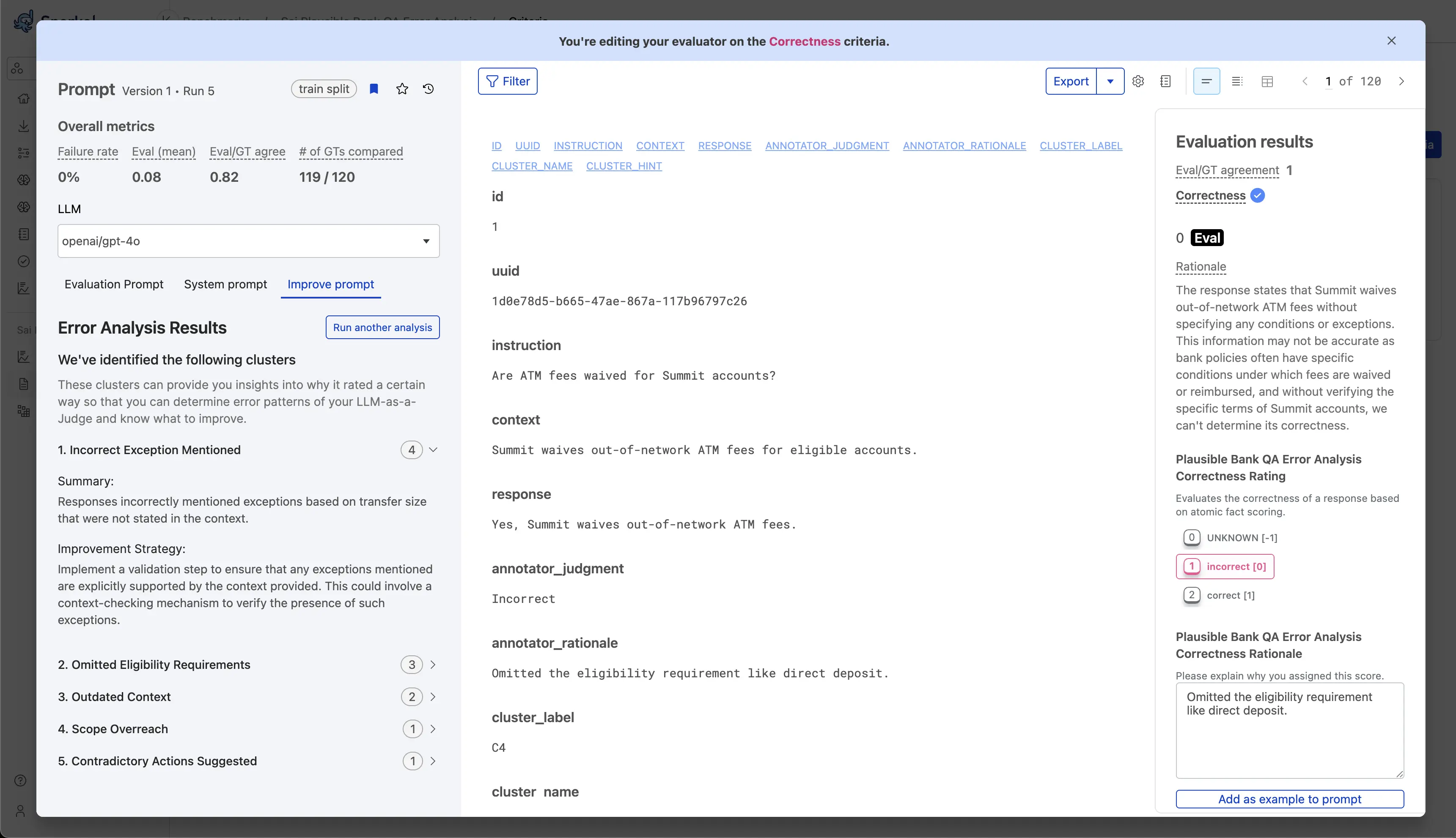
Error analysis automatically identifies patterns in the cases where annotators disagree with the LLMAJ, and gives specific suggestions to improve your prompt. This approach groups disagreement cases into actionable clusters, allowing you to make targeted prompt improvements that address the most impactful alignment problems.
Prerequisites
Before using error analysis, ensure you have:
- LLMAJ evaluation results: You must have run your LLMAJ prompt to generate evaluator scores.
- Ground truth with rationales: SME annotations that include both scores and explanatory rationales.
- Disagreement cases: At least one case where LLMAJ scores differed from ground truth scores.
Missing ground truth with rationales? See collecting ground truth to create annotation batches with rationales enabled.
How error analysis works
Error analysis uses the following algorithm to find and cluster datapoints with common evaluation disagreements:
- Identify disagreement cases where the LLM label ≠ ground truth label for a given criteria.
- Filter disagreement cases to where the annotator provided a rationale.
- Cluster these cases using an LLM to identify similar error patterns provided in the annotator rationales.
- Surface gaps in the LLMAJ prompt and guide prompt improvements to increase alignment.
How to use error analysis
Step 1: Navigate to your criteria
- From the Benchmarks page, select your benchmark.
- Select the Criteria tab from the left navigation menu.
- Choose the criteria you want to improve.
Step 2: Access error analysis
-
Select the Improve Prompt tab within your chosen criteria.
-
If prerequisites are satisfied, you'll see a Start analysis button.
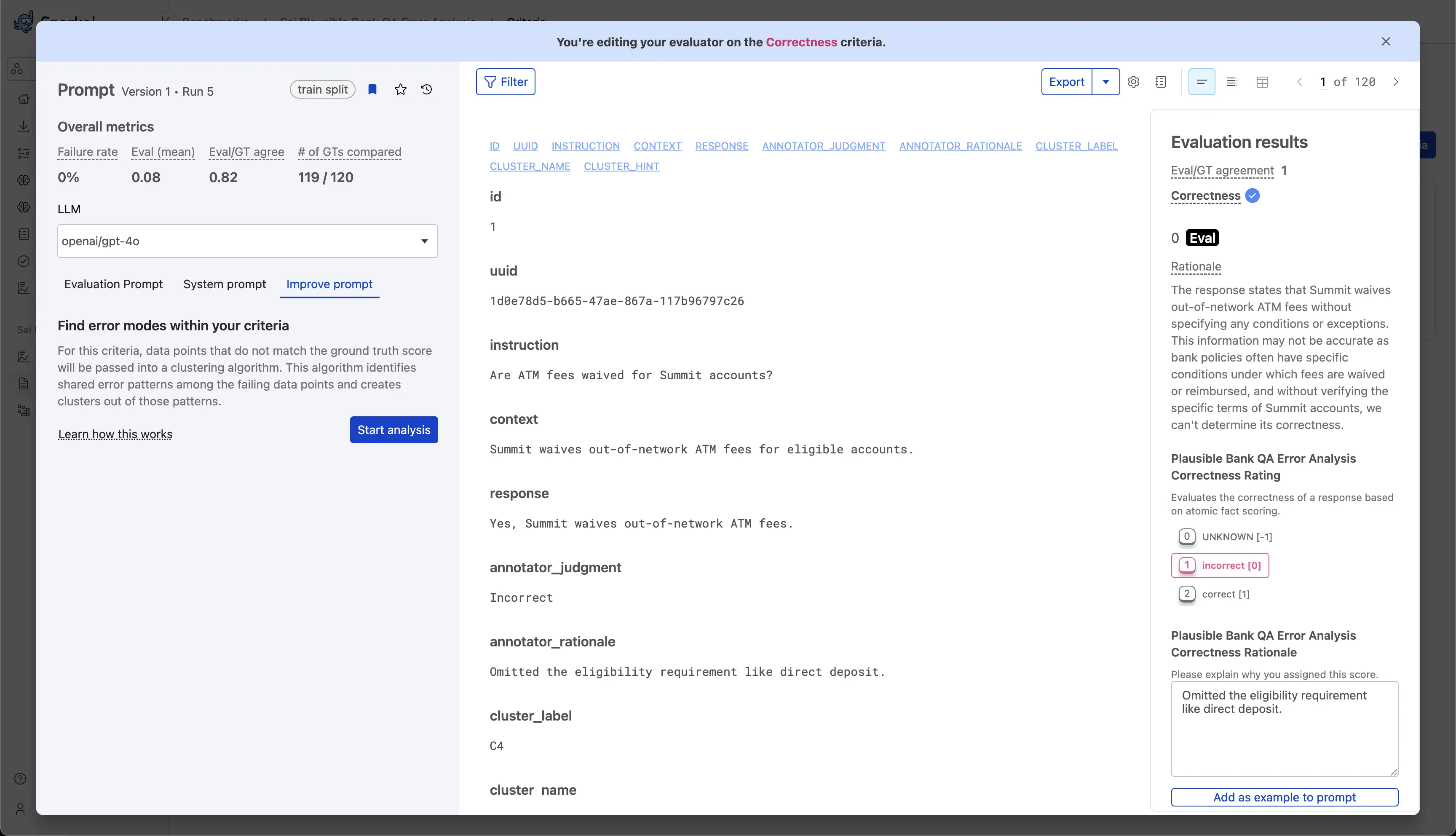
If the Start analysis button is not visible, verify that you have LLMAJ results, ground truth annotations with rationales, and disagreement cases.
Step 3: Run the analysis
-
Select Start analysis to start the clustering process. This typically takes 2-5 minutes.
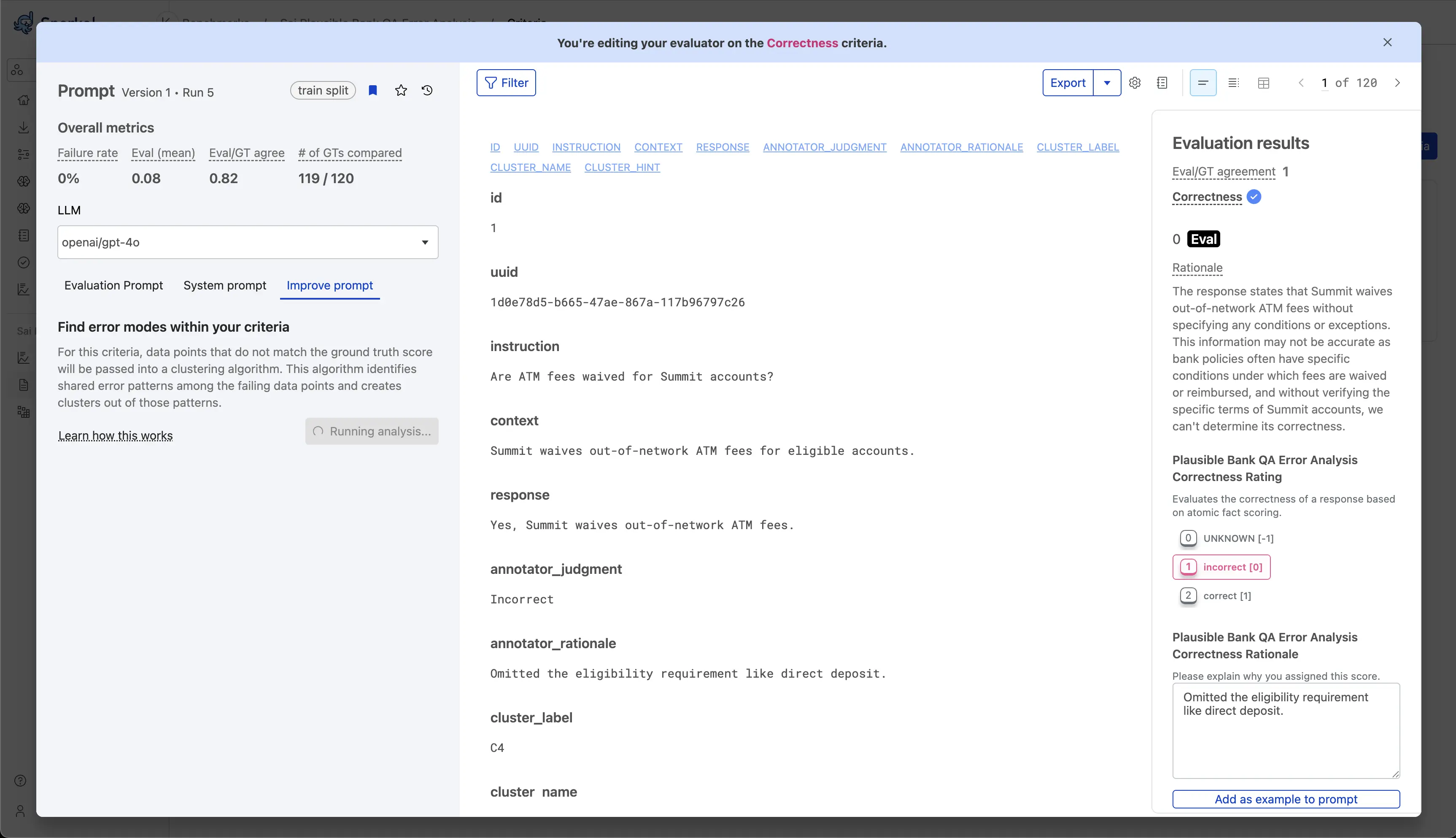
Step 4: Review clusters and suggestions
Once complete, you'll see:
-
A list of error clusters with commonly identified failure modes.
-
Each error type includes:
- A description of the error pattern.
- The number of affected cases.
- Improvement suggestions specific to that error pattern.
Step 5: Apply improvements and iterate
- Modify your prompt based on the improvement suggestions for high-frequency error clusters.
- Run your updated prompt on the same dataset.
- Rerun error analysis to see if previous error clusters have been resolved and to measure alignment improvement.
Step 6: Rerun when needed
You can rerun error analysis in two scenarios:
- After a new prompt run: Select Start analysis again to see if improvements resolved error patterns.
- After updating ground truth: Select Run another analysis to refresh the error analysis with additional annotations (without changing your prompt).
Continue using error analysis to improve your LLMAJ prompts until you achieve acceptable alignment between your LLMAJ and human evaluators.
Next steps
Once you've improved your LLMAJ alignment:
- Run your benchmark with confidence in your evaluators.