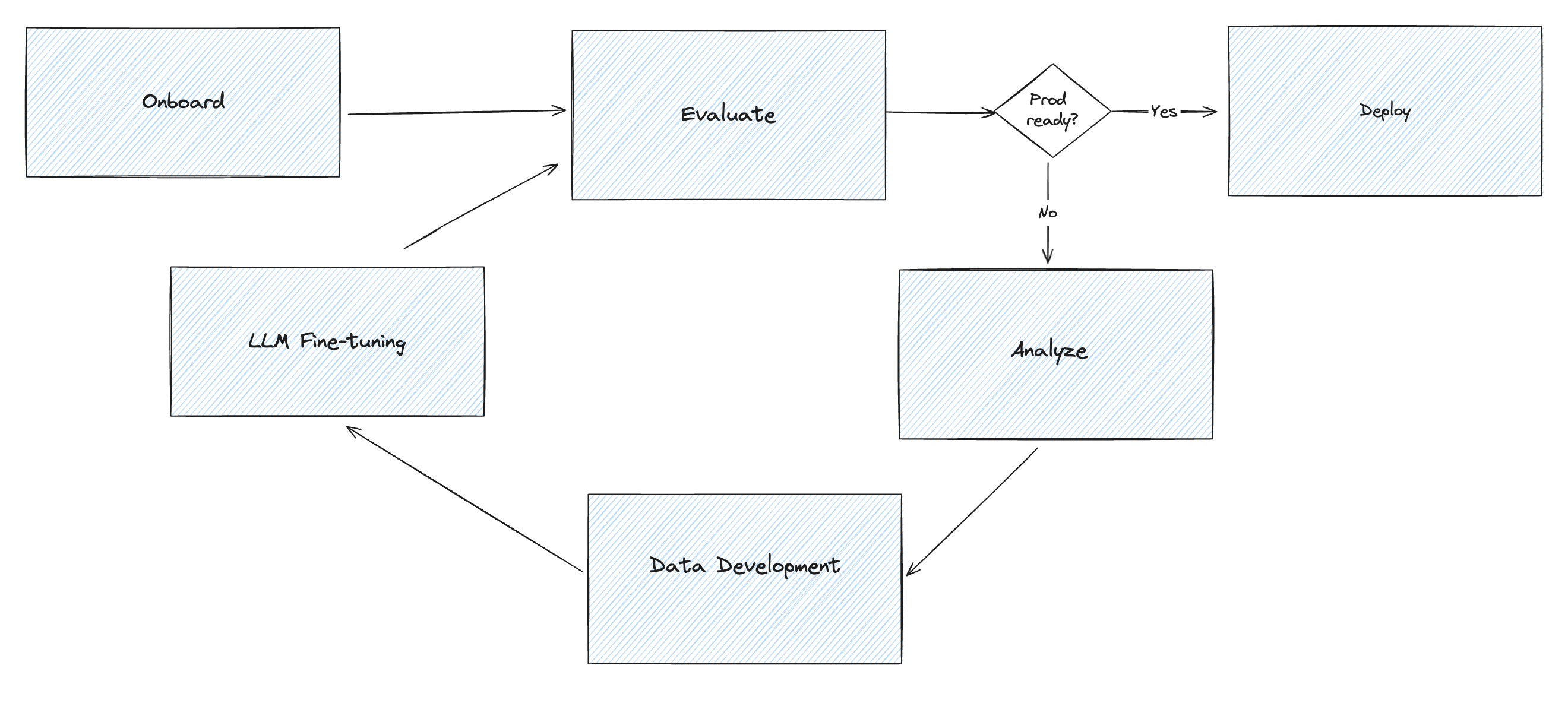
LLM fine-tuning and alignment tutorial
In this tutorial, you can use Snorkel to evaluate the current performance of a generative AI system. Snorkel Flow allows developers to programmatically align a large language model (LLM) to domain-specific preference and objectives. After analysis, programmatically curate a high quality, diverse training dataset that’s passed to an LLM for fine-tuning. Generated responses are brought back to Snorkel Flow for response quality labeling, error analysis, and iterative development.
This tutorial uses a dataset with ~600 financial service copilot instructions, retrieved context, and responses. A sample record is included below:
{
"questions": "How does a balance transfer affect my credit score?",
"responses": "A balance transfer can affect your credit score in several ways, both positively and negatively:\n\n1. **Credit Utilization Ratio**: When you transfer debt from one or more credit cards to a single card, you're likely...",
"prompt_prefix": "You are an expert in financial credit monitoring services and support. Given the context information and no prior knowledge, think step by step and answer the query. If you need to create a table, use markdown language to create the table. Remain concise during the dialogue and only answer information for which you have relevant factual context.",
"rc_title_text": [
{
"TITLE": "Impact on Credit Utilization Ratio",
"RELEVANT_CONTEXT": "When you execute a balance transfer, you move existing debt from one credit card to another, typically to take advantage of lower interest rates or promotional offers. This transfer can have an immediate impact on your credit utilization ratio, which is the amount of credit you're using compared to your total available credit. For instance, if you transfer a $5,000 balance to a card with a $10,000 credit limit and leave the original card's balance at zero, you improve your overall utilization ratio, as long as you don't use the freed-up credit to incur more debt. Lower utilization ratios are generally seen as positive by creditors and can lead to an improvement in your credit score. However, if the balance transfer significantly increases the balance on a single card, your score could temporarily drop due to the higher utilization rate on that card, even though your overall utilization might be lower."
},
{
"TITLE": "Effect of Hard Inquiries",
"RELEVANT_CONTEXT": "Applying for a new credit card to facilitate a balance transfer can result in a hard inquiry on your credit report. Each hard inquiry can potentially lower your credit score..."
}
]
}
Create the LLMFineTuning application
-
Import the dataset:
# imports
import snorkelflow.client as sf
from snorkel.labeling.lf import labeling_function
import snorkelflow.sdk as sfs
from snorkelflow.sdk.fine_tuning_app import FineTuningApp, QualityDataset
from snorkelflow.types.finetuning import (
AnnotationStrategy,
FineTuningAppConfig,
FineTuningColumnType,
LLMFineTuningLabelingConfig,
)
from snorkelflow.types.source import ModelSourceMetadata
from snorkelflow.sdk import Dataset
from snorkelflow.sdk.slices import Slice
import pandas as pd
from sklearn.model_selection import train_test_split
ctx = sf.SnorkelFlowContext.from_kwargs(
api_key=None, # change this to your API key if you are superadmin and want to use its privileges
workspace_name="default", # change this to work with a non-default workspace
) -
Create the application configuration.
noteOnly the instruction and response
FineTuningAppclass in the SDK documentation.#Create an fine-tuning app config and map data fields
app_config = FineTuningAppConfig(
column_mappings= {
"questions": "instruction",
"responses": "response",
"rc_title_text": "context",
"prompt_prefix": "prompt_prefix"
}
)
app_name = 'mm-copilot-test'
FineTuningApp.create(app_name, app_config)
ft_app = FineTuningApp.get(app_name)Train split: s3://snorkel-public/fine_tuning_tutorial_train.csvValid split: s3://snorkel-public/fine_tuning_tutorial_valid.csv#onboard data from s3 and couple it to a model source object
import boto3
import pandas as pd
from io import StringIO
# Initialize a session using boto3
s3_client = boto3.client('s3')
# Specify your bucket name and file key
bucket_name = 'snorkel-public'
files = ['fine_tuning_tutorial_train.csv', 'fine_tuning_tutorial_valid.csv']
dfs = []
for f in files:
# Fetch the file from S3
response = s3_client.get_object(Bucket=bucket_name, Key=file_key)
status = response.get("ResponseMetadata", {}).get("HTTPStatusCode")
if status == 200:
csv_content = response["Body"].read().decode('utf-8')
data = StringIO(csv_content)
df = pd.read_csv(data)
dfs.append(df)
print("CSV loaded successfully.")
else:
print(f"Failed to fetch the file from S3. Status code: {status}")
train_df = dfs[0]
valid_df = dfs[1]
model_source_uid = ft_app.register_model_source("model_iteration_name",
metadata=ModelSourceMetadata(model_name = "model_iteration_name"))['source_uid']
ft_app.import_data(train_df, "train", model_source_uid, sync = True )
ft_app.import_data(valid_df, "valid", model_source_uid, sync = True )
This workflow introduces a model source object, which maps data sources in the parent dataset to different iterations of fine-tuning. For example, data coming from the llama3-8b-instruct base model has a different model source id than data coming from a fine-tuned llama3-8b model. This object distinguishes metrics across evaluations and determine the data a user is developing on.
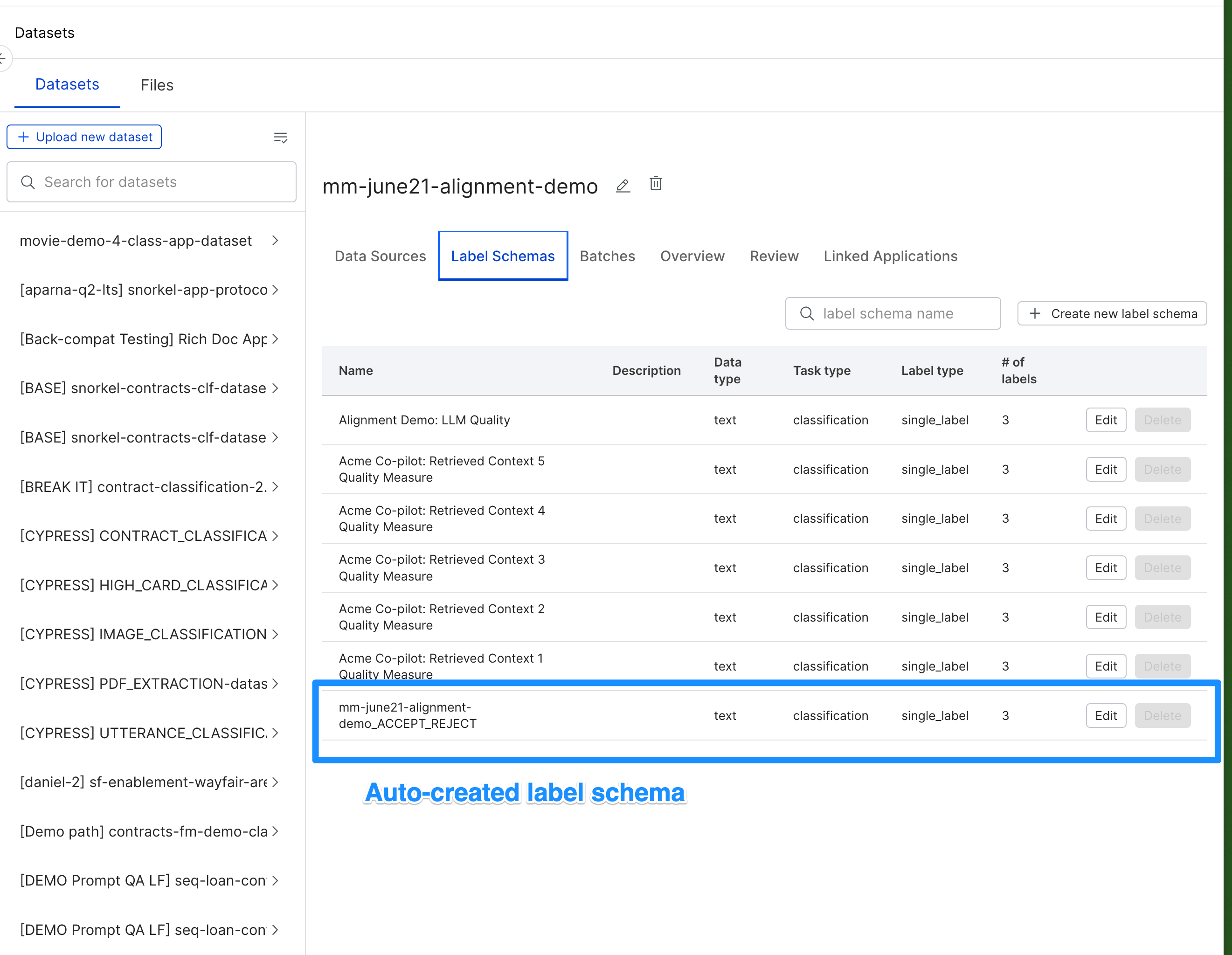
A FineTuning dataset and application have been created. An LLM quality label schema and single response dataset view are automatically generated.
For more information on label schemas and dataset views, see SDK documentation for label_schemas and dataset_views.
Evaluate
Now that data is onboarded, assess the performance of the current system. Snorkel Flow recommends two methods of evaluation:
Manual evaluation is a great starting point. However, with each fine-tuning iteration, the ground truth must be discarded because new responses are generated. Build a quality model in Snorkel Flow to solve for this issue.
Manual evaluation via domain experts
Assign domain experts with batches of data to evaluate. Snorkel recommends labeling the quality of the generated response and the quality of the retrieved context.
-
Create additional label schemas for retrieved context objects with this helper function:
def create_finetuning_label_schemas(dataset_name: str,
include_llm: bool, include_rag: bool, num_contexts: int):
#create the llm quality label schema
d = sfs.Dataset.get(dataset_name)
base = "Acme Co-pilot: "
if include_llm:
d.create_label_schema(
name = base + "LLM Quality Measure",
data_type = "text",
task_type = "classification",
multi_label = False,
label_map = ["ACCEPT_LLM", "REJECT_LLM"]
)
if include_rag:
for i in range(1,num_contexts+1):
ii = str(i)
d.create_label_schema(
name = base + "Retrieved Context " + ii + " Quality Measure",
data_type = "text",
task_type = "classification",
multi_label = False,
label_map = [("ACCEPT_RAG_"+ii), ("REJECT_RAG_" + ii)]
)
# Don't create the llm quality label schema because the FineTuningApp
# already creates it.
create_finetuning_label_schemas(dataset_name = app_name,
include_llm = False, include_rag = True, num_contexts = 5) -
Assign batches of data to domain experts to review.
Snorkel recommends creating an annotation guide, detailing characteristics of "good" and "bad" responses, to ensure the collection of highly-accurate ground truth. -
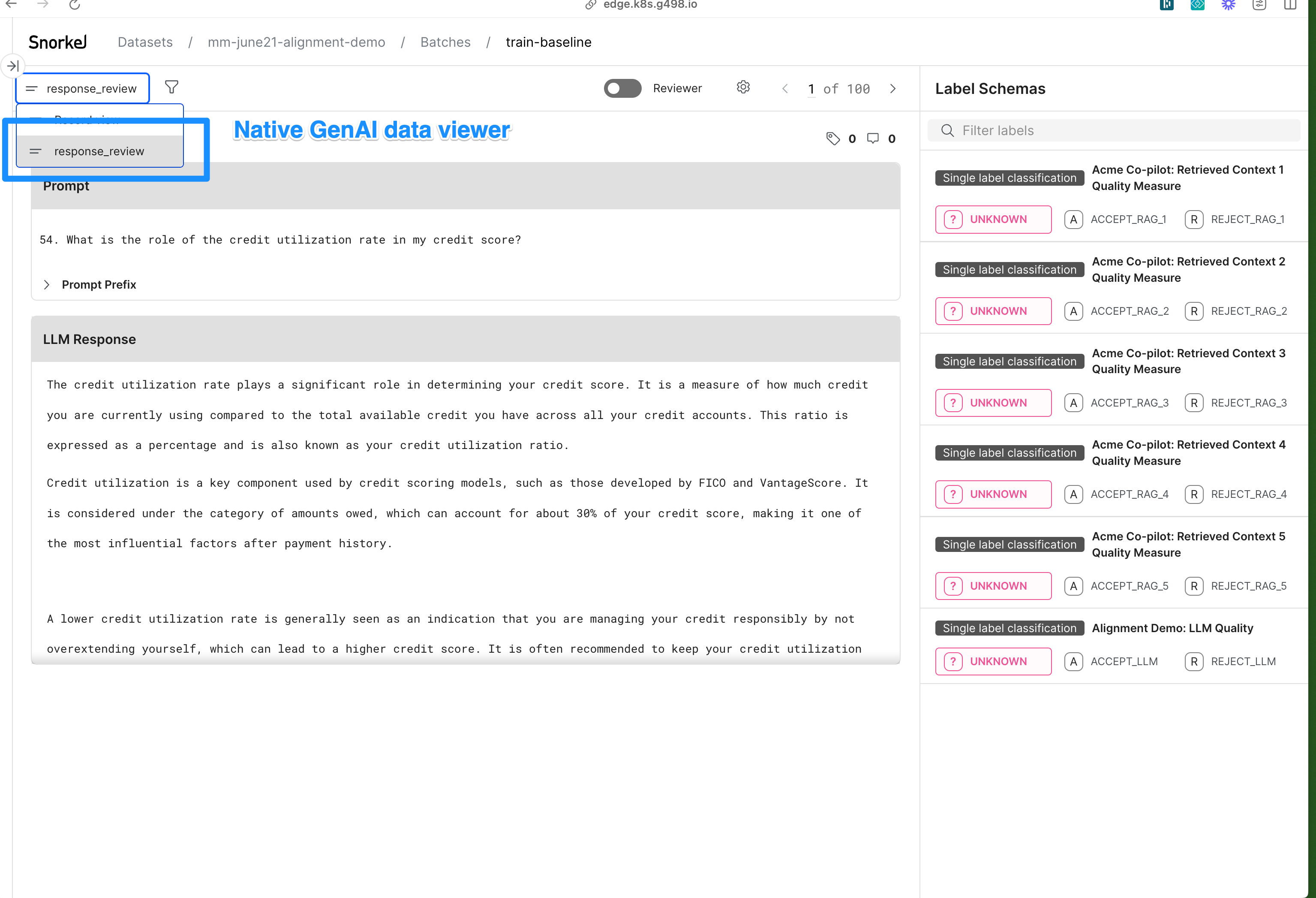
Annotators leverage Generative AI data viewers to interact with data in a more intuitive format. See the example below for creating dataset views:
duid = ft_app.dataset_uid
sf.create_dataset_view(
dataset= duid,
name="GenAI Data Viewer",
view_type="single_llm_response_view",
column_mapping={"instruction": "questions", "response": "responses",
"context": "rc_title_text"},
label_schemas = [list of label_schema uids that you want to enable the view for]
) -
After batches have been completed, commit annotations as dataset ground truth for the relevant label schemas.
Programmatic evaluation via a quality model
Encode the definition of good and bad via labeling functions (LFs). Use these LFs to train a quality model, which serves these functions:
- Identify good and bad instruction for response data at scale. These instructions filter data to create a curated dataset that is passed to an LLM for fine-tuning.
- Automatically evaluate new responses from a fine-tuned LLM.

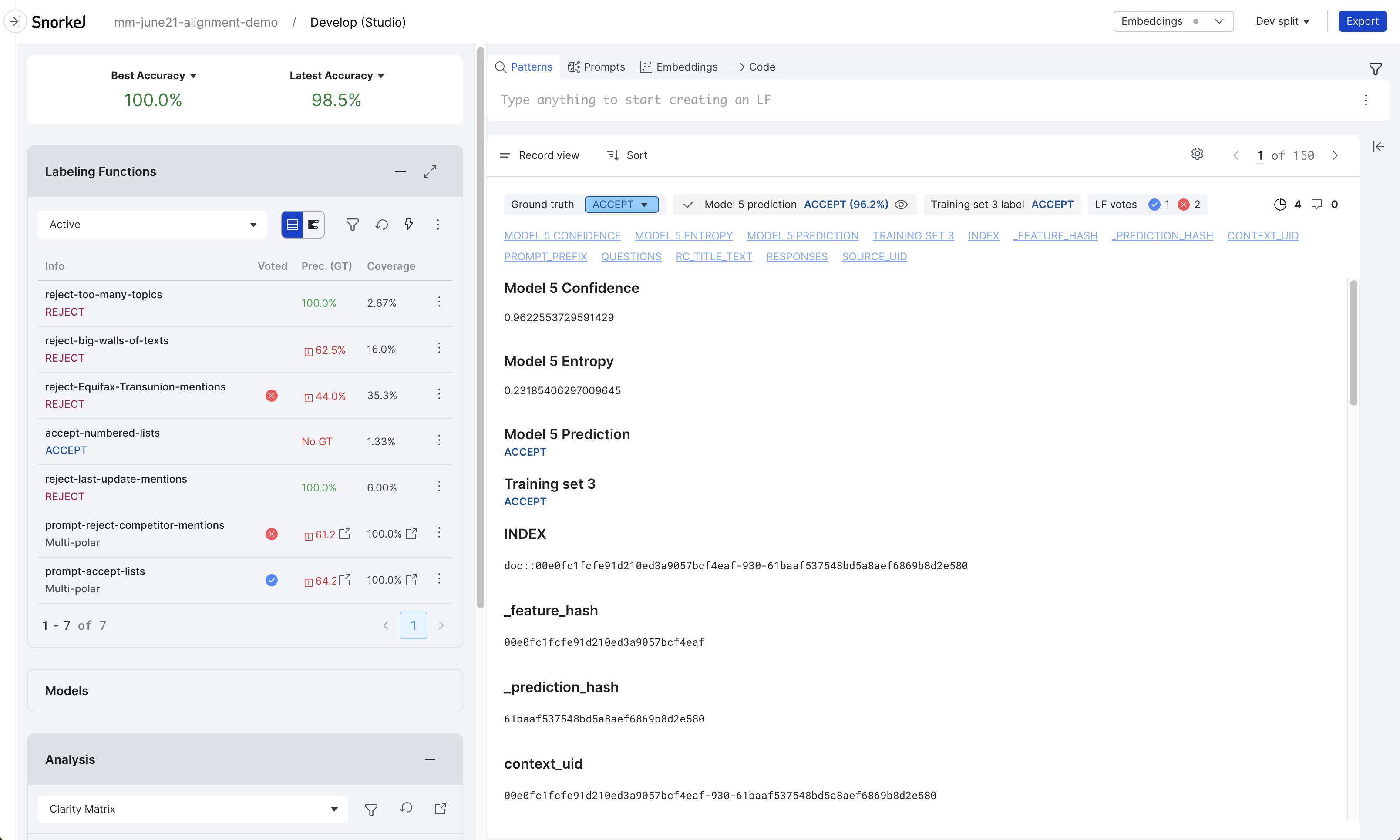
Analyze
With the manual and programmatic quality measurements have been collected, it's time to collate them into an evaluation to analyze and address error modes. Analysis takes these forms:
- Global
- Slice-wise
Snorkel Flow's Evaluations Module synthesizes manual and programmatic measurements of quality across your dataset. This approach gives developers a single, comprehensive view into their model's performance.
The global evaluation report is a great start, but lacks the fidelity needed to robustly understand performance gaps and understand where the developer needs to focus to improve performance. To solve for these limits, slicing functions are unit tests for your data. Slicing functions allow you to categorize the types of interactions you care about, measuring quality over each data slice.
Global analysis
Combine the quality measurements from domain experts and a trained quality model to assess performance:
# Create a global evaluation report
ft_app.create_evaluation_report(
split="train",
quality_models = [{Insert quality model name}],
slices = None
)
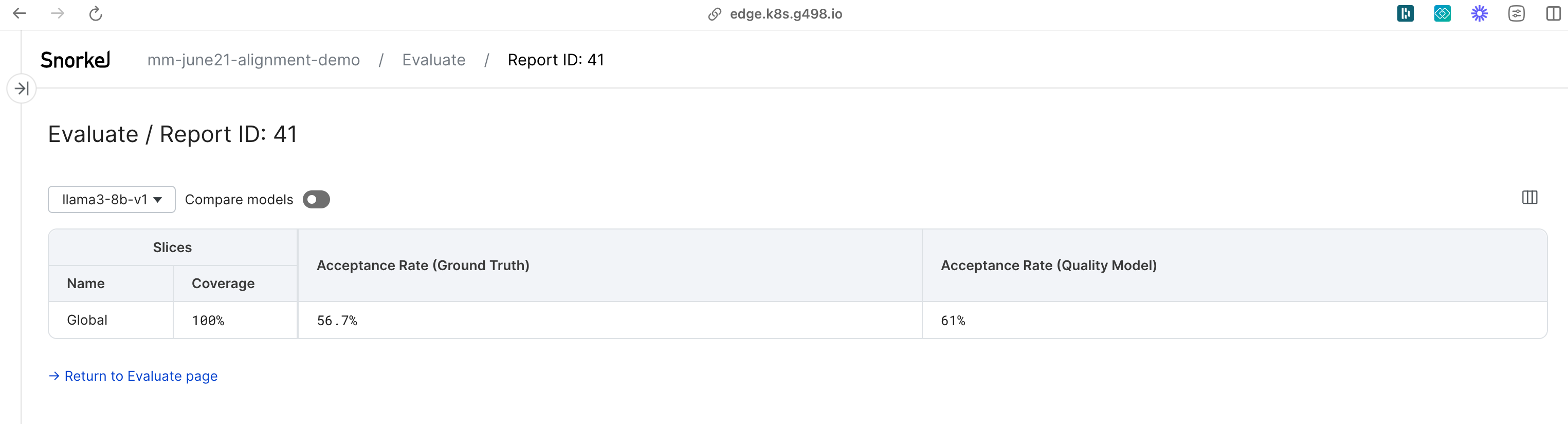
Slice-wise analysis
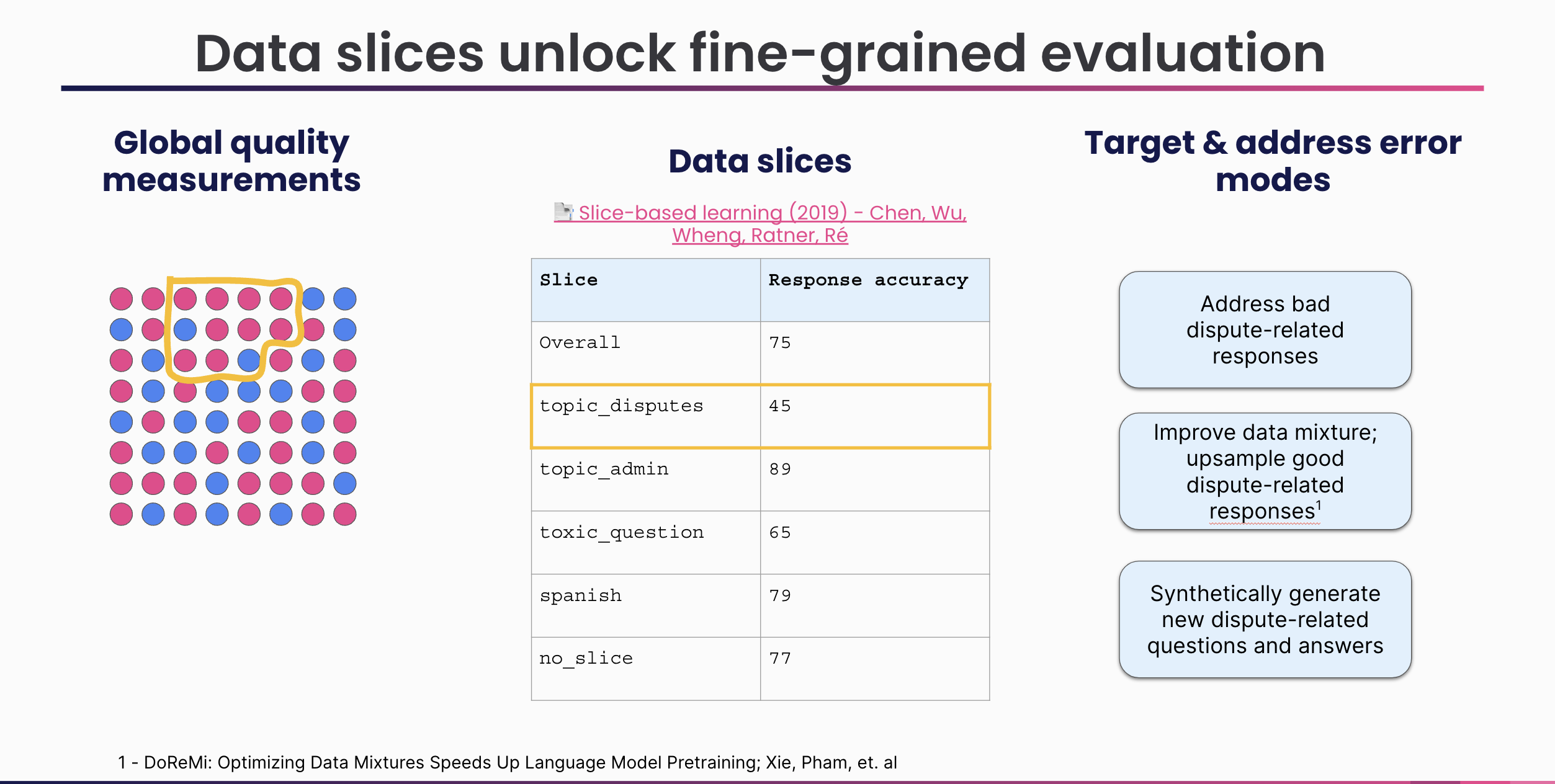
Write slicing functions
Slicing functions leverage the same operators as labeling functions. Use keywords, regular expressions, model, and LLM prompts to identify data slices of interest:
node = ModelNode.get(node_uid=ft_app.model_node_uid)
def apply_slice(slicing_fn):
df = node.get_dataframe()
slice_mask = df.apply(slicing_fn, axis=1)
df_sliced = df[slice_mask]
x_uids= list(df_sliced.index)
slice_name = slicing_fn.__name__
slice_percent = len(df_sliced) / len(df)
print(f"Applied '{slice_name}' slice (n={len(df_sliced)}, {slice_percent*100:.2f}%)")
return df_sliced, x_uids
import re
def topic_admin(x):
# Data slice to capture when users are asking
#about things like resetting passwords or usernames.
pattern = r"\b(password|email|username)\b"
match = re.search(pattern, x.responses, re.IGNORECASE)
return bool(match)
admin_df, admin_x_uids = apply_slice(topic_admin)
admin_slice = Slice.create(name="topic_admin", dataset=ft_app.dataset_uid)
admin_slice.add_x_uids(admin_x_uids)
Create a slice-wise evaluation
Combine quality measurements with data slices to get a fine-grained view into the system's current performance:
# Create a global evaluation report
ft_app.create_evaluation_report(
split="train",
quality_models = [{Insert quality model name}],
slices = [slice_1.slice_uid, slice_2.slice_uid, slice_3.slice_uid, ...]
)
Built-in evaluation metrics
Each evaluation report comes with two types of built-in metrics:
- Acceptance Rate (Ground Truth) is calculated based on the ground truth collected manually from domain experts.
- Acceptance Rate (Quality Model) is calculated based on the labels generated by the Quality Models. If you pass multiple Quality Models into the evaluation report, Snorkel Flow creates multiple metrics. For each Quality Model, the metric is derived from the latest committed version. If there are no committed versions, the metric defers to the latest trained version.
Custom Evaluation Metrics
You can register your own metrics defined through custom Python functions.
-
Define a custom Python function:
# Preview a sample of the dataframe
sample_df = ft_app.get_dataframe(split="train")
sample_df.head()
# Write the custom Python function
# Note that you can use all columns in the sample dataframe except the GT column
# Example Python function:
def short_response_ratio(df: pd.DataFrame) -> float:
if len(df) == 0:
raise ValueError(f"No samples found")
short_response_count = (df["responses"].str.len() <= 2000).sum()
return short_response_count / len(df)
# Test the metric function with the sample dataframe
sample_score = short_response_ratio(sample_df) -
Register the custom metric with the FineTuningApp:
# Register the custom metric with the FineTuningApp
ft_app.register_custom_metric(
metric_name = "Short Response Ratio",
metric_func = short_response_ratio,
)
# Create evaluation report
# All custom metrics registered with the FineTuningApp are automatically added to the report
ft_app.create_evaluation_report(split="train") -
If needed, update an existing custom metric registered with the FineTuningApp:
ft_app.register_custom_metric(
metric_name = "Short Response Ratio",
metric_func = short_response_ratio,
overwrite = True,
)
Create a curated fine-tuning dataset
If evaluations show system performance at or above production benchmarks, then developers can deploy the system into production. If not, you must further develop the LLM to reduce errors. Developers can leverage the quality model and slice membership to curate a high-quality, diverse training set that is passed to an LLM for fine-tuning.
-
Create a quality dataset, which is a subset of data from your global set.
# Create a curated dataset from a trained quality model
qd = ft_app.get_quality_dataset(model_uid = 1) # update to your end model uid
qd_filtered = qd.filter(confidence_threshold=0.9, labels=["ACCEPT"])
good_x_uids = list(qd_filtered.get_data().index)
good_datasource_uids = list(qd_filtered.get_data()['datasource_uid'].unique())
good_datasource_uids = [int(i) for i in good_datasource_uids] -
Pass this quality dataset to an LLM service for model fine-tuning.
For more advanced filtering operations, see the QualityDataset class in Snorkel's SDK documentation.
Fine-tune and update the LLM
Use the curated quality dataset to fine-tune an LLM. Snorkel supports these methods of fine-tuning:
- Fine-tune using Snorkel's SageMaker Jumpstart integration
- Fine-tune via another third-party LLM provider
Fine-tune using Snorkel's SageMaker Jumpstart integration
-
Configure access to the SageMaker Jumpstart service:
#Code to create the sagemaker connection
AWS_ACCESS_KEY_ID = "aws::finetuning::access_key_id"
AWS_SECRET_ACCESS_KEY = "aws::finetuning::secret_access_key"
SAGEMAKER_EXECUTION_ROLE = "aws::finetuning::sagemaker_execution_role"
FINETUNING_AWS_REGION = "aws::finetuning::region"
sf.set_secret(AWS_ACCESS_KEY_ID, "{your_access_key}", secret_store='local_store',
workspace_uid=1, kwargs=None)
sf.set_secret(AWS_SECRET_ACCESS_KEY, "{your_secret_key}", secret_store='local_store',
workspace_uid=1, kwargs=None)
sf.set_secret(SAGEMAKER_EXECUTION_ROLE, "arn:aws:iam::746568209548:role/service-role/AmazonSageMaker-ExecutionRole-20220908T104212",
secret_store='local_store', workspace_uid=1, kwargs=None)
sf.set_secret(FINETUNING_AWS_REGION, "us-west-2", secret_store='local_store',
workspace_uid=1, kwargs=None)
boto_session = boto3.Session(
aws_access_key_id= "{your_access_key}",
aws_secret_access_key="{your_secret_key}",
region_name="us-west-2"
)
sagemaker_client = boto_session.client('sagemaker')
sagemaker_runtime_client = boto_session.client('sagemaker-runtime')
sagemaker_session = Session(
boto_session=boto_session,
sagemaker_client=sagemaker_client,
sagemaker_runtime_client=sagemaker_runtime_client
) -
Set up the training job configuration:
finetuning_configs = {
"epoch": "1",
"instruction_tuned": "True",
"validation_split_ratio": "0.1",
"max_input_length": "1024",
"chat_dataset": "False"
}
training_configs = {
"instance_type": "ml.p3dn.24xlarge or insert instance type"
}
column_mapping = {
FineTuningColumnType.INSTRUCTION: "questions",
FineTuningColumnType.RESPONSE: "responses",
FineTuningColumnType.CONTEXT: "rc_title_text",
FineTuningColumnType.PROMPT_PREFIX: "prompt_prefix"
}
external_model_trainer = ExternalModelTrainer(
column_mappings=column_mapping,
finetuning_provider_type=FinetuningProvider.AWS_SAGEMAKER
)To request an LLM provider or base model, reach out to your Snorkel support team. Snorkel currently supports Low Rank Adaptation(LoRA)-based fine-tuning over these base models:
- Mistral-7B
- Llama3-8b-instruct
-
Upload training data to Sagemaker and begin the fine-tuning job:
external_model = external_model_trainer.finetune(
base_model_id="meta-textgeneration-llama-3-8b-instruct",
base_model_version="2.*",
finetuning_configs=finetuning_configs,
training_configs=training_configs,
datasource_uids= good_datasource_uids,
# to filter on x_uids
x_uids=good_x_uids,
# Set sync=False to return a job id and release the notebook kernel
sync=True
) -
To verify fine-tuning progress, log in to the SageMaker tenant, navigate to Training Jobs, and view InProgress jobs.
-
After fine-tuning is complete, run the dataset's instructions and optional
relevant_contextagainst the fine-tuned model to generate new responses:DATASOURCES_FOR_INFERENCE = datasource_inference_uids
source_uid = external_model.inference(
datasource_uids=DATASOURCES_FOR_INFERENCE,
# to filter on x_uids, uncomment here
# x_uids=x_uids,
deployment_config = {"instance_type": "ml.g5.2xlarge"},
# Set sync=False to return a job id and release the notebook kernel
sync=True,
) -
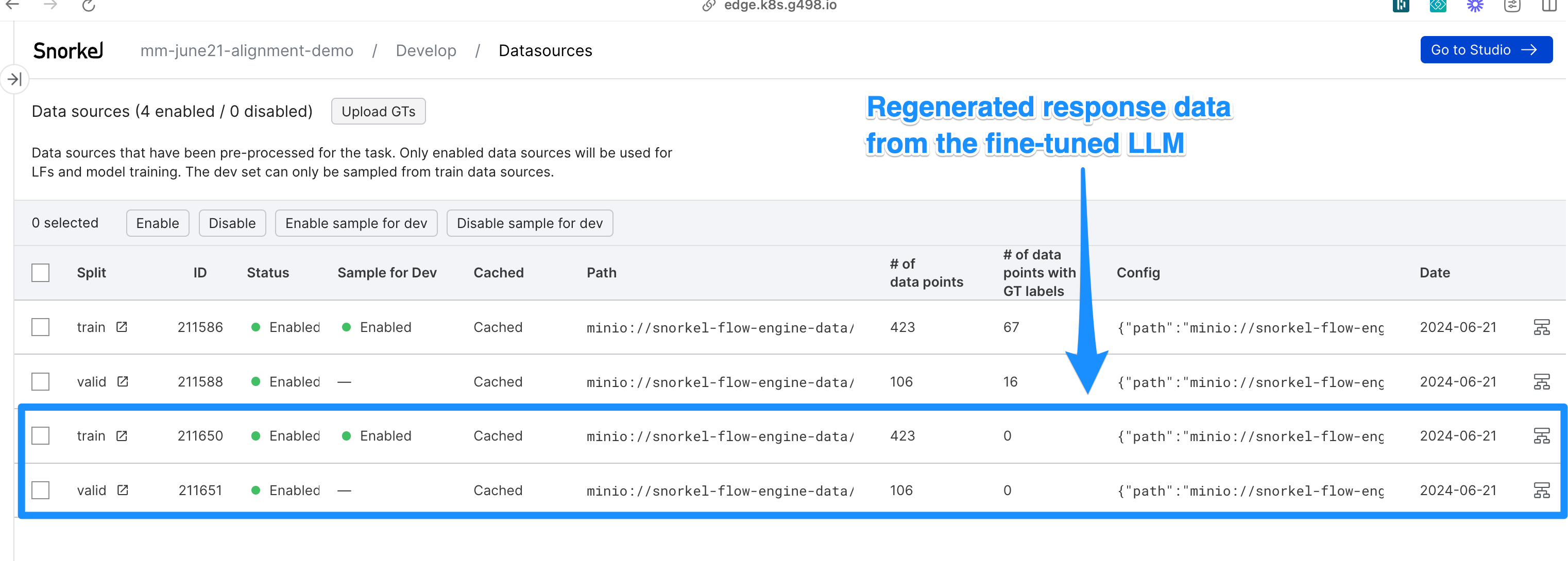
Upload the regenerated responses as a new datasource in Snorkel Flow.
-
After the responses are regenerated, view application datasources to see the newly created and enabled datasources:
Fine-tune via third-party LLM provider
If the fine-tuning and inference service is not natively integrated into Snorkel Flow, you can enable fine-tuning with a third-party LLM Provider.
-
Create a fine-tuning dataset, and export the dataset from Snorkel:
# Create a curated dataset from trained quality model predictions and model confidences
qd = ft_app.get_quality_dataset(model_uid=1) # update to your quality model uid
qd_filtered = qd.filter(confidence_threshold=0.9, labels=["ACCEPT"])
qd_filtered.to_csv('fine_tuning_set.csv') -
Export the entire dataset from the application to regenerate:
df = ft_app.get_data()
df.to_csv("instruction_data.csv") -
Fine-tune an LLM outside of the Snorkel platform.
-
Regenerate responses using the fine-tuned LLM outside of the Snorkel platform.
-
Import the fine-tuned dataset with new generations:
# Upload new datasources to Snorkel, consisting of the original instruction set and newly generated responses.
train_df = pd.read_csv('./train_new_responses.csv')
valid_df = pd.read_csv('./valid_new_responses.csv')
# configure the LLM provider, model iteration and upload new data
model_source_uid = ft_app.register_model_source("llama3-8b-finetunev1", metadata=ModelSourceMetadata(model_name = "llama3-8b-finetunev1"))['source_uid']
ft_app.import_data(train_df, "train", model_source_uid, sync = True )
ft_app.import_data(valid_df, "valid", model_source_uid, sync = True )
After completing these steps, users will be able to evaluate and develop data from the newly fine-tuned LLM.
Re-evaluate
After fine-tuning is complete, evaluate the fine-tuned model. A manual approach requires engaging domain experts for another round of labeling. With Snorkel's quality model, you can get immediate feedback on the performance globally and across data slices.
Quality model predictions are not automatically generated for new data.
-
Commit the desired quality model to the model node. Note the model UID.
-
Acquire the new data in the notebook and run it through the current application graph.
model_source_uid = {new model source requiring predictions}
app_name = {application name}
qm_model_uid = {uid of quality model}
node_uid = {uid of model node}
ft_app = FineTuningApp.get(app_name)
new_data = parent = ft_app.get_dataframe(source_uids = [1095])
results = sf.execute_graph_on_data(application=app_name,target_uids=[model_node], df=new_data)[model_node] -
Once quality model predictions for new data have been acquired, map the dataset
x_uidsto model predictions and probabilities. -
Upload those to the quality model as new predictions.
results['mapped_x_uids'] = results['cont_uid'].map(lambda x: new_data[new_data['cont_uid'] == x].index[0])
sf.add_predictions(
node = model_node,
model_uid = qm_model_uid,
x_uids = results['mapped_x_uids'].tolist(),
predicted_labels = results['preds'].tolist(),
predicted_probs = results['probs'].tolist()
) -
Create a new evaluation report and make notice of QM predictions for the new model iteration data.
-
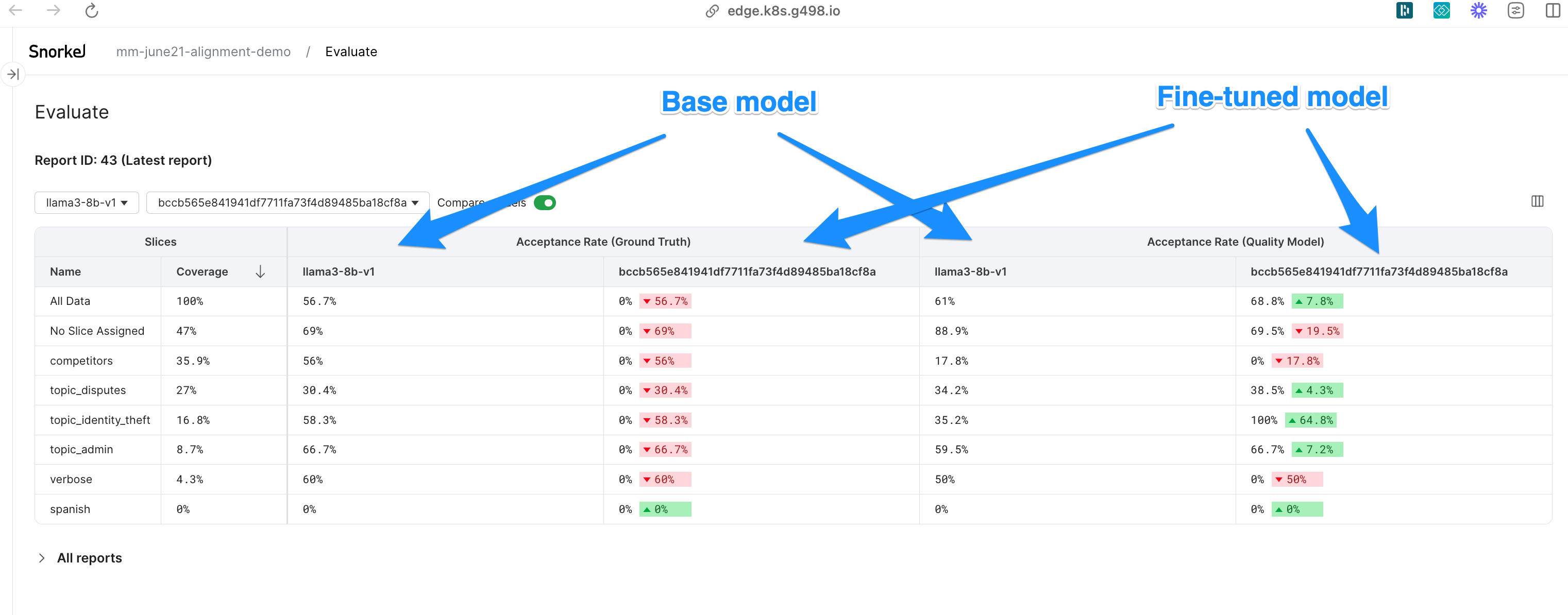
View the performance of the fine-tuned model against the base model.
ft_app.create_evaluation_report(
quality_models = ['quality model name']
)
Conclusion
Snorkel's fine-tuning workflow enables developers to programmatically align an LLM to domain-specific preference and objectives. The annotation, evaluation, and development modules enable faster LLM fine-tuning via the programmatic approach.
For any questions, contact your account team or support@snorkel.ai.