Evaluate GenAI output
Snorkel Flow enables enterprise AI teams to assess AI-generated output with evaluations that are:
- Specialized
- Fine-grained
- Actionable
This tutorial walks you through an end-to-end workflow for how to set up an evaluation pipeline for GenAI-generated output, using Snorkel's Evaluation feature set.
The majority of the steps use Snorkel's SDK, which are combined in a single Python notebook for ease of use.
This tutorial describes the example scenario, the prerequisite data setup, and the output you'll achieve. The notebook itself contains the documentation and the code to complete the functional example use case.
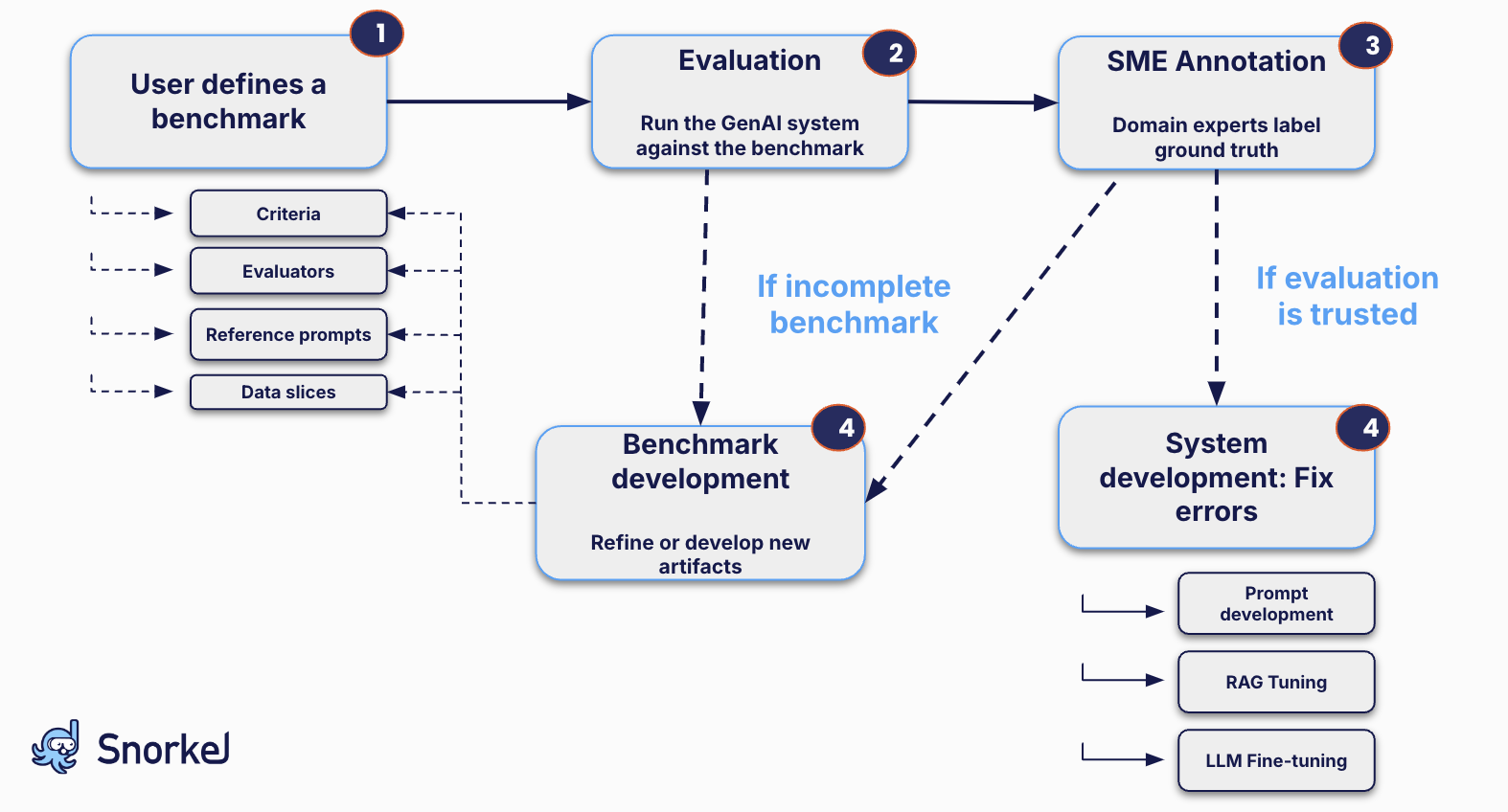
Process overview diagram
Here's a diagram that shows the phases of the evaluation workflow. Each phase is discussed in detail in the following sections.
Prerequisites
- A Snorkel Flow instance
- A Superadmin API key for Snorkel Flow
- Amazon SageMaker with authentication secrets (used for fine tuning; you can skip that step in the notebook)
Download the notebook and resources
Download these files. Upload all of them to Snorkel Flow, in the Notebook section, in the same directory.
- eval-genai-notebook.ipynb
- eval-spanish.csv
- eval-train-1.csv
- eval-train-2.csv
- eval-valid.csv
- eval-lid.176.bin
Once you've uploaded the files and updated the required user inputs in the notebook, you can run the notebook.
Evaluate output from a health insurance chatbot
This example uses a health insurance chatbot as the application. The notebook walks through the four main phases of an evaluation workflow. This document discusses an overview of the use case, while implementation details and detailed guidelines and best practices are included in the notebook.
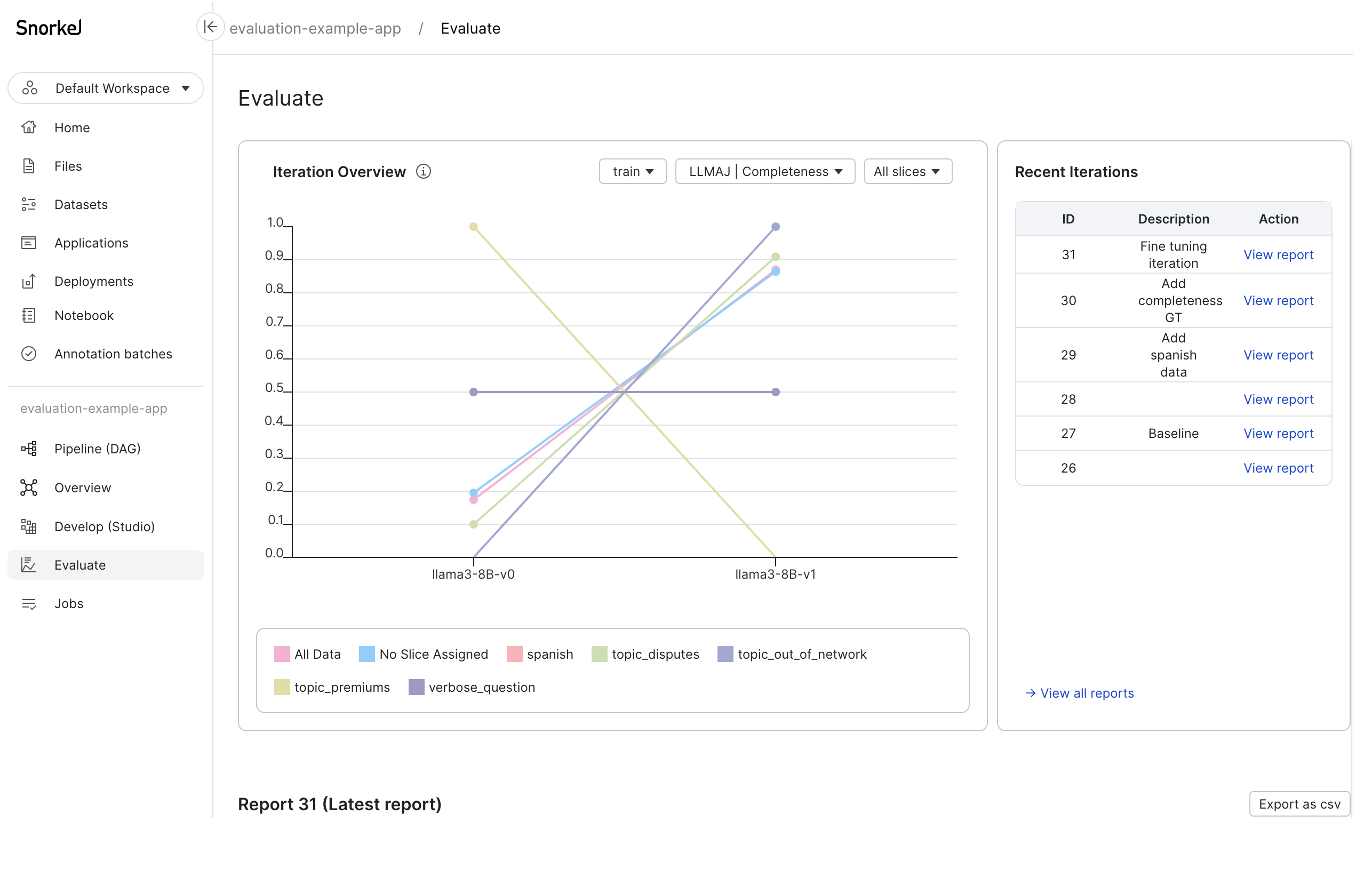
By the end of this example, you'll have reports for two generations of the chatbot, which you can view in the Evaluate page in the Snorkel Flow app.
Phase 1: Onboarding artifacts
The goal for your evaluation pipeline is for every version of your GenAI system to have an evaluation report associated with it. This notebook starts with a dataset (eval-train-1.csv) that represents a set of instructions and responses from the first version of the chatbot.
You'll also be defining how you want to measure success.
Prepare your evaluation pipeline with these steps:
-
Import the necessary libraries and create the application scaffolding in Snorkel Flow.
-
Import your existing data from the first version of the health insurance chatbot and some labeled responses as ground truth.
-
Define individual criteria for a high-quality response. In this example, the criteria are:
- Completeness
- Correctness
- Polite Tone
- Retrieved Context Accuracy
unit_test_contains_piiunit_test_mentions_competitors
-
Set up annotation batches to collect human feedback.
-
Define evaluators that measure the criteria programmatically.
-
Define data slices to benchmark the performance of the chatbot across different topics. In this example, the slices are:
- Verbose questions
- Questions written in Spanish
- Disputes
- Questions about out-of-network coverage
- Questions about premiums
- Remove any NA/None type values from your dataframes before uploading them to Snorkel.
- This workflow introduces a model_source object, that maps data sources in the parent dataset to different experiments. For example, the initial data is from the
llama3-8B-v0experiment, and it has a different model source id than data added later from thellama3-8B-v1experiment. This object distinguishes metrics across evaluations and determines the data a user is developing.
To read more about this phase, see Onboarding artifacts.
Phase 2: Creating the initial evaluation benchmark
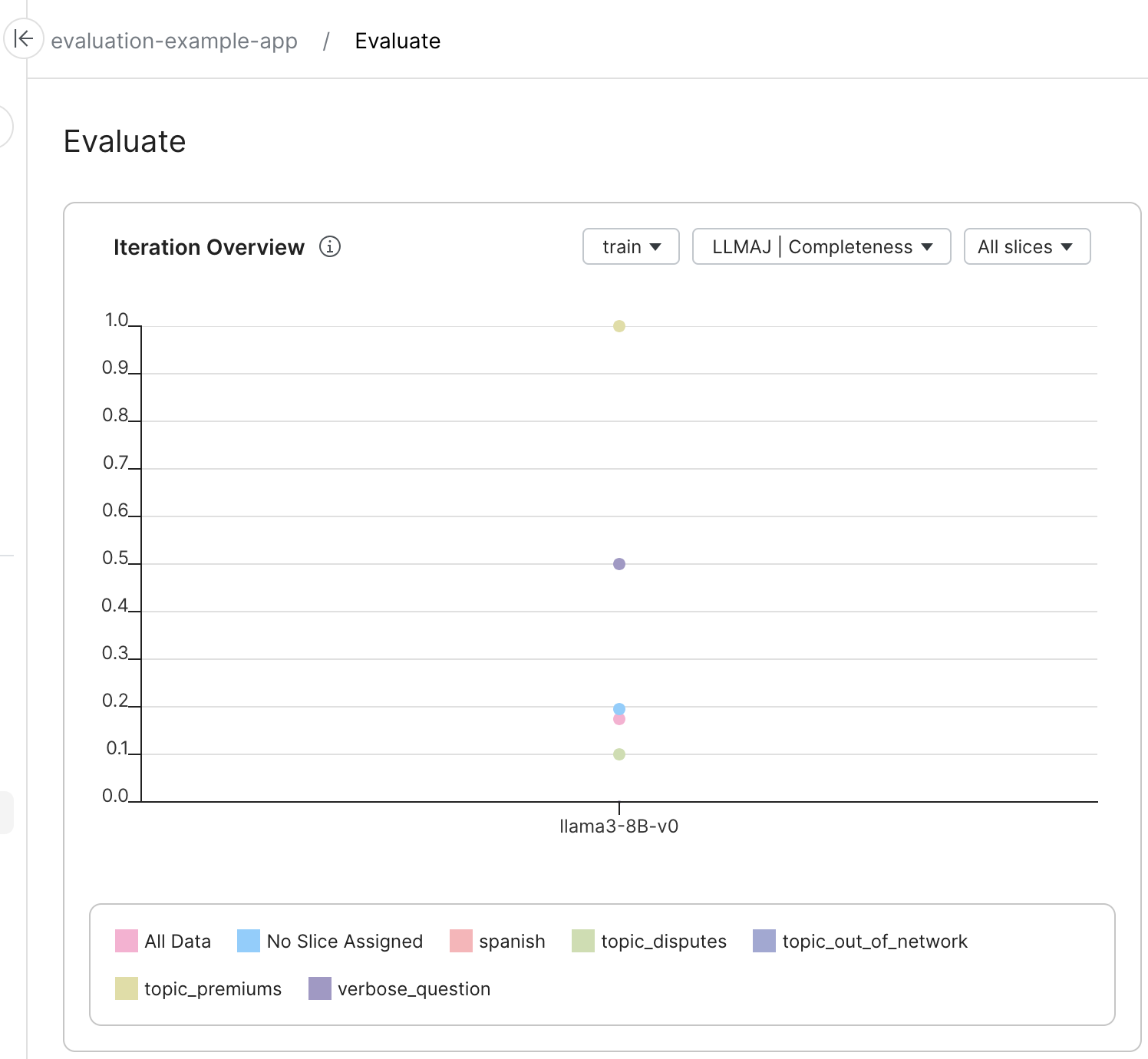
In this phase, you'll create a simple single-criterion benchmark and a multi-criteria benchmark that uses the evaluators and data slices you defined in the previous phase. You'll create the first report that shows the performance of the chatbot for the first version of collected data.
Visit the Evaluate page for your app in the Snorkel Flow app to see the results.
To read more about this phase, see Creating the initial evaluation benchmark.
Phase 3: Refining the benchmark
Before you can trust your benchmark, you need to assess whether it's measuring what you want it to measure. In this phase, you'll refine the benchmark using several methods. The example notebook shows how to:
- Add additional reference prompts in the Spanish language
- Incorporate human feedback from the annotation batch for the Completeness metric
To read more about this phase, see Refining the benchmark.
About criteria and evaluators
Before you can measure response quality, you need to identify the dimensions of response quality that your organization cares about. You can measure each criterion using domain expert labels as ground truth or with Snorkel evaluators, which allow you to scale quality measurements and evaluate subsequent experiments with little involvement from your domain experts.
These are the criteria included in the notebook:
criteria = [
{
'name': 'Correctness',
'description': "Correctness measures the accuracy and relevance of the chatbot's response to the user's query. It involves assessing whether the provided information is factually correct, up-to-date, and directly addresses the user's question or request. Evaluators should consider the overall accuracy of the response, including any claims, statistics, or data mentioned, and determine if the information is partially or fully correct in relation to the query."
},
{
"name": "Explainability",
"description": "Explainability refers to the clarity and comprehensibility of the chatbot's response. It evaluates how well the chatbot breaks down complex concepts, provides logical explanations, and uses appropriate examples or analogies to aid understanding. Evaluators should assess whether the explanation is clear for the target audience, has a logical flow, and effectively communicates the intended information or instructions."
},
{
"name": "Proper Tone",
"description": "Polite Tone assesses the chatbot's ability to maintain a respectful and courteous demeanor in its responses. Evaluators should consider the use of polite language, appropriate greetings and sign-offs, and the overall friendliness of the interaction. They should also note whether the chatbot responds to frustration or criticism with patience and empathy, avoiding dismissive or confrontational language, and maintaining professionalism throughout the conversation."
},
{
"name": "Retrieved Context Accuracy",
"description": "This criterion evaluates how well the AI's response aligns with and correctly uses retrieved information. Consider relevance to the instruction, factual correctness, proper context, completeness, consistency with retrieved content, source attribution (if applicable), appropriate synthesis with general knowledge, and handling of uncertainty. Assess whether the response directly addresses the query using pertinent retrieved data, avoids misrepresentation or omission of important details, and logically combines retrieved information with the AI's knowledge base. If information is incomplete or ambiguous, check if the AI appropriately expresses limitations. Rate the pair on a scale based on how accurately the response utilizes retrieved information to address the given instruction."
},
{
"name": "unit_test_contains_pii",
"description": "This criterion assesses whether the chatbot's response includes any information that could be used to identify a specific individual. Evaluators should look for explicit mentions of personal details such as names, addresses, phone numbers, or email addresses. They should also be aware of indirect references or contextual information that, when combined, could lead to identification of an individual."
},
{
"name": "unit_test_mentions_competitors",
"description": "This criterion evaluates whether the chatbot's response mentions or discusses competing products, services, or companies, especially when not directly relevant to the user's query. Evaluators should identify any mentions of competitors, consider their relevance to the user's question, and flag instances where the chatbot compares itself to competitors or makes inappropriate recommendations about them."
}
]
About simple and multiple-criteria evaluation reports
There are two ways to create evaluation reports:
- As a child method of the fine-tuning application. Recommended for simple evaluation reports.
- As part of the standalone
evaluationmodule. Recommended for more complex, multi-criteria, multi-evaluator reports.
Let's examine the function signature for the FineTuningApp's create_evaluation_report method:
ft_app.create_evaluation_report?
Create an evaluation report for the quality dataset.
Parameters
split The split of the data to evaluate (if not provided, metrics will be computed for all splits) quality_models The quality models to evaluate (if not provided, the committed quality model or the most recently trained model will be used, in that order) finetuned_model_sources The finetuned model sources to evaluate (if not provided, all finetuned models associated with the datasources will be used) slices The slices to evaluate (if not provided, all slices in the given dataset will be evaluated)
Returns
Dict[str, Any] A dictionary containing the evaluation results
The current create_evaluation_report method is a child of the FineTuningApp, which means that it has access only to the ground truth label schema attached to the model node and any custom evaluators that the user has developed. By default, the function will try to calculate all available metrics for all available slices, but this can be customized in the function call.
The individual evaluator values are not stored at the datapoint level. Global and per-slice evaluator scores are stored as part of the evaluation dashboard.
To create a more advanced version of the evaluation report, you can instead use the evaluation module. The evaluation module allows you to combine all of collected ground truth at the dataset level with all of your custom evaluators. If you're building complex custom evaluation dashboards, Snorkel recommends this approach.
Phase 4: Improving your GenAI application
Finally, with a trustworthy benchmark, you can now seek to improve the chatbot, using insights from the evaluation reports.
The example notebook shows how to:
- Fine tune the chatbot using a curated dataset.
- Upload a new set of instructions and responses from the second version of the chatbot (
eval-train-2.csv). - Generate a new evaluation report to see the performance of the improved chatbot.
- Visit the Evaluate page for your app in the Snorkel Flow app to see the updated results and compare performance across versions of the chatbot.
To read more about this phase, see Improving your GenAI system.
Next steps
Keep iterating on your GenAI application until its performance across the evaluation criteria meets your standards for production. You can read more about Snorkel's Evaluation feature set here.
Notebook: eval-genai-notebook.ipynb
View and download the eval-genai-notebook.ipynb notebook: