Sequence tagging: Extracting companies in financial news articles
We will demonstrate how to use Snorkel Flow to extract mentions of companies in financial news articles with state-of-the-art sequence tagging technology. In this tutorial, you will learn:
- How to create a sequence tagging application
- How to write labeling functions for sequence tagging application
Known limitations with sequence tagging
The following items are known limitations and are planned to be added in future releases.
- Active learning.
- Reviewer workflows in Annotation Studio.
- Labeling function conflict in Studio data viewer filters.
- Margin distance filter.
- Advanced filters (composing with "OR," "ALL/ANY LF Voted")
- Sequence Keyword LF supports at most ten keywords.
- Sequence Fuzzy Keyword LF and Sequence Word Vector LF support at most three keywords.
- Custom metrics.
Create a dataset
First, we will create a dataset named company-dataset by clicking on the Upload new dataset button in the Datasets page. Ensure that the Enable multi-schema annotations checkbox is selected. Then we will add the following data sources for each split:
- Train:
s3://snorkel-financial-news/mini_train.csv - Valid:
s3://snorkel-financial-news/mini_valid.csv
After adding these two data sources, click the Verify Data Source(s) button. Fill out the following fields:
- UID Column:
index - Data type:
Raw text - Task type:
Sequence tagging - Primary text field:
text
Finally, click the Add data source(s) button. For more information about uploading data, see Data upload.
Create an application
In Linked Applications tab, click the Create from Template button from the Create Application dropdown menu. Select Sequence tagging and Create Application. Fill out the following fields:
- Application name:
company-ner-seq-tagging - Choose default dataset:
company-dataset(created above) - Specify required input fields: Select
text,context_uid, andtitle - Ground truth column: leave as blank
- Negative label:
OTHER - Labels:
COMPANY - Seq field:
text
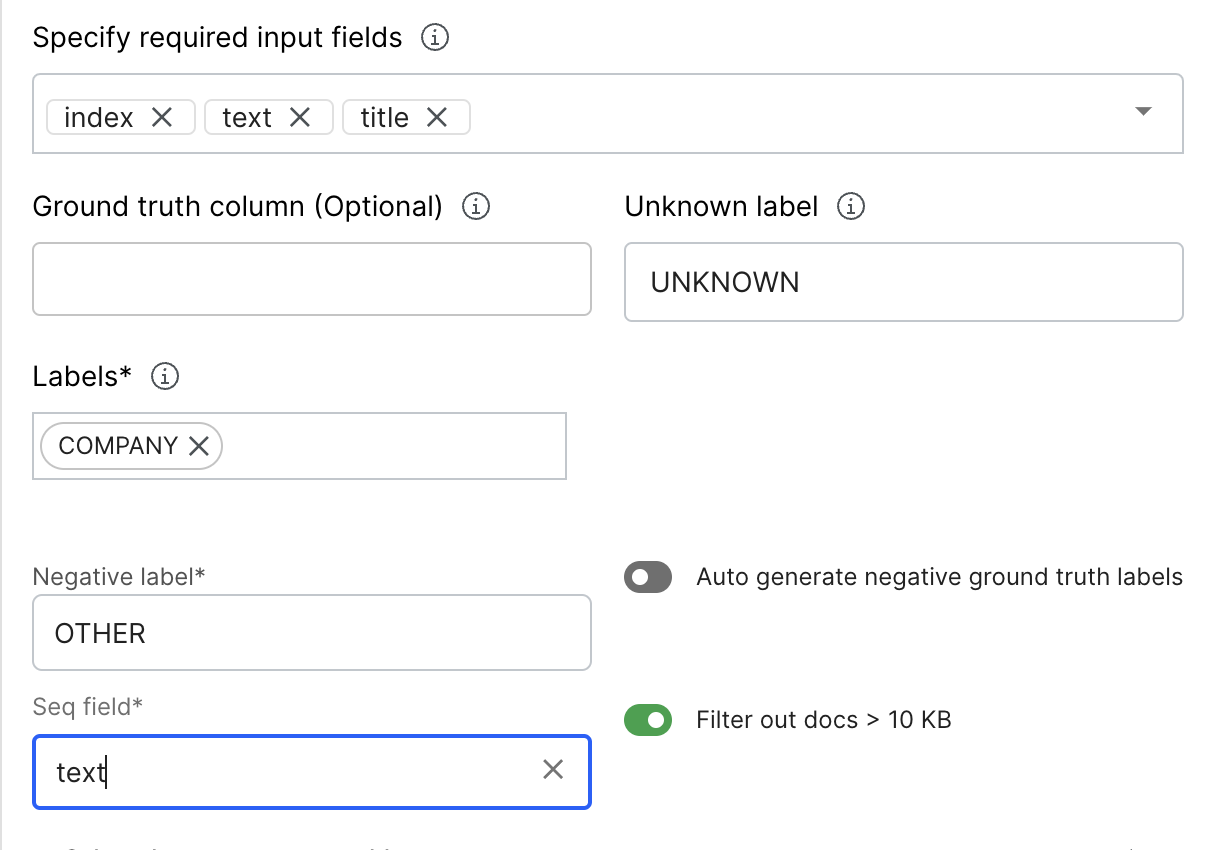
Note that the Negative Label (OTHER in this case) is equivalent to the O (non-entity tokens) in BIO notation.
Adding ground truth
Ground truth format
Here is an example ground truth file:
| __DATAPOINT_UID | start | end | label |
|---|---|---|---|
| doc::1 | 29 | 40 | COMPANY |
| doc::1 | 228 | 239 | COMPANY |
| doc::2 | 395 | 406 | COMPANY |
Spans cannot be empty (char_start must be smaller than char_end). Overlapping or duplicating spans are not allowed. Negative spans (OTHER) are automatically inferred. Refer to snorkelflow.client.add_ground_truth() for more information.
By default, two preprocessors are added in the DAG: TextSizeFilter filters out documents larger than 10 KB. AsciiCharFilter filters out the non-ascii characters from the documents. This may result in some changes in offsets when exporting ground truth out of Snorkel Flow.
Upload ground truth file
On the Overview page we get a high-level view of our application. We can also add any external ground truth labels we have on this page. On the center of the dashboard you’ll notice a Upload GT button. After clicking on it you’ll be prompted to provide the following information to import ground truth from a file:
- File path:
s3://snorkel-financial-news/aligned_mini_gts.csv - File format:
CSV
If you click on the View Data Sources button on the bottom left of the dashboard you can view the full set of data points and ground truth across splits:
| # of data points | # of GT labels | |
|---|---|---|
| train | 2000 | 78 |
| valid | 100 | 66 |
In the sequence tagging application, each document is represented as a datapoint. The # of GT labels refers to the number of documents with one or more spans annotated with GT. We can now view our data by clicking the Develop button on the top right.
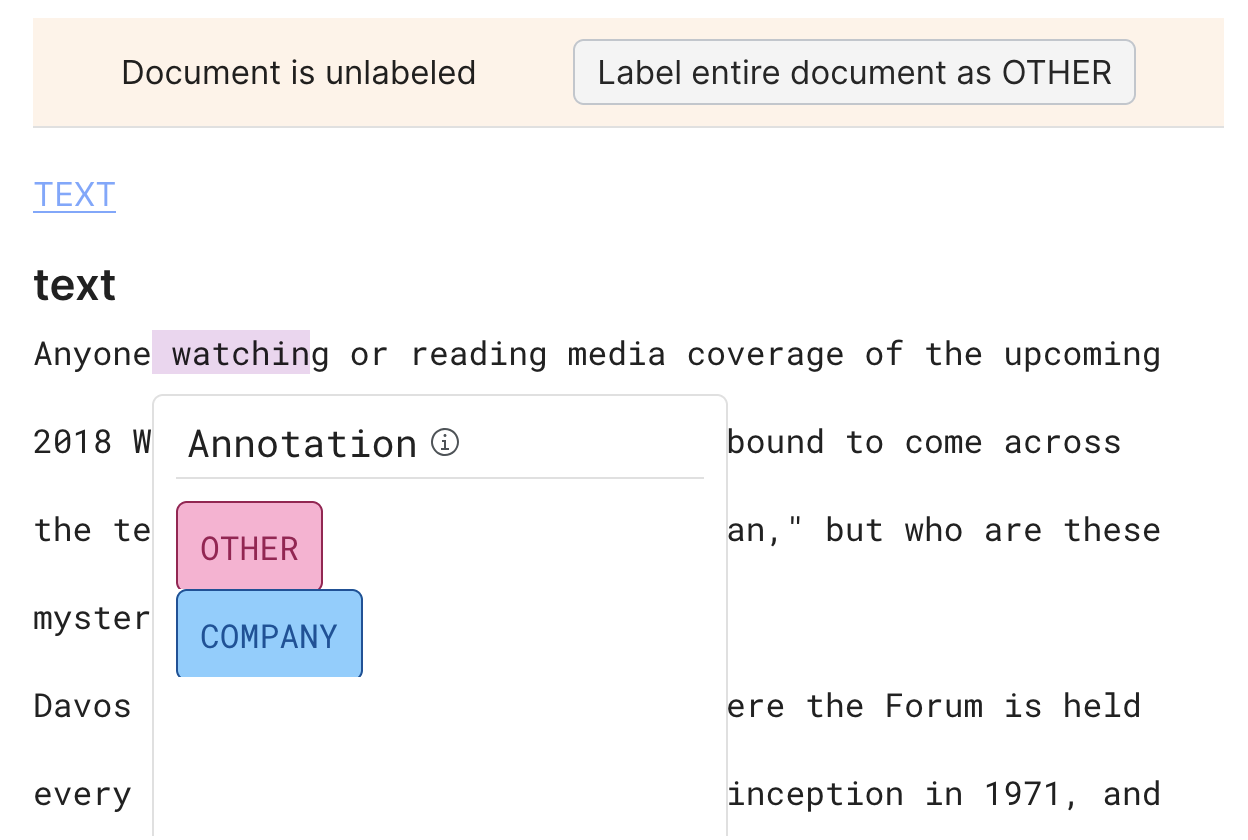
Annotate ground truth
You can also annotate ground truth labels in the Develop page directly by highlighting a span using either a double click or drag select mechanisms and assigning the label from the drop-down menu.
Write labeling functions
LF builders for sequence tagging application
Back on the Label page, you will notice two main panes:
- The left pane for creating labeling functions and viewing labeling function statistics
- The right pane for viewing the data
Here are some LFs you can try:
-
SKEY-facebook
-
Sequence Pattern Based LFs > Sequence Keyword Builder
textContains a keyword in["facebook"]
-
Label:
COMPANY -
Vote all the mentions of “facebook” as
COMPANY
-
-
SRGX-Inc-Ltd-Corp
-
Sequence Pattern Based LFs > Sequence Regex Builder
textContains the regular expression[A-Z]+[a-z]*,? (Inc|Ltd|Corp)\.?
-
Label:
COMPANY -
If a capitalized word is followed by “Inc” or “Ltd” or “Corp,” vote the whole phrase as
Company
-
-
SRGX-Shareof
-
Sequence Pattern Based LFs > Sequence Regex Builder
textContains the regular expression(?<=Shares of)\s([A-Z][a-z]+\s){1,5}
-
Label:
COMPANY -
Vote 1 to 5 capitalized words, as many times as possible, after the phrase “Shares of” as
Company
-
-
SRGX-CEOCFO
-
Sequence Pattern Based LFs > Sequence Regex Builder
textContains the regular expression\w+(\'|\’)?s? (?=(CFO|CEO|President))
-
Label:
COMPANY -
Vote the word before “CFO”, “CEO” or “President” as
Company
-
-
SED-f500
-
Sequence Pattern Based LFs > Sequence Entity Dict Builder
textContains the patterns from this files3://snorkel-workshop-data/financial-news/f500_ticker_key_fixed.json- This file contains a dictionary of Fortune 500 company names, stock tickers, and their aliases.
-
Label:
COMPANY
-
-
SRGX-lower
-
Sequence Pattern Based LFs > Sequence Regex Builder
textContains the regular expression\b[a-z]+\b
-
Label:
OTHER -
Vote all the lower case words as
OTHER
-
-
SRGX-wsww
-
Sequence Pattern Based LFs > Sequence Regex Builder
textContains the regular expression\(\w+\)
-
Label:
OTHER -
Vote all the words in the parentheses, along with the parentheses as
OTHER
-
-
SSPROP-adj-adv-verb
-
Sequence Pattern Based LFs > Sequence Spacy Prop Builder
- If the tokens in this Spacy field
docis tagged with any ofADJ,ADV,VERB
- If the tokens in this Spacy field
-
Label:
OTHER
-
-
SNER-DATE-PERSON
-
Sequence Pattern Based LFs > Sequence NER Builder
- If the spans in this NER field
docis tagged with any ofDATE,PERSON
- If the spans in this NER field
-
Label:
OTHER
-
LF metrics for sequence tagging application
After saving an LF, you’ll see the score for that LF. Note that in the sequence tagging application, the metrics for LFs are computed at the character-level.
LF development with in-platform notebook
The in-platform notebook interface allows you to develop custom labeling functions and explore your data using Jupyter. Here is an example of a custom LF. You can find details on other available helper functions in the Python SDK.
We can use the pre-defined dictionary derived from the 2016 Fortune 500 list to build a custom LF function to label all the Fortune 500 Companies as COMPANY:
from snorkelflow.studio import resources_fn_labeling_function
def get_taxonomy():
import fsspec
import json
taxonomy_file = "s3://snorkel-financial-news/f500_ticker_key_fixed.json"
with fsspec.open(taxonomy_file, mode='rt') as f:
taxonomy = json.load(f)
return {"taxonomy": taxonomy}
@resources_fn_labeling_function(name="lf_taxonomy", resources_fn=get_taxonomy)
def lf_taxonomy(x, taxonomy):
import re
spans = []
for ticker, companies in taxonomy.items():
pat = '\s(' + '|'.join(companies).replace('\\', '') + ')\s'
for match in re.finditer(pat, x.text):
char_start, char_end = match.span(1)
spans.append([char_start, char_end])
return spans
sf.add_code_lf(node, lf_taxonomy, label="COMPANY")
You can also create a multi-polar code LF (see Multi-polar LFs for more information) using the doc field that contains entity-level prediction from Spacy, e.g., if an entity is tagged as ORG, label the corresponding span as COMPANY, and if tagged as DATE, label as OTHER:
@labeling_function(name="my_multipolar")
def sample_multi_polar_code_lf_sequence(x):
ents = x.doc['ents']
spans = []
for ent in ents:
char_start = ent["start"]
char_end = ent["end"]
label = ent["label"]
if label == 'ORG':
spans.append([char_start, char_end, "COMPANY"])
elif label == 'DATE':
spans.append([char_start, char_end, "OTHER"])
return spans
lf = sf.add_code_lf(node, sample_multi_polar_code_lf_sequence, is_multipolar=True)
Create a label package and label your dataset
See the Create a label package and label your dataset of the Document classification: Classifying contract types.
Train a model
You can train a model on any training set. For sequence tagging applications, we offer the DistillBERT model for its compactness and relatively fast training time while preserving 95% of BERT’s performance. If run on a CPU, this model may take several minutes or more to finish. We also offer BERT Tiny which is about 2x faster than DistillBERT while preserving 90% of BERT's performance. Additional details on models can be found in Model training.
Here are some details about parameters that are specific to Distillbert models:
- fraction_of_negative_subsequences_to_use_for_training: Determines how many negative span tokens to show while training. This parameter helps reduce model bias for the negative label class when there is class imbalance between positive and negative label classes.
- stride_length and max_sequence_length: These correspond to the transformer tokenizer parameters stride and max_length respectively.
Span, overlap span, and token level model metrics
In the sequence tagging setting, we offer three levels of metrics to evaluate the final model performance:
- Word level: Measures how many words are labelled correctly with respect to the ground truth.
- Word Entity level: Measures how many groups of words are labelled correctly as entities, e.g. “Advanced Braking Technology Ltd” is considered as one entity when calculating the metrics.
- Overlap Span level: Measures how many predicted and ground truth spans overlap more than 50% as measured by Jaccard similarity.
For example, given a ground truth span “Advanced Braking Technology Ltd” and a predicted span “Braking Technology Ltd,” our recall scores for each measure are:
word_recall= 3/4 = 0.75word_entity_recall= 0/1 = 0.0overlap_span_recall= 1/1 = 1.0
View model predictions
You can view the model predictions on the Label page. On the models pane, in the drop-down model selector menu, select the Model ID of interest, (e.g. “1”).
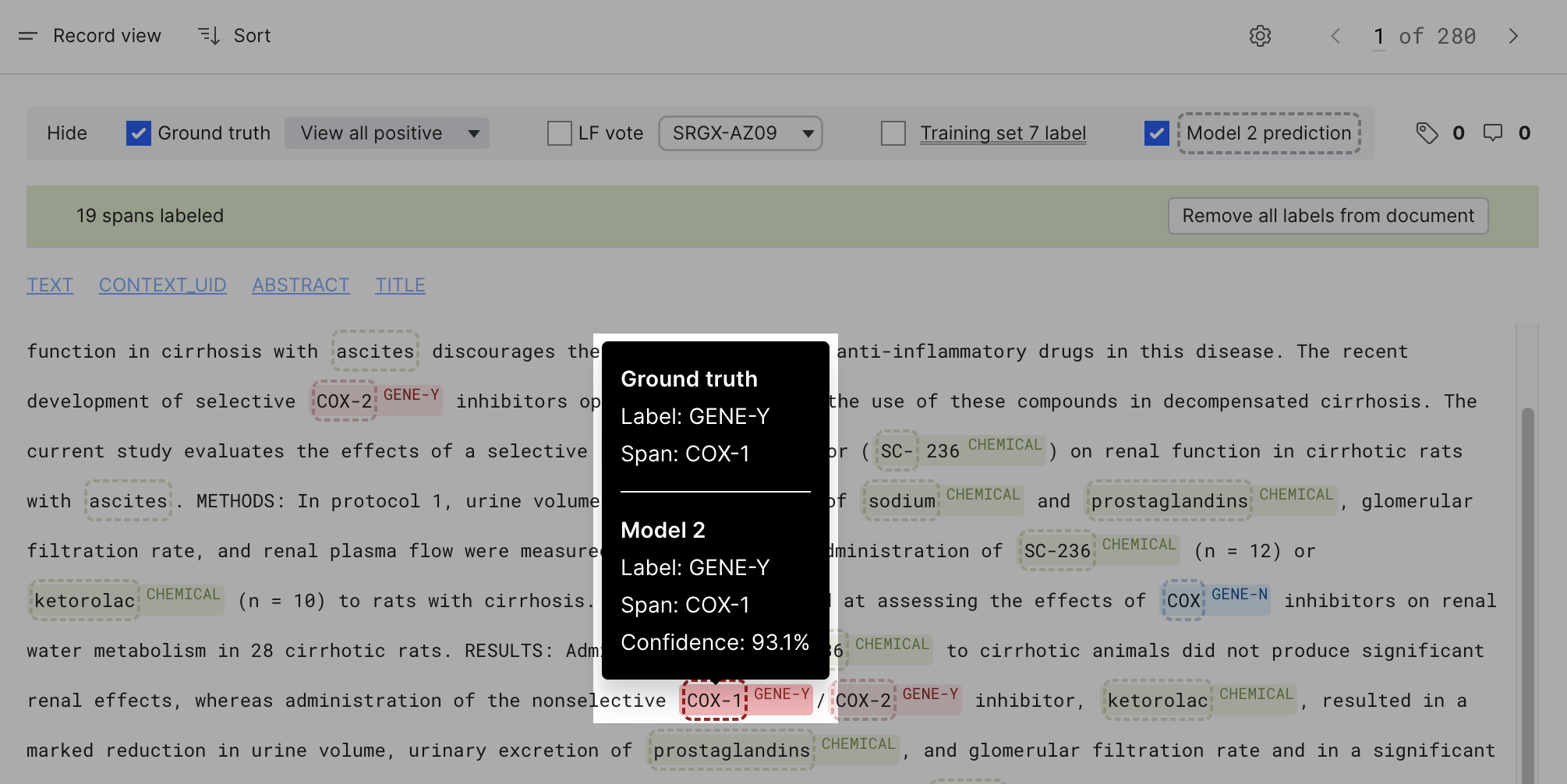
This will change the span highlighting to be based on the model prediction. If you hover over individual spans, you can see the predicted class with the confidence associated with the prediction.
View errors and iterate
See View errors and iterate in Document classification: Classifying contract types. Note that in the sequence tagging application, all analysis metrics are computed at the span level, which includes the Confusion Matrix, Clarity Matrix, Label Distribution, Class Level Metrics, Error Correlation, and PR curve.
Filters and span highlighting in record view and snippet view
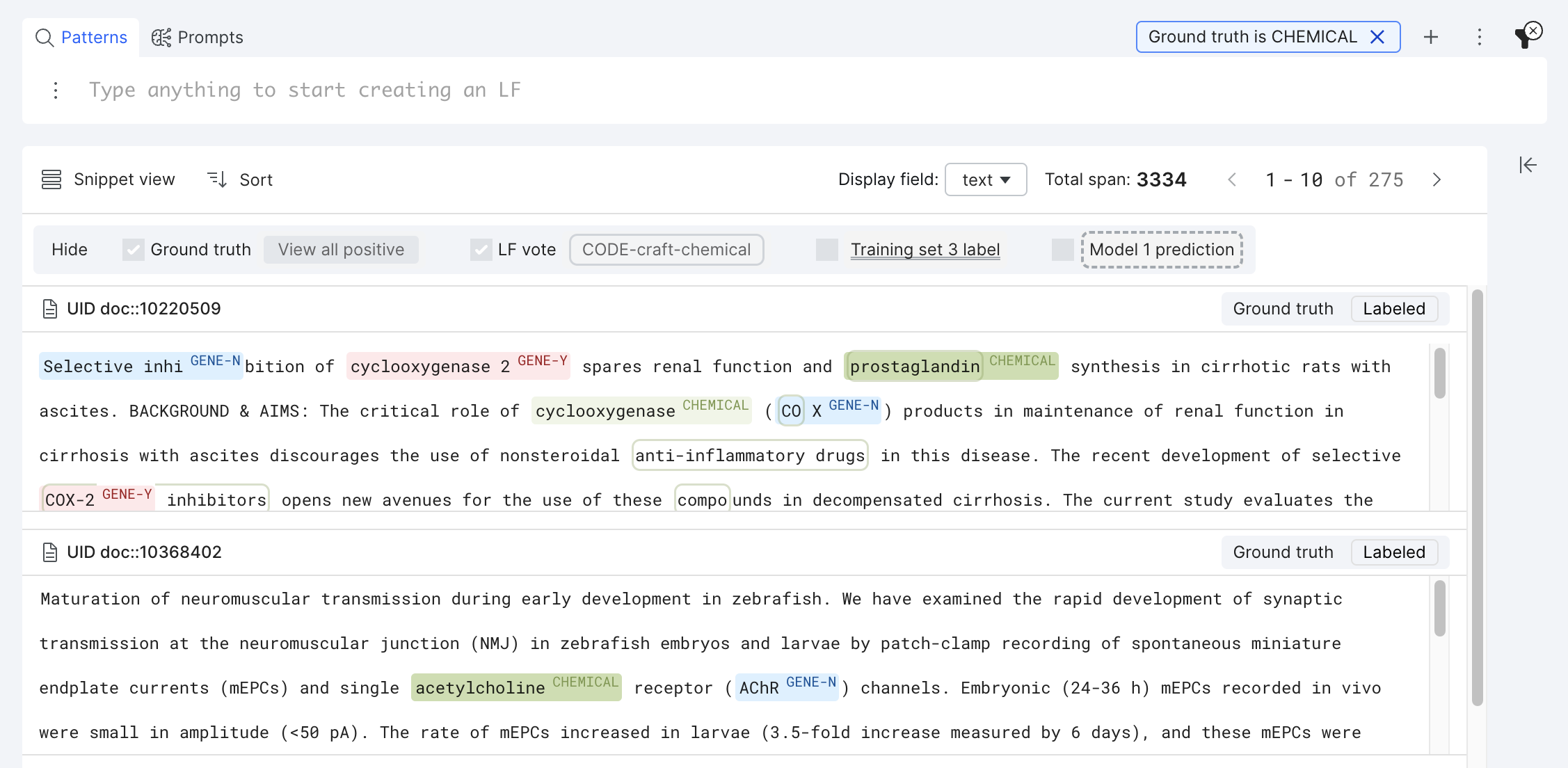
The filters are applied at the span level and automatically select the span type(s) to highlight among four types of spans (Ground truth, LF vote, Training set vote, and Model prediction). By default, ground truth is always highlighted. The spans matching the filter are presented in full color, whereas the spans that are not matching the filter are faded out in Record view.
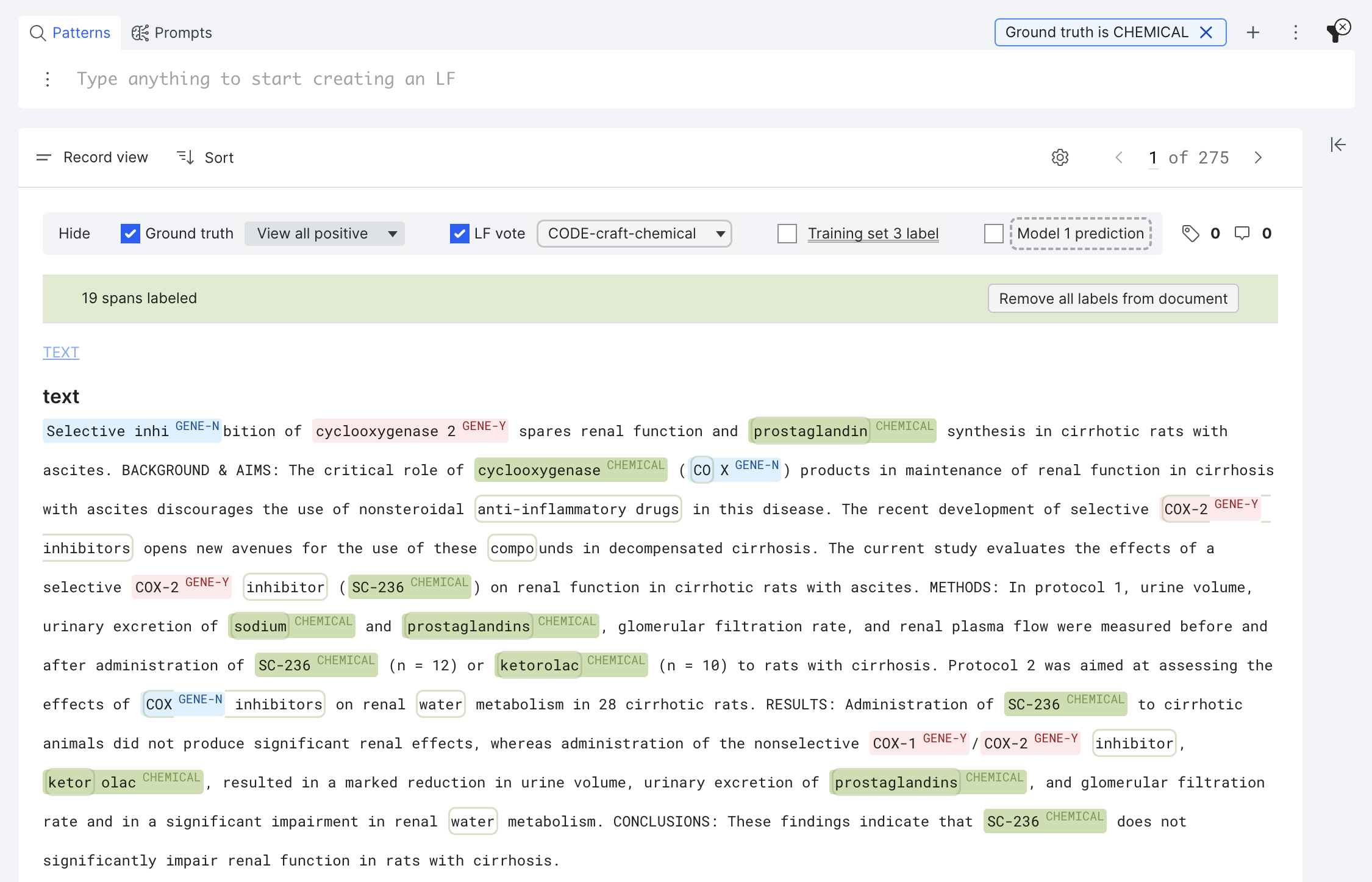
In the Snippet view, the highlight control pane is not editable, but spans are still viewable by scrolling each snippet:
Correctness filter
The correctness filter for LF and model/training set spans have different criteria. For model or training set spans to be correct, the exact match on both the boundary and label with ground truth is required. This is aligned with the span-level metrics. For LF spans, the correctness criteria is more relaxed: if an LF span only matches a part of a ground truth span, it is correct, as one can always write more LFs to cover the remaining part.
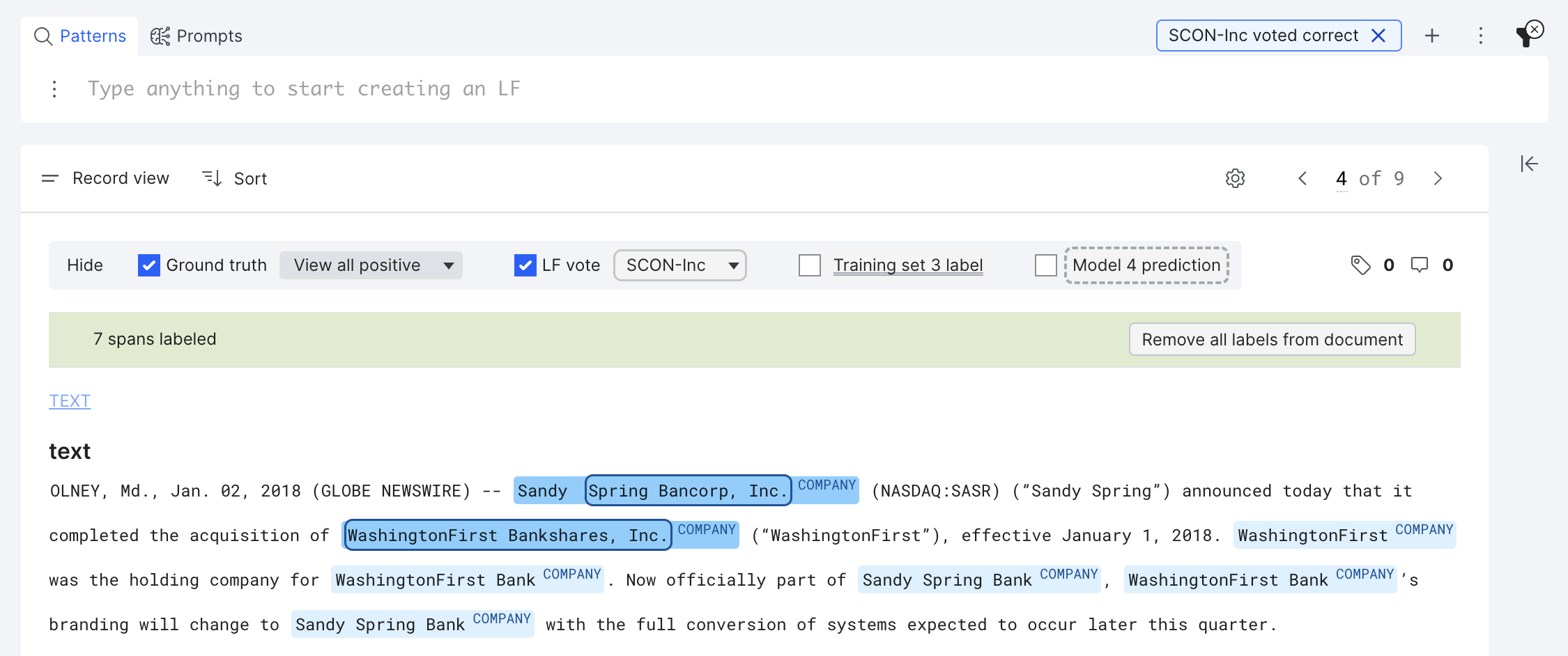
LF correctness filter
An LF span is correct as long as it is a substring of a ground truth span with the same label. For example, in the screenshot below, both “Spring Bancorp, Inc.” and “Washington Bankshares, inc.” are correct.
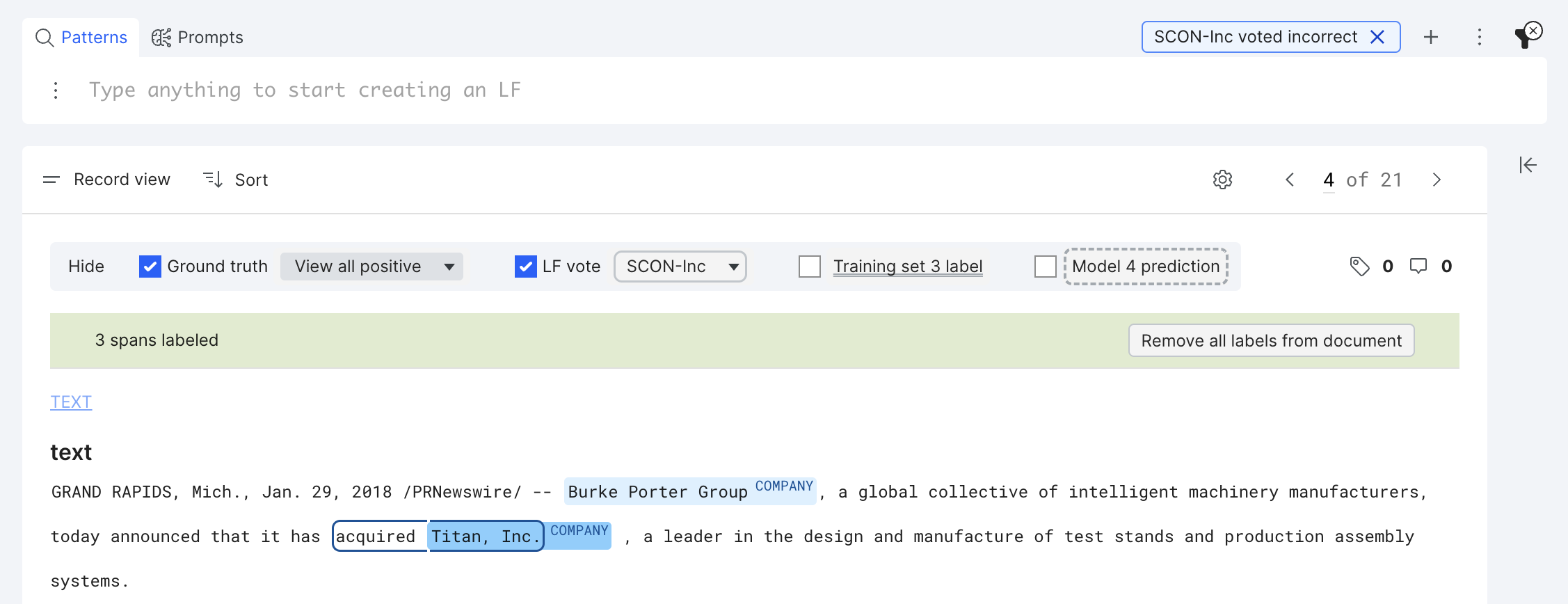
An LF span is incorrect as long as it votes on any character that is not in the selected class. For example, the LF voted incorrect on the “acquired ” (whose ground truth is OTHER)
Model and training set correctness filter
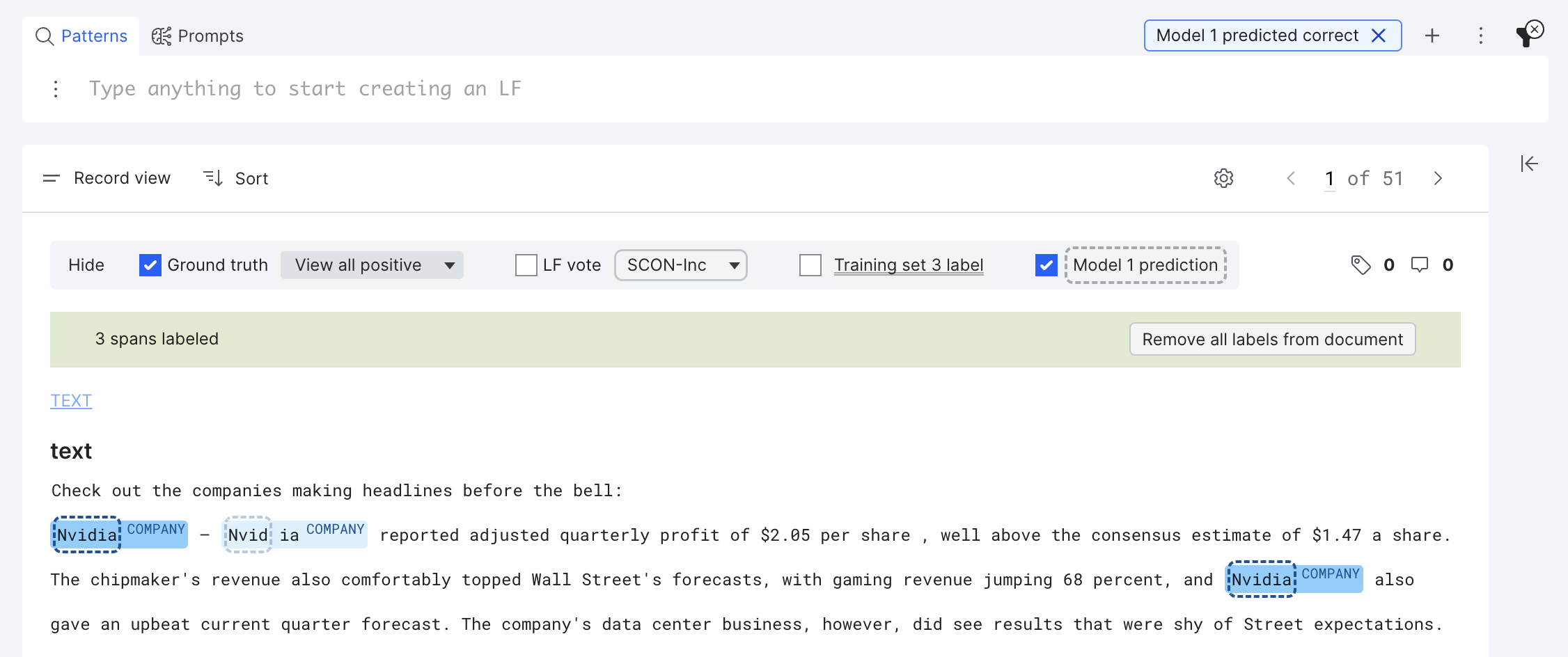
For a model or training set span to be correct, it has to match the ground truth span on both the label and the boundary. For example, in the screenshot below, only the first “Nvidia” and last “Nvidia” are correct model predictions and thus in focus. The second “Nvidia” is incorrect due to a mismatch in the span boundary and thus in transparent state.
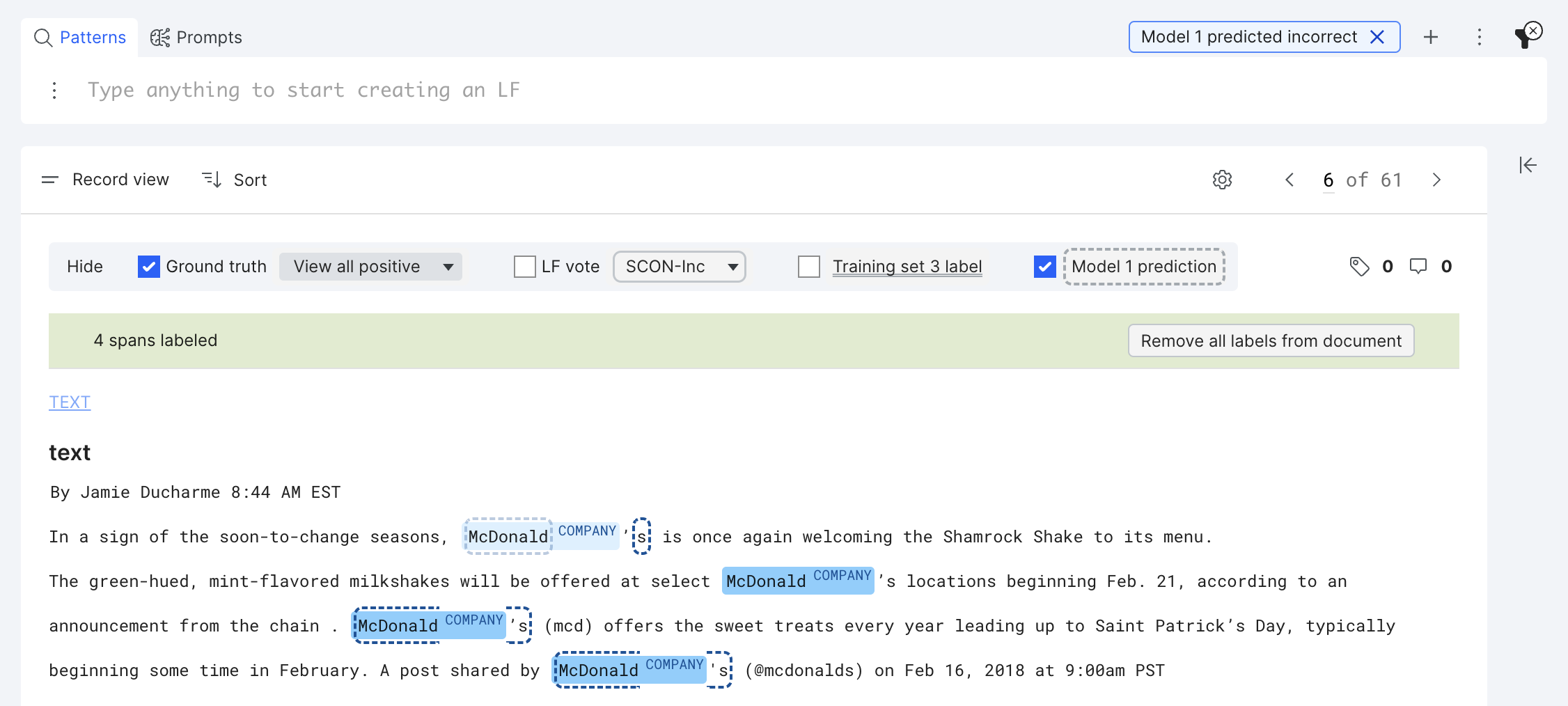
There are three types of incorrect model/training set spans: (1) False negative (e.g., the second “McDonald,” the ground truth is COMPANY but model predicted OTHER) (2) False positive (e.g., in the second paragraph, the model predicted “s” as COMPANY, but the ground truth is OTHER) (3) a model prediction span has an incorrect boundary (e.g., the last two “McDonald’s”)
Dataset and application requirements
- Label classes: A maximum of 25 positive label classes can be specified
- Labeling functions: A maximum of 200 labeling functions can be defined
- Total dataset size: A maximum of 250 MB total text data (i.e., data in the text field) across splits can be specified
- Studio dataset size: A maximum of 15 MB total text data (i.e., data in the text field) can be loaded in Studio
- Each text field: The maximum allowable size for the text field in each data point is 10 KB
Please contact a Snorkel representative for recommendations if any of these limitations are a concern.