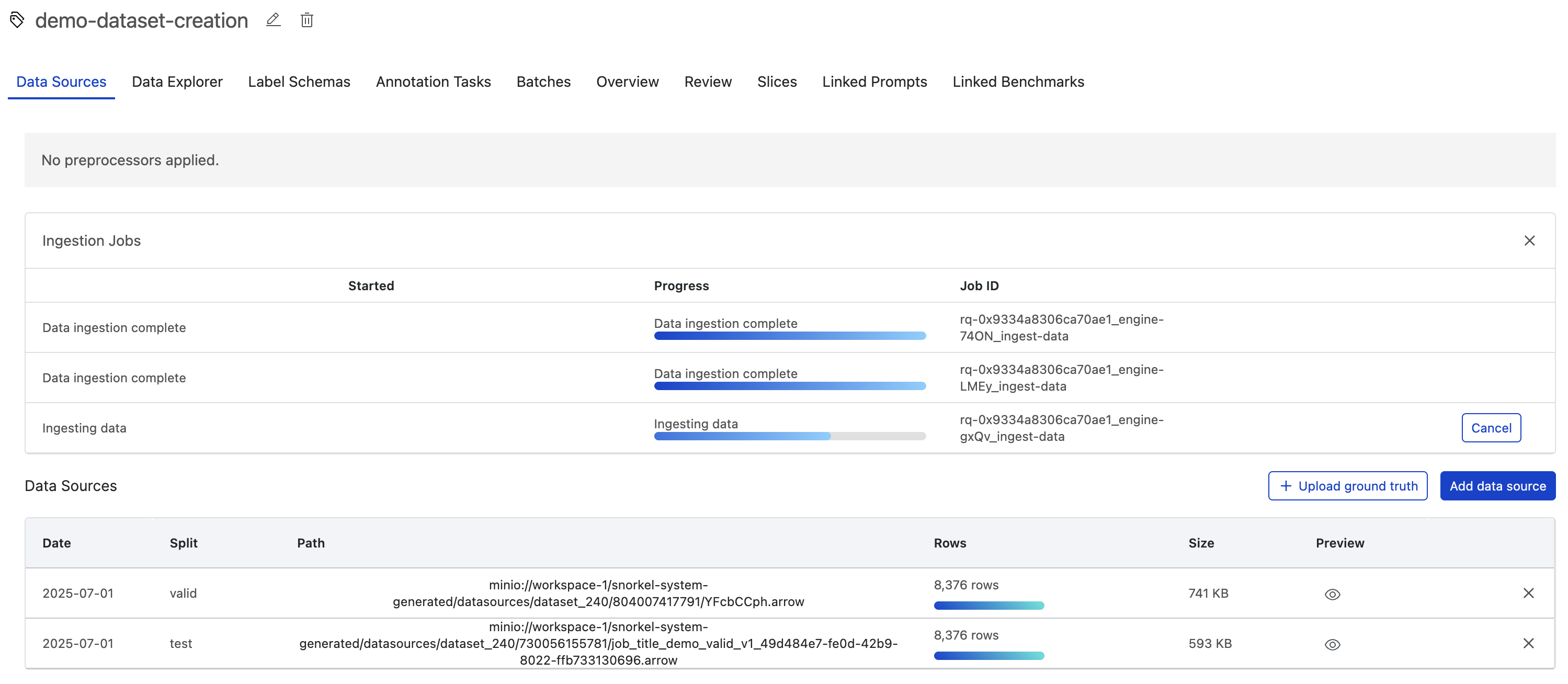
Uploading a dataset
The Snorkel AI Data Development Platform organizes data into data sources and datasets:
- Data sources are individual partitions of data points, such as the rows of an individual parquet file or resulting rows from an individual SQL query. Each data source is assigned to exactly one split (train, valid, or test).
- Datasets are collections of data sources, with each data source assigned to a specific split (train, valid, or test) within the dataset.
You can upload datasets to the Snorkel AI Data Development Platform, starting with a single data source. Data sources can be added to datasets at any time.
Prerequisite
Before uploading your dataset to the Snorkel AI Data Development Platform, prepare your data to minimize any unexpected data processing issues when managing your applications.
To upload a dataset
-
Select the Datasets option in the left navigation, and then select Upload new dataset in the top right corner.
-
For the New dataset, enter a Dataset name. Select Next.
-
Select you Data source from the dropdown menu. Learn more about supported data source types.
-
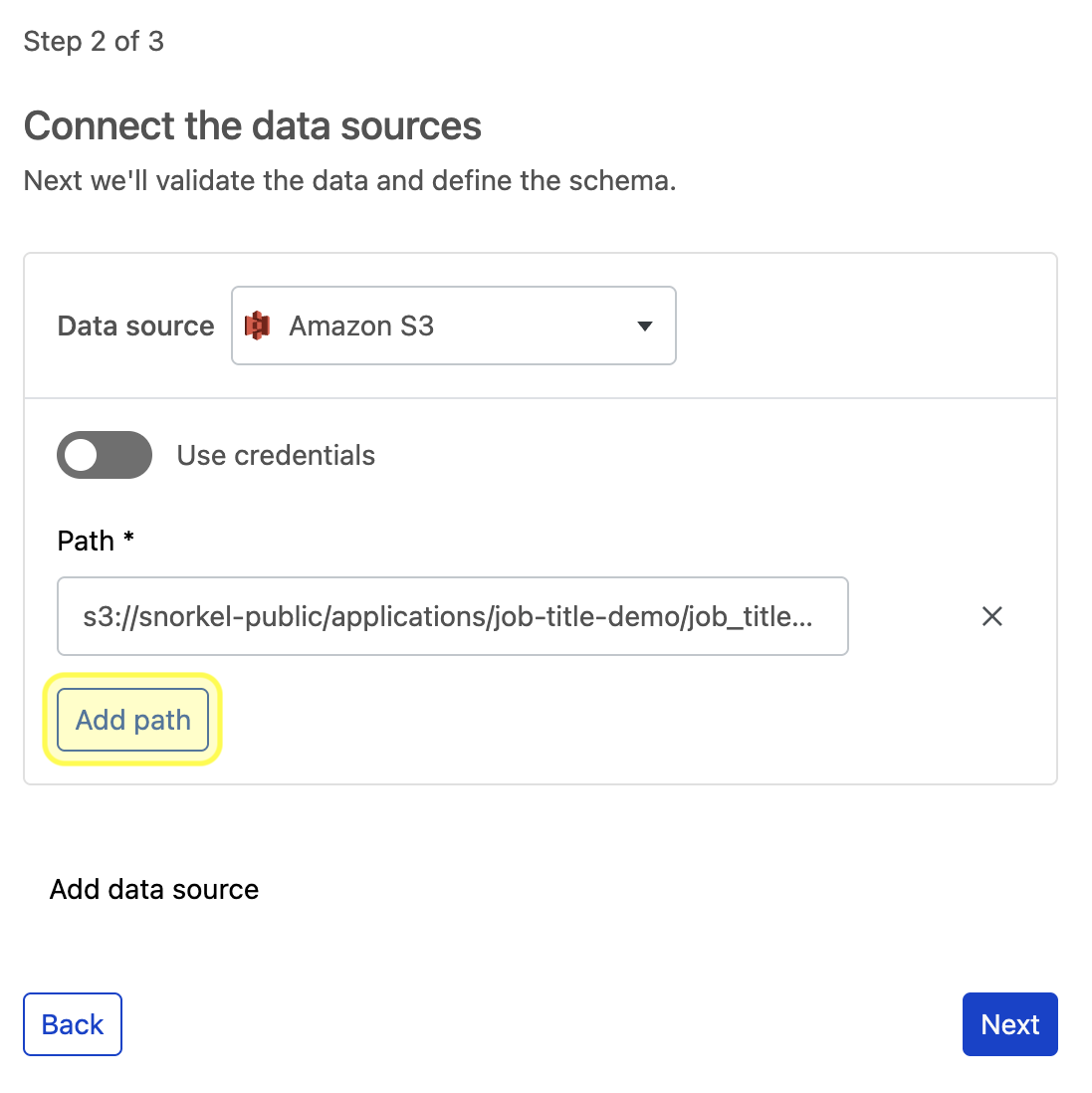
Put in the path or query for the chosen data source. To ingest multiple paths or queries for that data source, select Add path or Add query, based on your chosen data source type.
a. Alternatively, you can also use credentials to ingest data from private data sources. This is mandatory for some data source types, such as Databricks and Snowflake. This is optional for other sources, such as S3 buckets, which may be public or private.
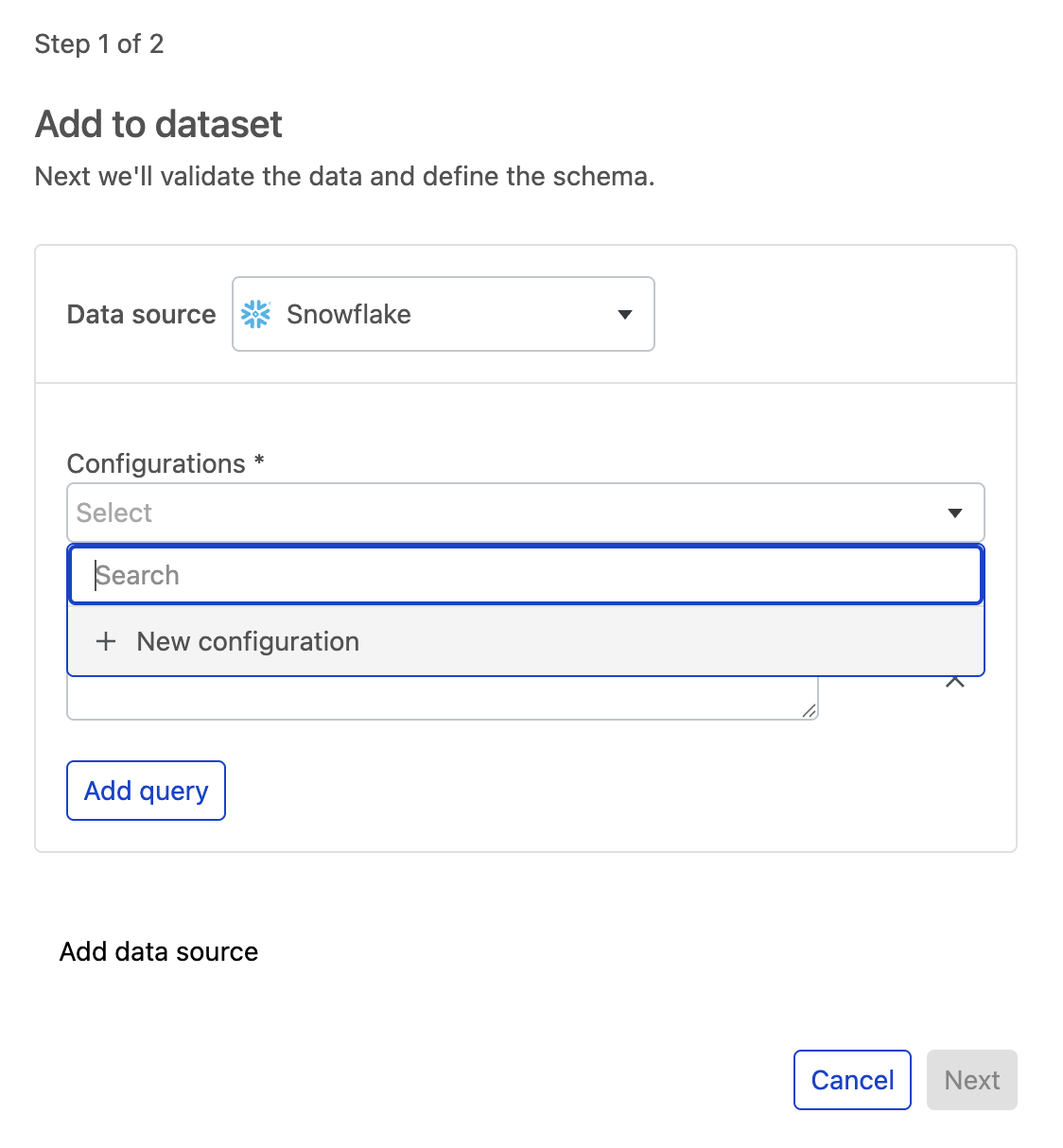
b. To ingest from a private S3 bucket, toggle on Use credentials and select + New credential.
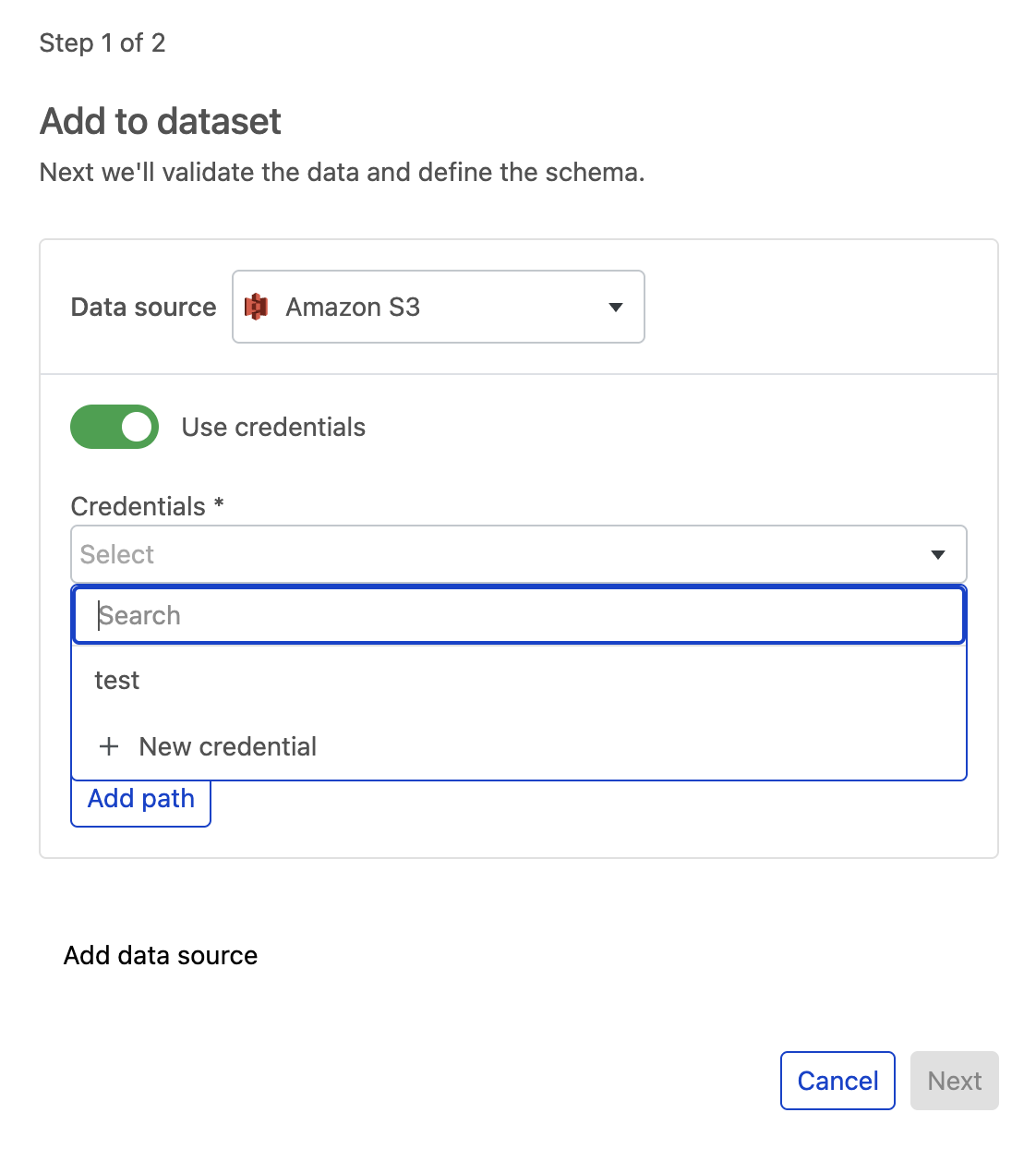
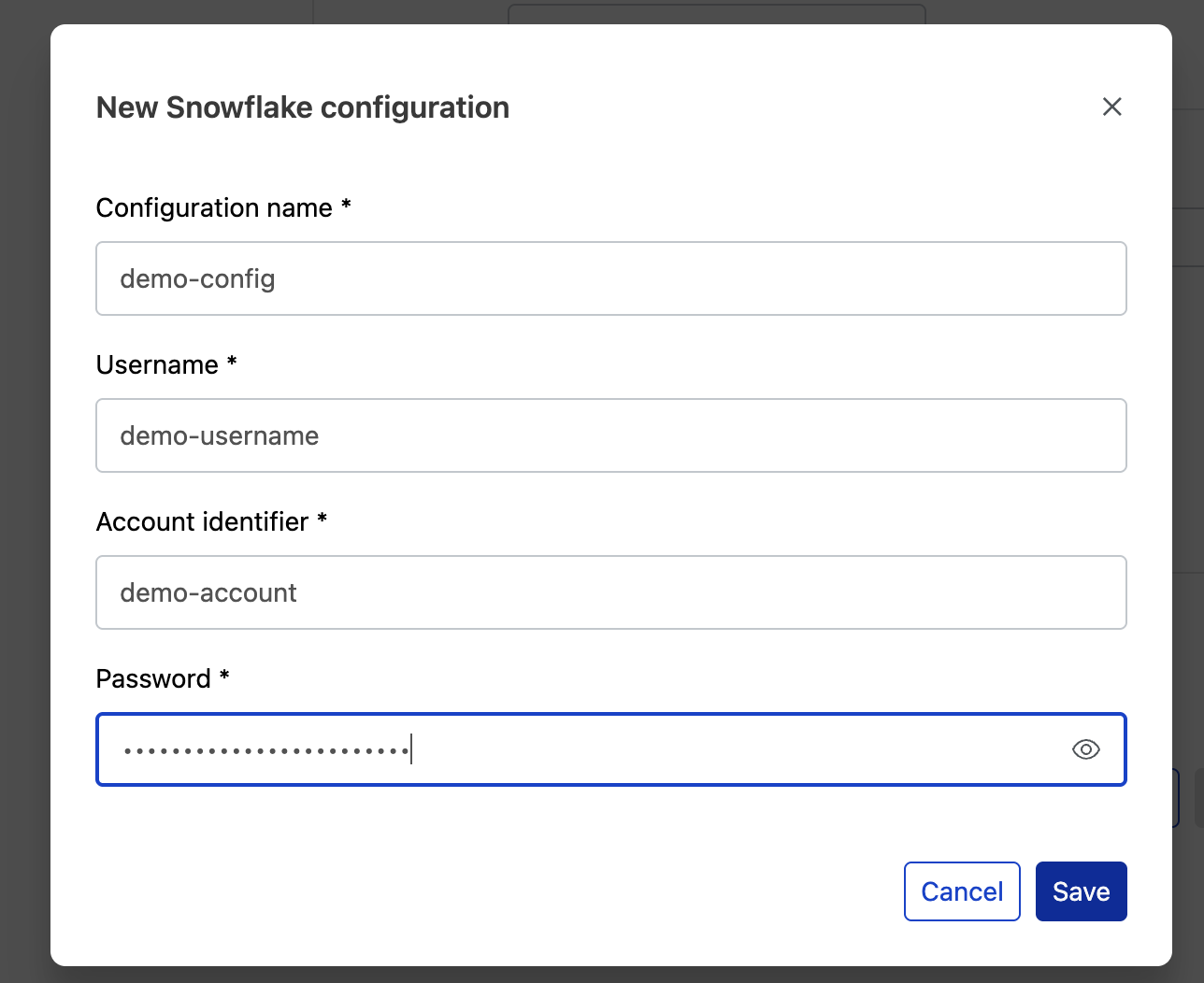
In the module, add your credentials and select Save.
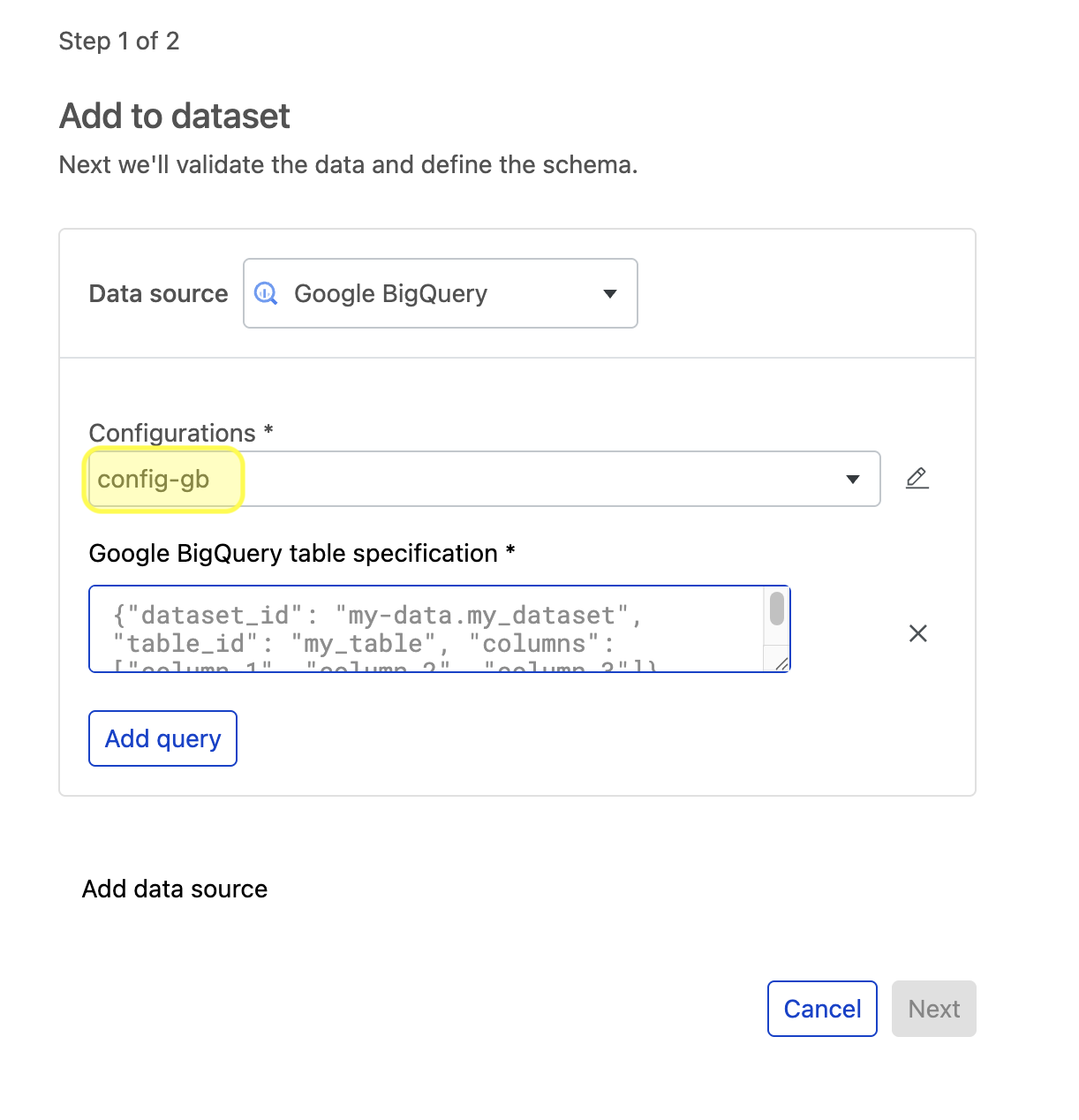
Select your saved configuration from the dropdown menu and enter your path or query to ingest data from the new configuration.
-
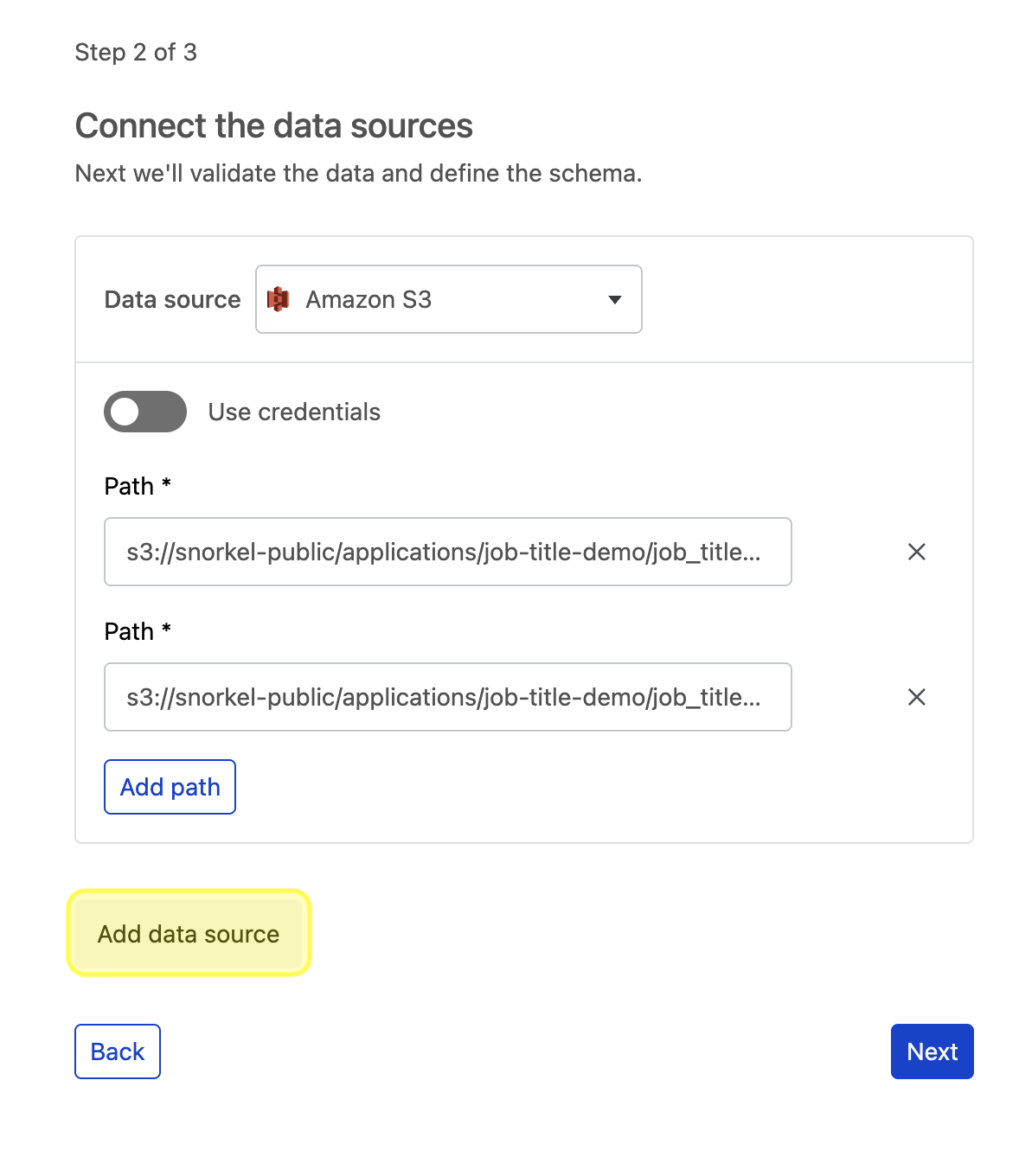
To add multiple data sources with one or more paths or queries under each, select Add data source.
-
Repeat these steps for each data source, and then select Next to verify your data sources. This step verifies that your data sources are accessible and runs basic checks, such as detecting
NaNvalues, to ensure your data is valid for ingestion.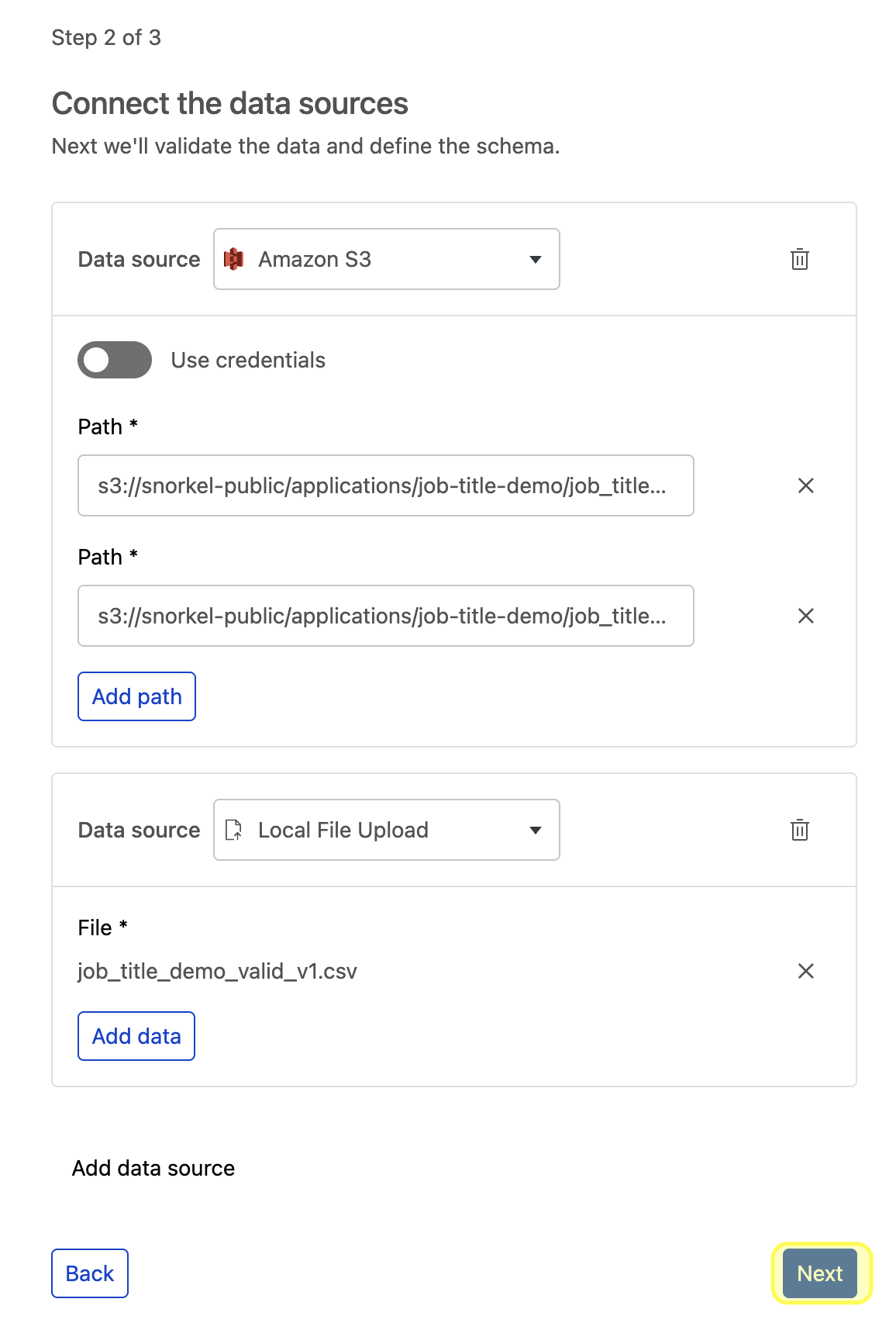
-
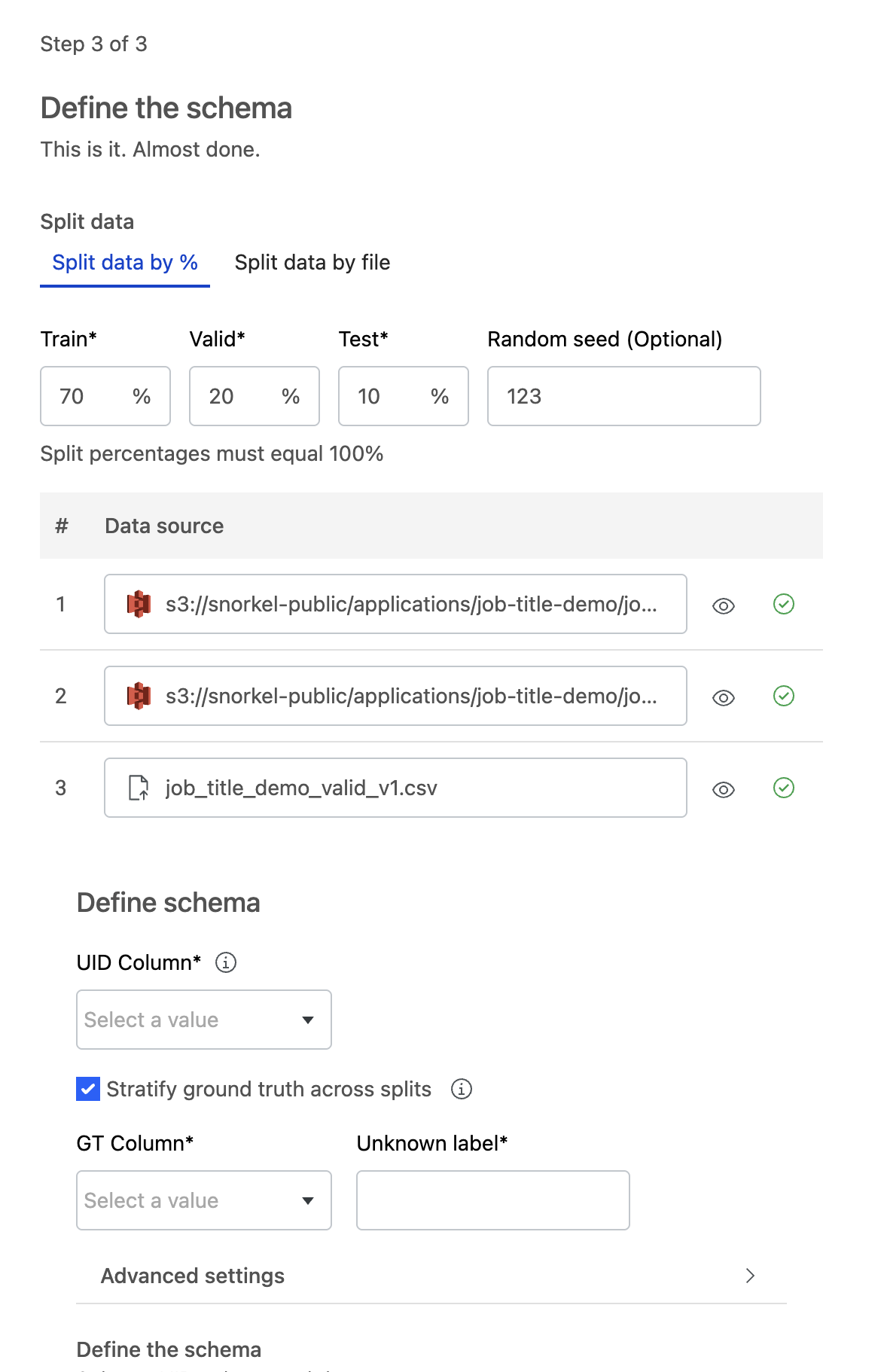
Assign splits to data sources. There are multiple ways to assign splits to data sources:
-
Automatically with the Split data by % option. If you select this option, then you need to define your ground truth (GT) column.
 tip
tipIf you have a large amount of unlabeled data, split your training data into smaller data sources. You can enable a subset of data sources for faster initial development before scaling up to all of your data.
-
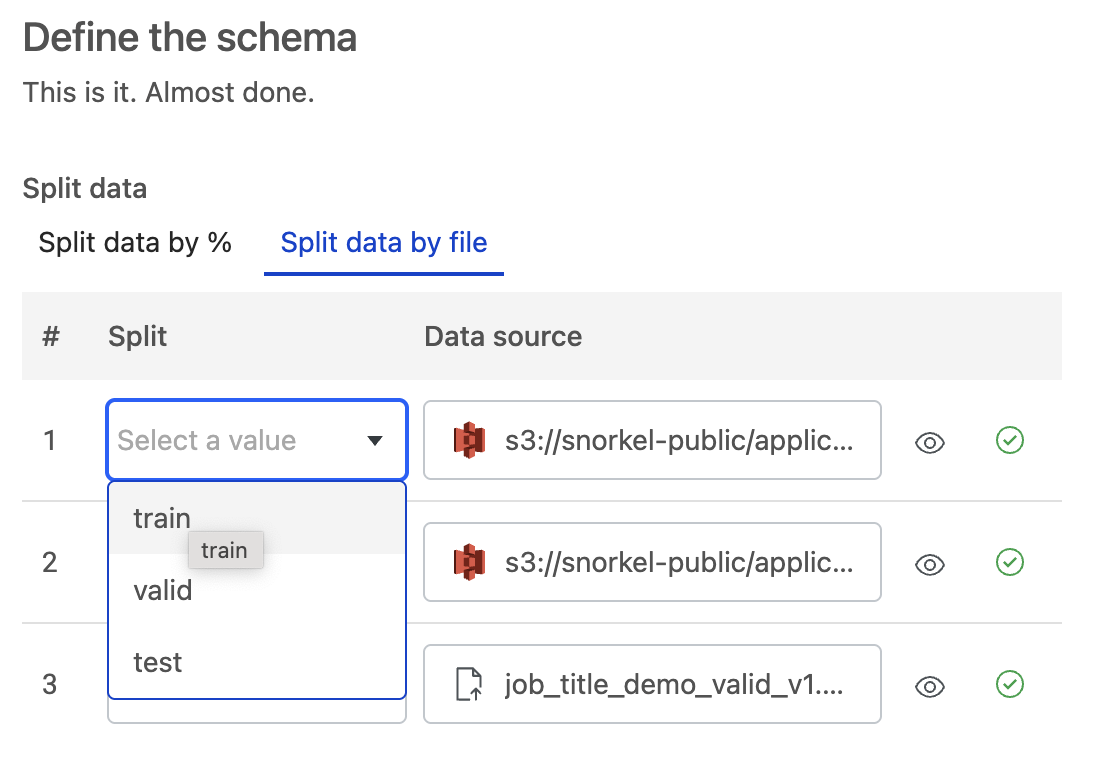
Manually with the Split data by file option.
-
-
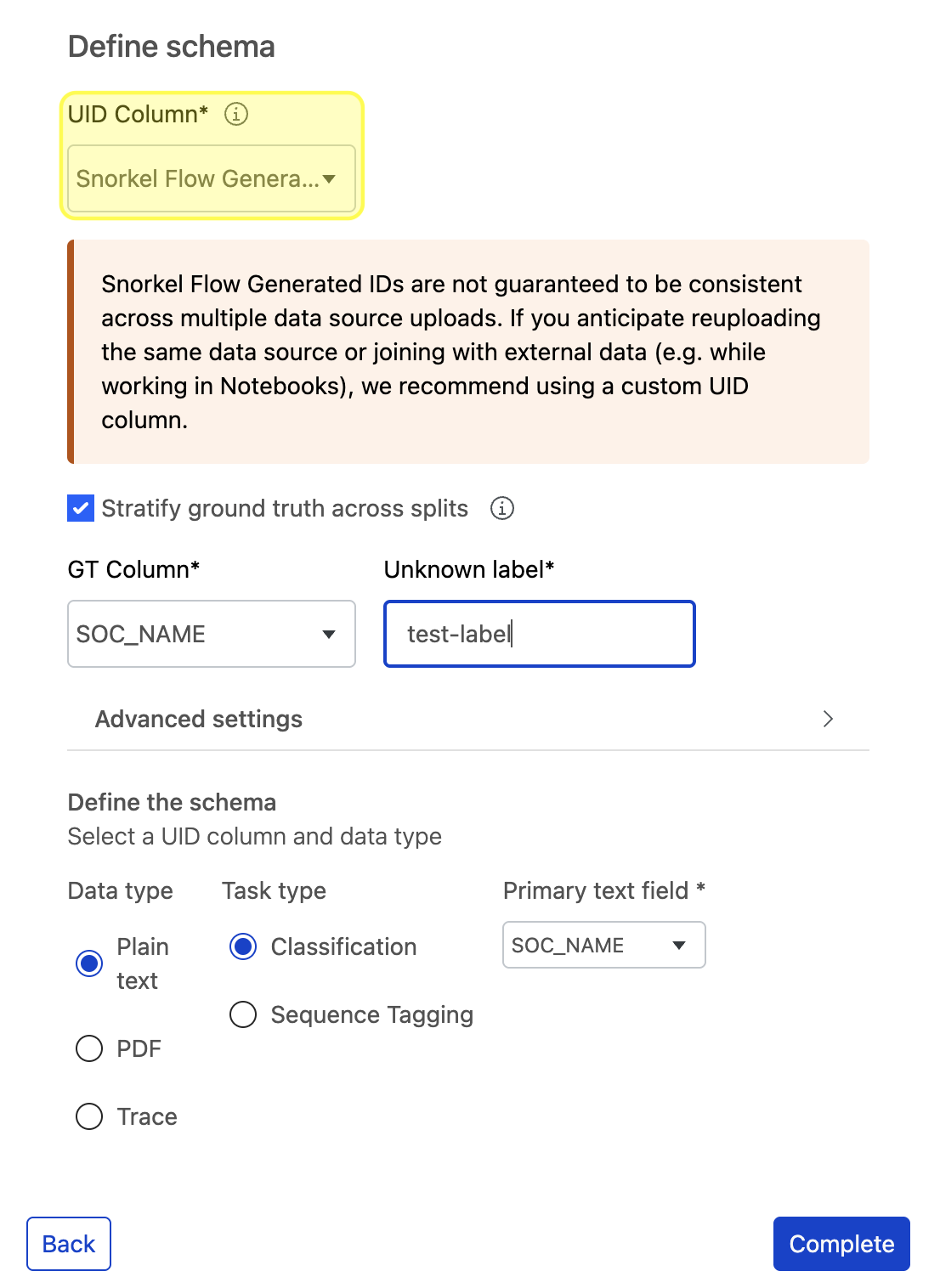
Once all of your data sources are verified, choose a UID column that is unique for each row across the dataset. This UID column can be text or an integer. If your dataset does not have that type of field, then choose Snorkel Generated to have the Snorkel AI Data Development Platform generate a UID column.
Once the dataset is created, a new
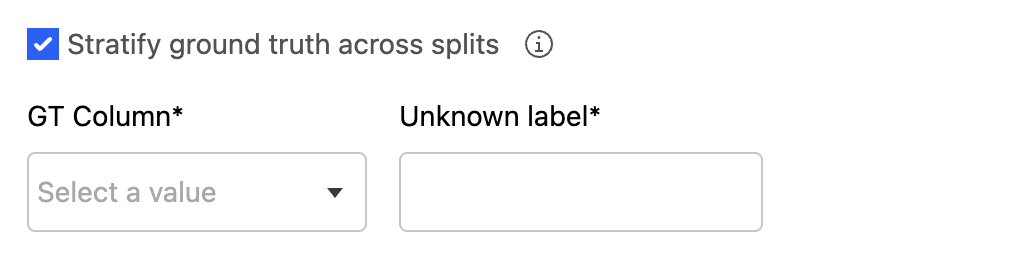
context_uidcolumn is added to your data. This column is populated with the selected UID column or the Snorkel Generated UID.a. If you chose to automatically split your data with the Split data by % option, you can Stratify ground truth across splits to ensure the ground truth labels are evenly distributed across the splits.
- If you opt in to stratify ground truth, provide the GT column and the value corresponding to UNKNOWN ground truth.
- If you opt out, the data is split randomly.
b. Fill in the data type for the task.
-
Select Complete to begin ingesting your data into the platform.