Using multi-schema annotations
This article explains how to use multi-schema annotations, including uploading a multi-schema annotation dataset, annotating multiple schemas, and reviewing the annotations and progress.
Multi-schema annotations empowers subject matter experts to work more efficiently. This feature lets you collect annotations across multiple schemas at one time, unlocking complex workflows. With multi-schema annotations, datasets become the new home for all of your annotations and ground truth (GT). The GT is stored in a label schema for a dataset, which can be used by all of the downstream model nodes.
By default, all text-only datasets are multi-schema annotations. Multi-schema annotations are not supported for PDF or image datasets.
Upload a multi-schema annotation dataset
- To create a new dataset, select Datasets > Upload new dataset.
- Enter the required information for creating your dataset. For more, see Uploading a dataset.
- Select Verify data source(s).
- Select UID column, data type, task type and primary field within Define Schema section.
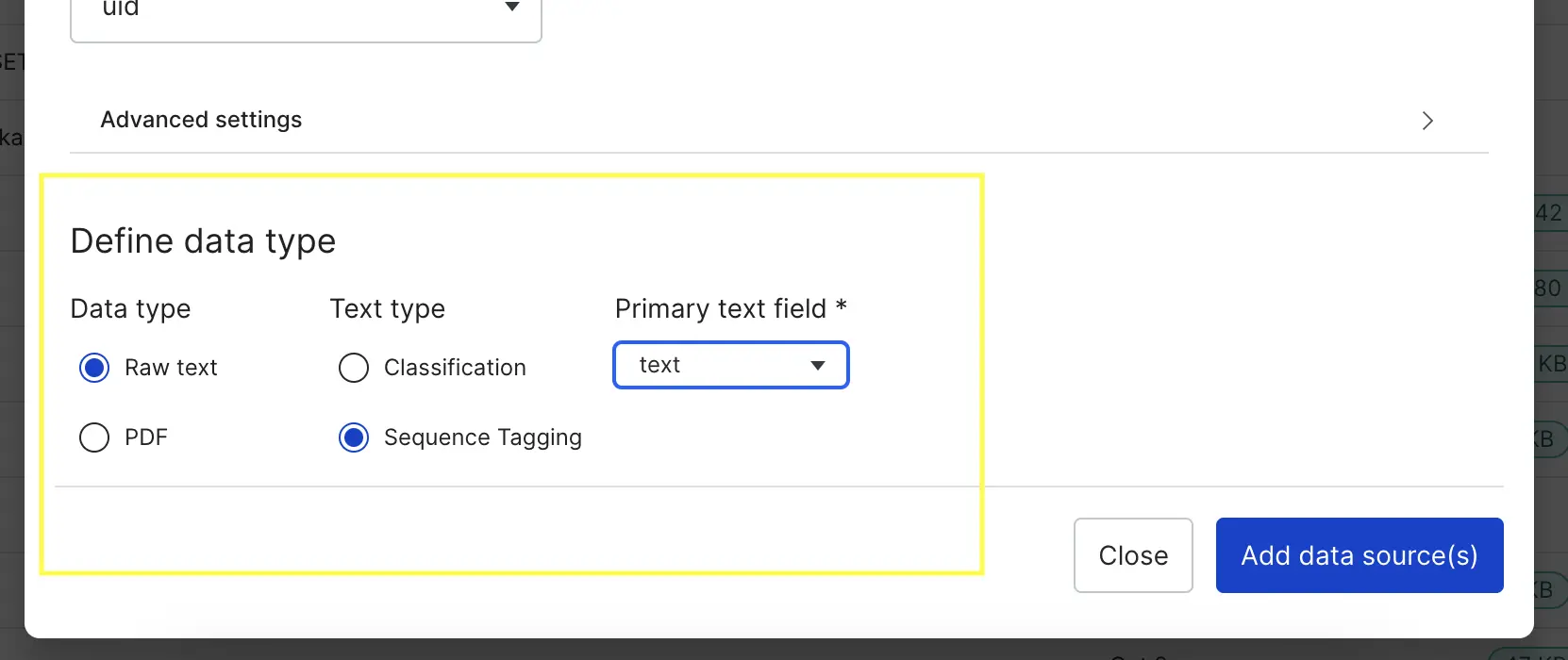 Based on the data type you select, the options for task type and
Based on the data type you select, the options for task type andprimary field may change. For supported data types, we'll automatically pre-process your data to make it easier for you to work with during annotation. :::
- Once the data sources are uploaded, you'll see the applied pre-processors in the Data sources tab.
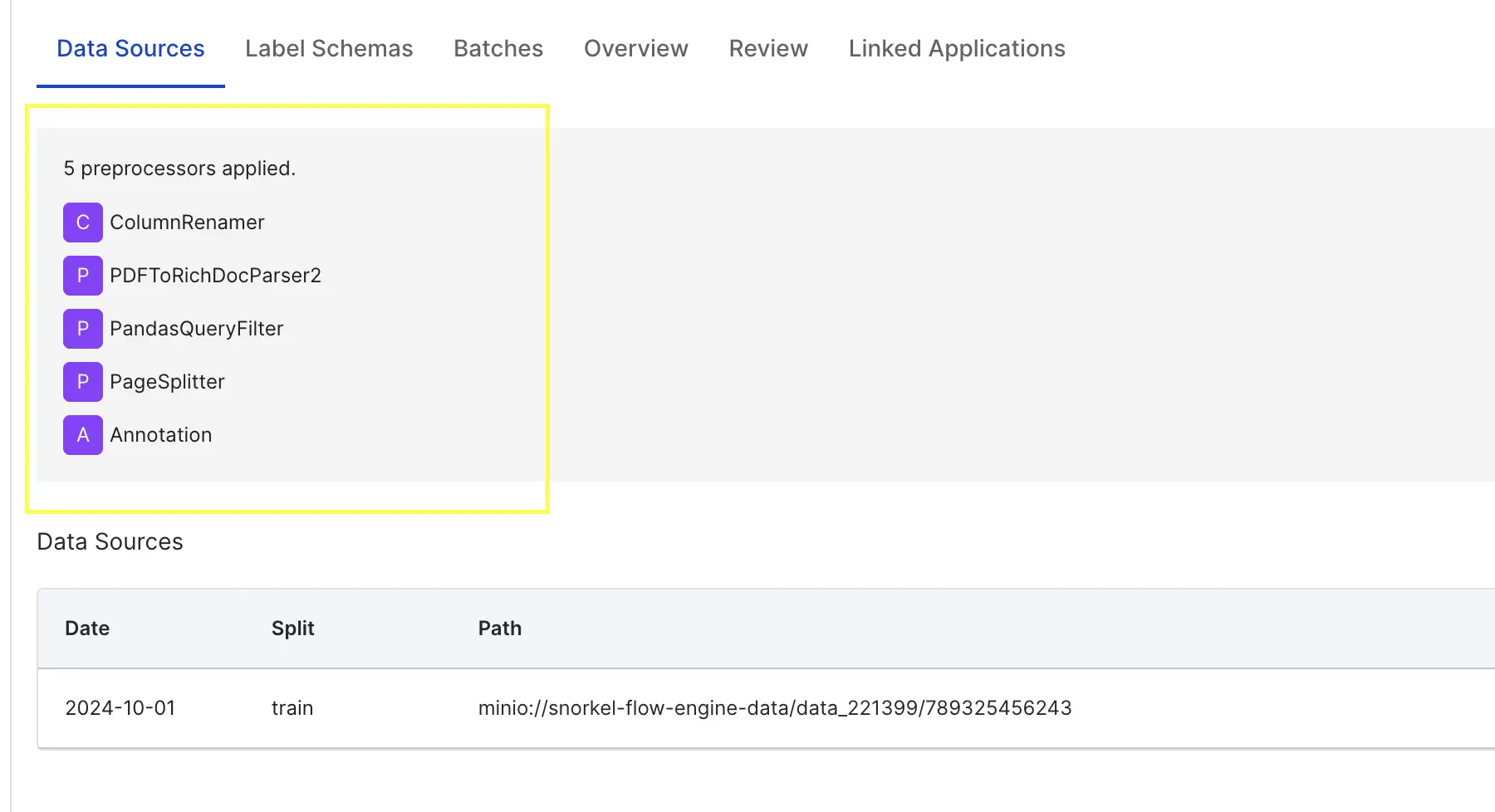
- Within Datasets > "your dataset name" > Label Schemas, select + Create new label schema.
- Enter a name, description, data type, task type, and additional fields for each task type.
- Classification tasks:
- Select Classification as the Task type.
- Select Text as the Primary text field.
- Select Single label, Multi-label, or Text label. Text label allows for free text in your labels instead of a defined label or labels for the other options.
- Extraction tasks:
- Select Extraction as the Task type.
- Select Sequence tagging.
- Select the main text field as the Primary text field.
- Define your IOU Agreement Threshold, which is the percentage of words that overlap to count as an agreement in the IAA matrix.
- For Label type, select Single label for spans that cannot overlap or Overlapping (annotation-only) for spans that can overlap.
- Select Add new label to define new label options along with a description.
- Classification tasks:
- Select + Add label schema.
- In Batches, select + Create new batch.
- Enter the batch name.
- Select your split and your label schema.
- Enter your batch numbers and batch sizes.
- (Optional) Assign users to annotate the batch.
- Select Create batch.
Annotate multiple schemas
The Snorkel AI Data Development Platform applies annotations to the data points across any batch in which the annotations are used.
- In the Batches tab, select Annotate beside the batch you want to annotate.
- Select the labels that apply to the data point.
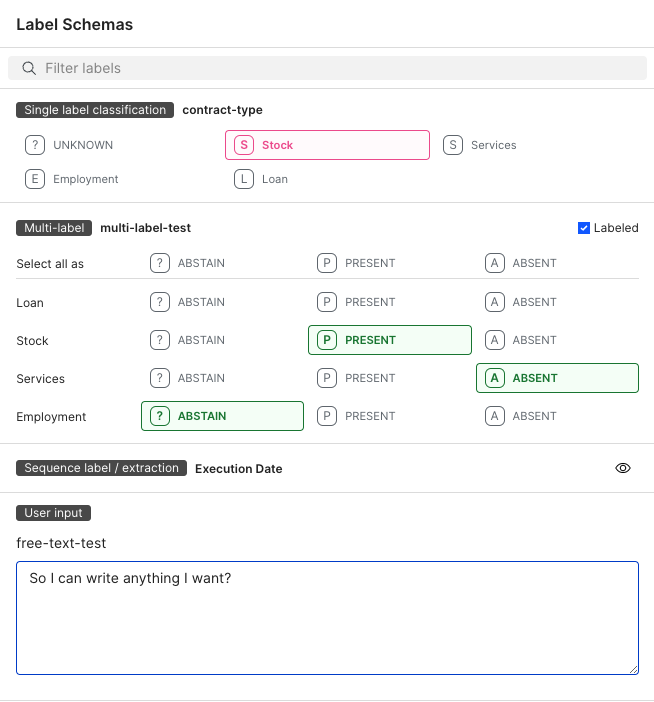
- Select the previous and next arrows to move between data points.
- Continue annotating each data point until you have completed your annotations.
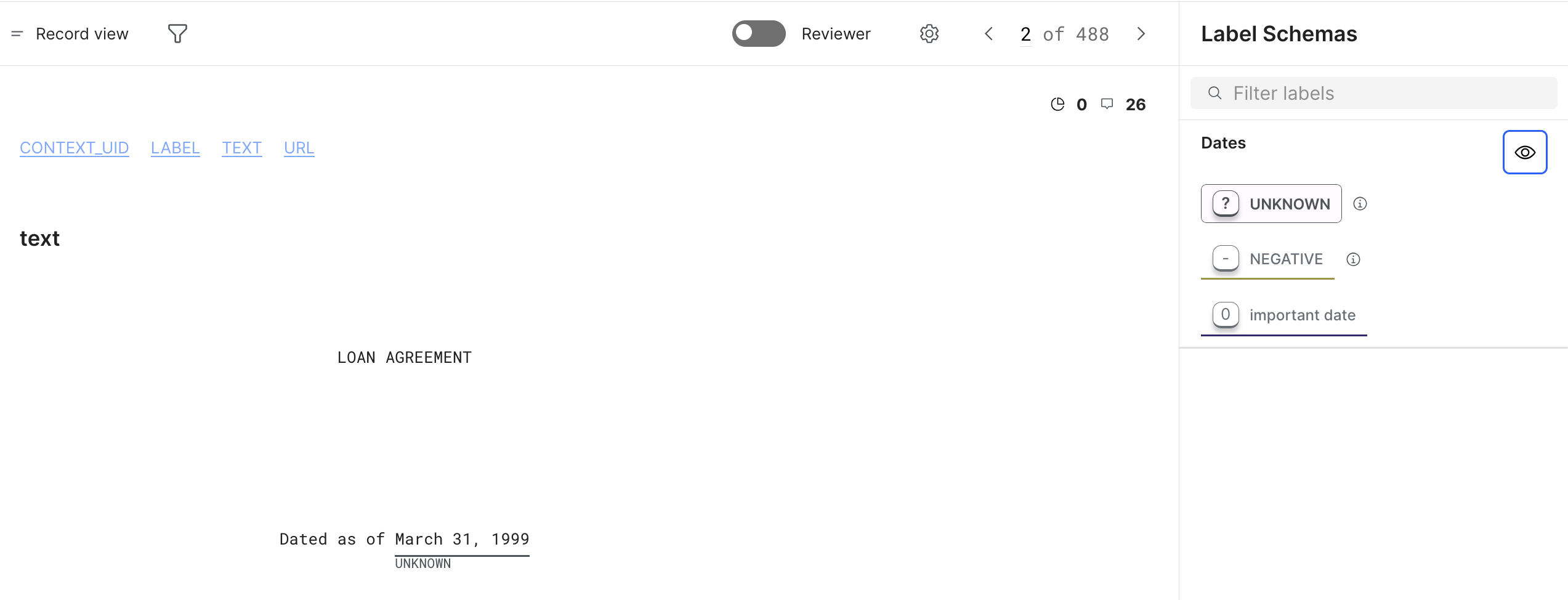
Annotate sequence tagging
The Snorkel AI Data Development Platform supports sequence tagging for extraction tasks. Spans are key pieces of information that you want to extract from a document. To label spans in the document, you can highlight a section of text and select the span label from the pop-up menu.
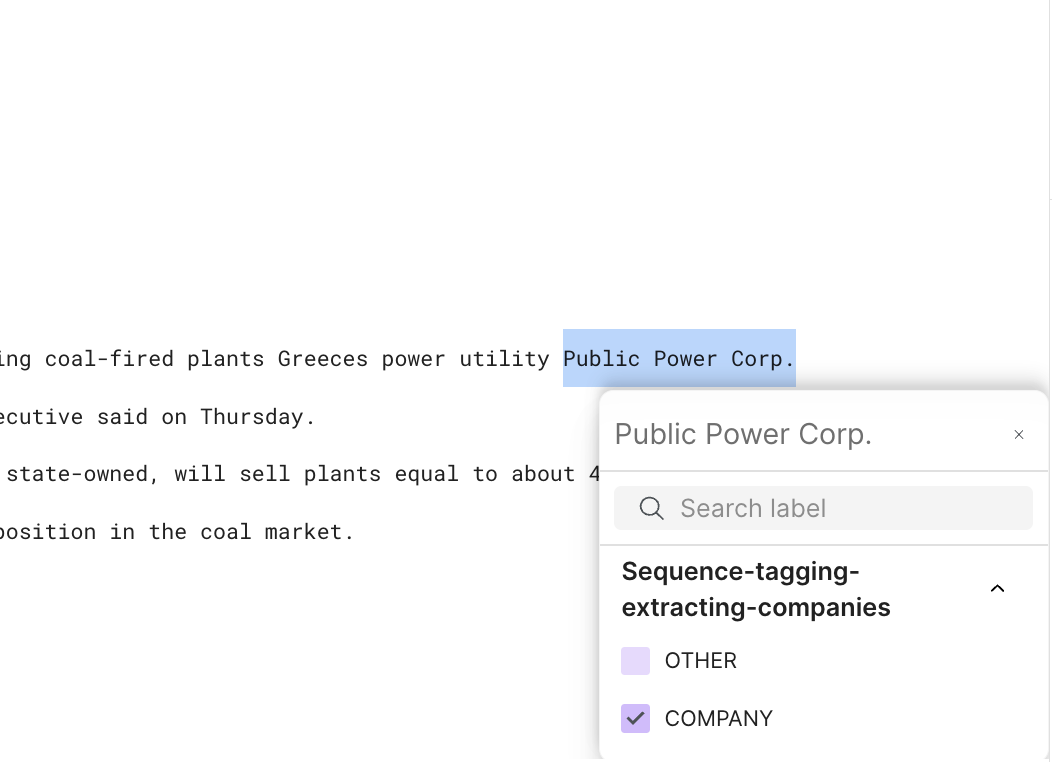
If you want to apply the same label to a series of spans, first select the label from the right-side menu, and then highlight all of relevant the text segments in the document.
If you selected Single label during the label schema creation process, the spans cannot overlap. If you select Overlapping (annotation-only), you can use overlapping spans.

Annotate candidate extraction
Similar to sequence tagging, candidate extraction (CE) involves annotating spans in the text. The key difference is that CE schemas are pre-defined based on an extractor, such as a regex. To label these spans, click on a highlighted schema and use the sidebar to choose the label.
You can also use keyboard shortcuts to navigate through the spans. Right and left arrows change the documents while the top and bottom arrows move through the spans within a document. Keyboard shortcuts corresponding to the labels in the sidebar, which can be used to label a selected span.
Review annotations
If you have Reviewer permissions, enable Reviewer mode during annotation to reconcile your team's annotations and select the specific ones to commit to ground truth.
- Enable Reviewer mode with the toggle to see all of the annotations for a dataset. You will see the annotations from each annotator.

- Hover over the circles to see which user annotated each specific class. Alternatively, use the filters for the Label Schemas to filter down to a specific label schema, conflict status, or user.
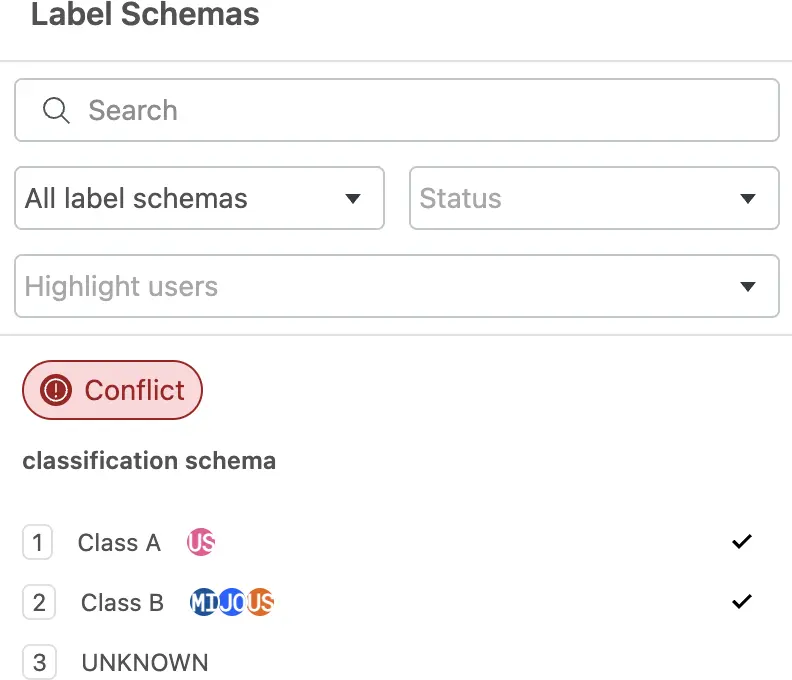
- If there are conflicts, resolve them by clicking the checkmark next to the correct class.

- Once all the conflicts have been resolved, select the Commit button to commit the selected annotations to ground truth for this data point.
Commit annotations in bulk
Alternatively, you can commit the annotations in bulk:
- Select Datasets in the left navigation.
- Select a dataset.
- Select the Batches tab.
- Expand a batch.
- Select an annotator or aggregated source.
- Select Commit.
- Note that when you make a ground truth commit, it overwrites any existing ground truth in your dataset.
- Reviewer mode doesn't support committing ground truth for multi-label classification and text label schemas. Use this batch workflow instead.
Configure your annotation display
- In the Batches tab, select Annotate beside the batch you want to annotate.
- If you want to filter the data points to annotate, select your filtering options with fields and operators.
- To change your display settings, select the gear icon. You can change the displayed columns, column order, and text direction. You can also prioritize unlabeled documents and set a default multi-label class.
View annotation progress
In the Overview, you can select your Label schema from the dropdown menu to see the current status and how much each annotator has finished.
You can select filters for Annotator progress to see the progress for specific annotators.
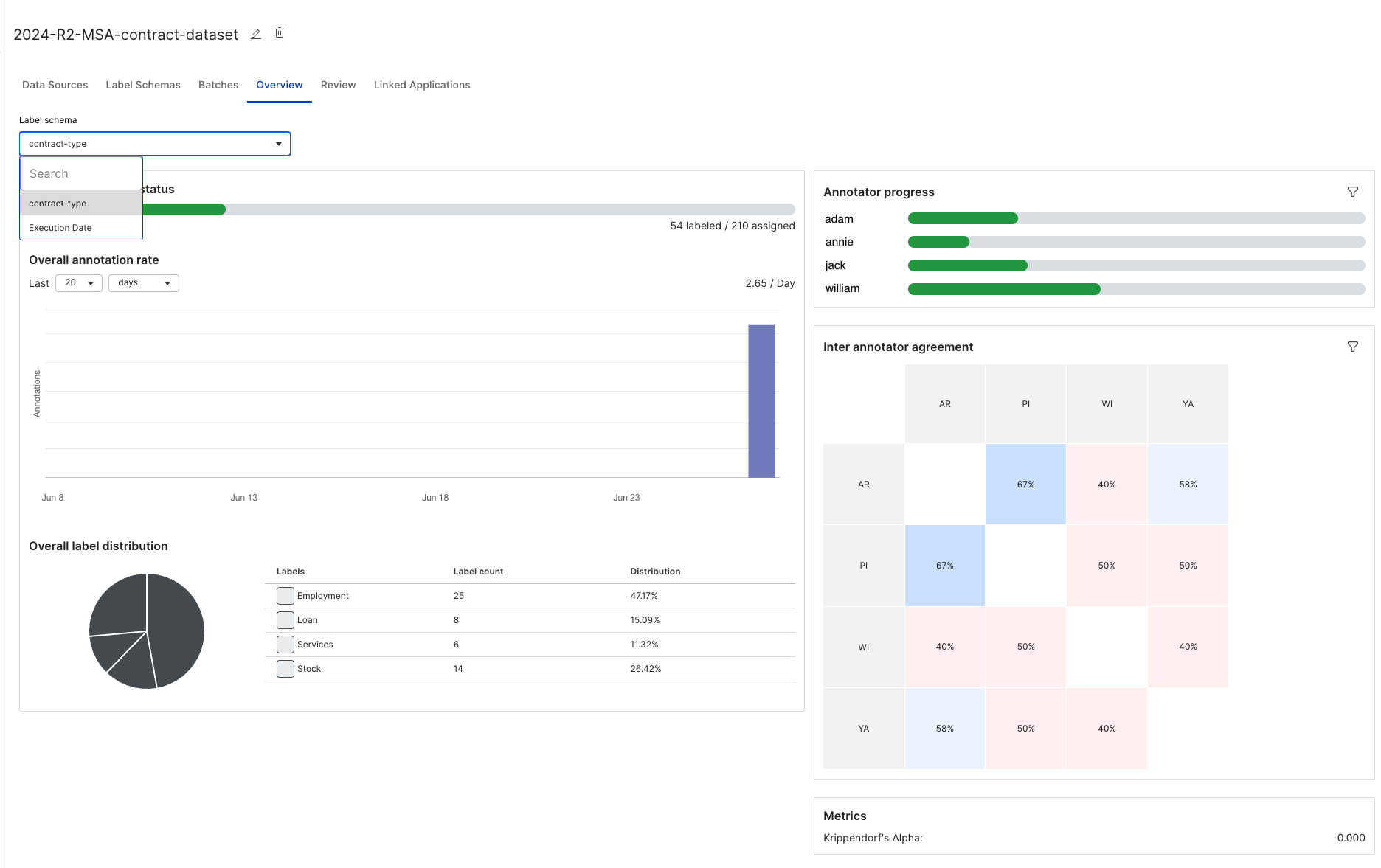
You can also see the Inter annotator agreement, which represents how often annotators agree with each other. For sequence tagging label schemas, agreement is defined during the label schema creation process, where the IOU Agreement Threshold defines what percentage of words have to overlap to count as an agreement in the IAA matrix. This defaults to 100%.
In the Review tab, you can see that annotators, annotations, and batches.