Class level metrics
Class level metrics displays model performance on per-class basis to help decide where to best focus efforts.
This topic explains the class level metrics available in Snorkel Flow:
Word metrics
Word metrics are metrics that evaluate the performance of a model in identifying and labeling individual words in sequence tagging tasks, such as Named Entity Recognition (NER). To calculate word metrics, we consider the following:
- True Positive (TP): A word that the model correctly labels as belonging to the target category.
- False Negative (FN): A word that belongs to the target category but the model either misses or incorrectly labels.
- False Positive (FP): A word that does not belong to the target category but the model incorrectly labels as belonging to the target category.
Word recall
Word recall evaluates how well a model correctly identifies all relevant words that belong to a specific category. It measures the proportion of ground truth positive words that the model correctly labels as positive.
This is the formula for word recall:
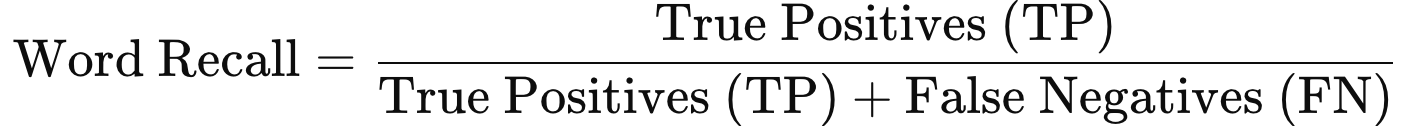
A high word recall indicates that the model is successfully identifying most or all of the relevant words for the target category, meaning it has few false negatives. However, word recall alone does not provide information on how accurately it labels those words, meaning it doesn't account for false positives. For a more comprehensive evaluation, use word recall alongside word precision and the word F1 score.
Word precision
Word precision evaluates the specificity of a model in sequence tagging tasks. Word precision measures how accurately the model labels words as belonging to a specific category.
This is the formula for word precision:

A high word precision indicates that most of the words labeled as positive by the model are indeed correct, meaning there are few false positives. However, word precision alone does not account for missed words (false negatives), which is why it’s often reported along with word recall and the word F1 score to provide a balanced view of the model's performance.
Word F1
Word F1 is a metric that combines word precision and word recall to provide a single measure of a model's performance. This metric balances the trade-off between precision, which is how many labeled words are correct, and recall, which is how many relevant words are found, to give a holistic view of the model's accuracy in identifying and labeling individual words.
The Word F1 score is the harmonic mean of word precision and word recall:

The Word F1 score ranges from 0 to 1:
- A score of 0 indicates the worst possible performance, meaning the model failed in both precision and recall.
- A score of 1 indicates perfect precision and recall, meaning the model has correctly identified and labeled all relevant words without any errors.
The Word F1 score is especially useful when both false positives and false negatives are important, as it provides a balanced measure of the model's overall ability to accurately identify and label individual words in the dataset.
Word Entity Metrics
Word Entity Metrics are metrics that evaluate the performance of a model in identifying and labeling multi-word entities (spans) in tasks like NER. To calculate word entity metrics, we consider the following:
- True Positive (TP): A group of words that the model correctly identifies and labels as an entity, matching both the entity type and exact boundary.
- False Positive (FP): A group of words that the model identifies and labels as an entity, but is either incorrect in type or boundary or does not match any true entity in the data. Even partial matches are considered false positives.
- False Negative (FN): A group of words that the model misses, either because the model didn’t identify it at all or didn’t match the entity’s boundaries or type correctly.
Word Entity Recall
Word Entity Recall evaluates how well a model correctly identifies all relevant groups of words that belong to a specific category. It measures the proportion of ground truth positive groups of words that the model correctly labels as positive.
This is the formula for word entity recall:
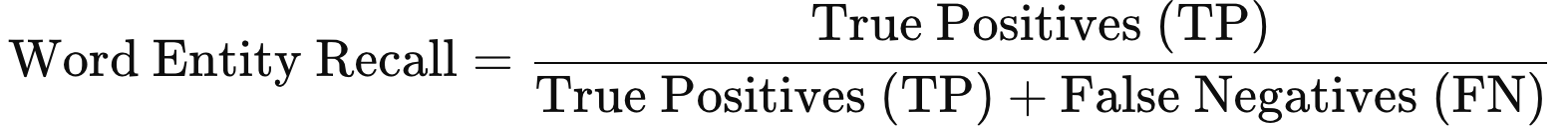
A high word entity recall indicates that the model successfully identifies most or all relevant spans within the dataset, meaning it does not miss many entities. Like word recall, word entity recall is most informative when used alongside word entity precision and the word entity F1 score, as this provides a balanced view of the model's ability to find and accurately label all entities.
Word Entity Precision
Word Entity Precision evaluates the specificity of a model in sequence tagging tasks. Word entity precision measures how accurately the model labels groups of words as belonging to a specific category.
This is the formula for word entity precision:

A high word entity precision indicates that most of the spans the model identifies as entities are accurate, meaning they correctly match the entities' boundaries and types as defined in the labeled data. However, word entity precision alone does not account for whether the model missed any actual spans, which is why it's often used in conjunction with word entity recall and word entity F1 score for a more complete evaluation.
Word Entity F1
Word Entity F1 is a metric that combines word entity precision and word entity recall to provide a single measure of a model's performance in identifying and labeling multi-word entities (spans) in tasks like NER. It is particularly useful because it balances the trade-off between word entity precision and word entity recall, making it an effective metric when both false positives and false negatives are of concern.
The Word Entity F1 score is calculated as the harmonic mean of word entity precision and word entity recall:
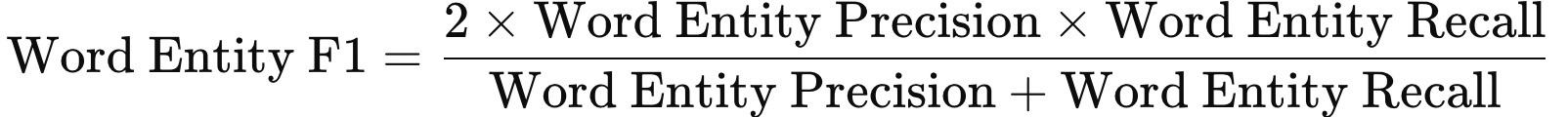
A Word Entity F1 score ranges from 0 to 1:
- A score of 0 indicates that the model failed to correctly identify any spans.
- A score of 1 indicates perfect precision and recall, meaning the model correctly identifies all spans without any errors or omissions.
The Word Entity F1 score is especially valuable in scenarios where it is important to accurately identify spans (precision) and ensure that no spans are missed (recall), as it reflects the model's overall effectiveness in capturing the correct entities.