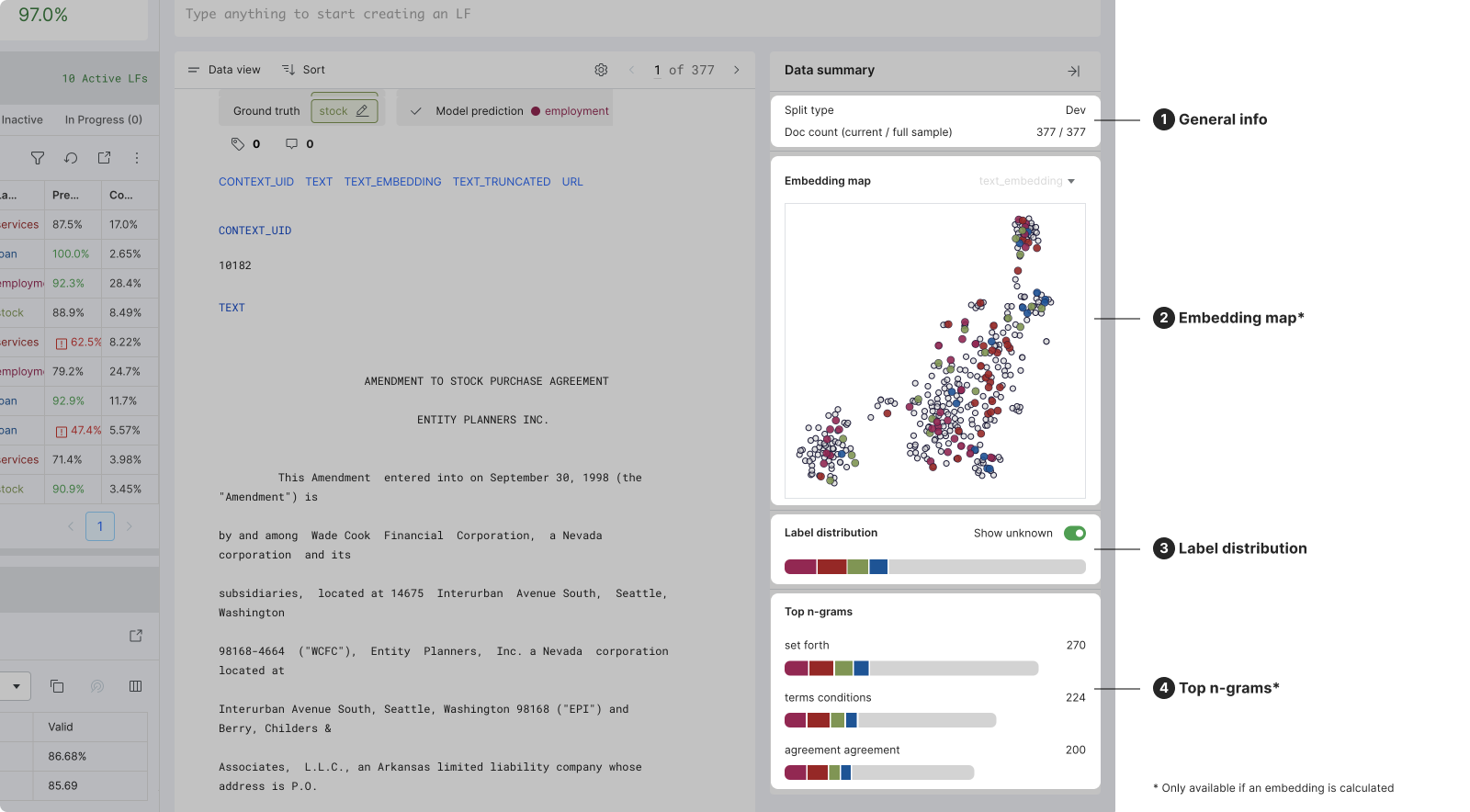
Dataviewer: Data summary pane
This page walks through the functionality and information that is provided the data summary pane.
The data summary section provides aggregated information of all data points currently in view in the data content section.
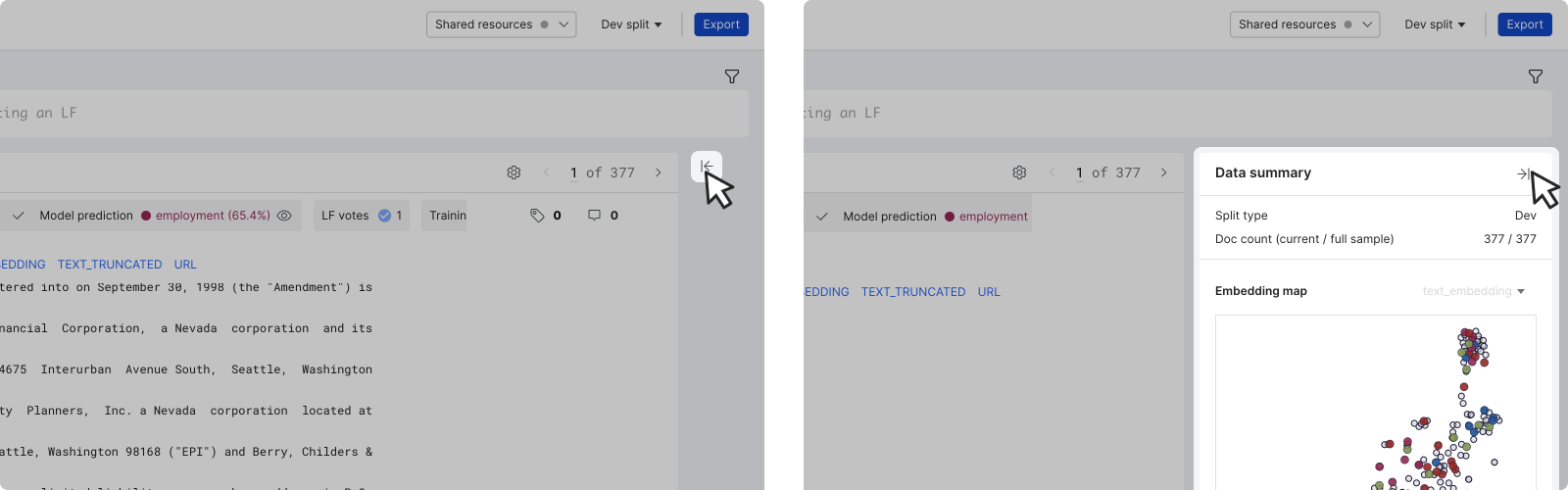
To open the data summary pane, click the arrow button to the right of the data content section. To close the pane, click the arrow button on the top right corner of the pane.
Ensure that the Data Summary is selected in the drop down menu.
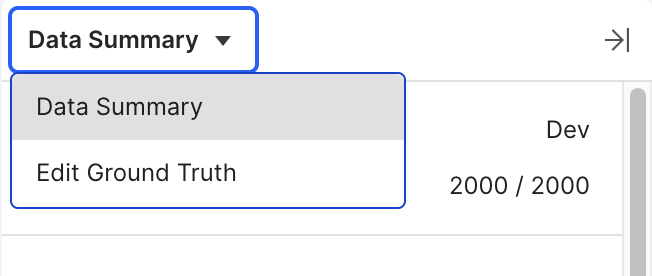
In this pane, you also have the ability to edit ground truth and update the label schema. See Ground truth annotations and Updating the label schema for more information.
The data summary includes the following information:
- Split type: The split of the data (i.e., Dev, Train, Valid, or Test).
- Doc count: The number of documents that are currently in view in the data content section versus the total number of documents in the sample. You can use filters to drill down into a subset of the total documents.
- Embedding map: If available, the map of the selected embedding cluster LF.
- Label distribution: The distribution of the labeled data points
- Top n-grams: If available, the top n-grams of the selected embedding cluster LF. N-grams are sequences of words or tokens that appear frequently in your documents.
The Embedding map and Top n-grams are populated only when embeddings are computed for your data. See Utilize Embeddings for more information.