GenAI Evaluation workflow overview
Evaluation for GenAI output is inherently challenging because GenAI model responses are varied and context-dependent.
For example, let's say that you are evaluating a chatbot prototype for external release. The chatbot is supposed to answer questions about different health insurance plans that your company offers. You likely have a set of sample answers from internal testing that you need to evaluate, and the answers are likely quite varied. This example use case is explored in detail in the Evaluate GenAI output tutorial.
An evaluation process that can drive meaningful business decisions and improvements about a GenAI model must be:
- Specialized: Because the potential output of a GenAI model is so varied and context-dependent, evaluation must be customized to suit the specific use case.
- Fine-grained: Evaluations should be detailed and focus on individual criteria that matter.
- Actionable: The results of the evaluation must provide insights that lead to improvements in the model.
Without a structured evaluation framework, it's difficult to assess model performance accurately or improve it effectively. Snorkel applies these principles in our evaluation workflow to provide a comprehensive and flexible system to continuously monitor, test, and improve AI models, making them reliable tools for enterprise applications.
Snorkel's evaluation framework provides a quick start with smart defaults so you can get an initial evaluation immediately. As your evaluation needs evolve, Snorkel's evaluation suite enables you to craft a more powerful and customized benchmark within the same workflow.
Workflow
Snorkel's evaluation framework follows four phases:
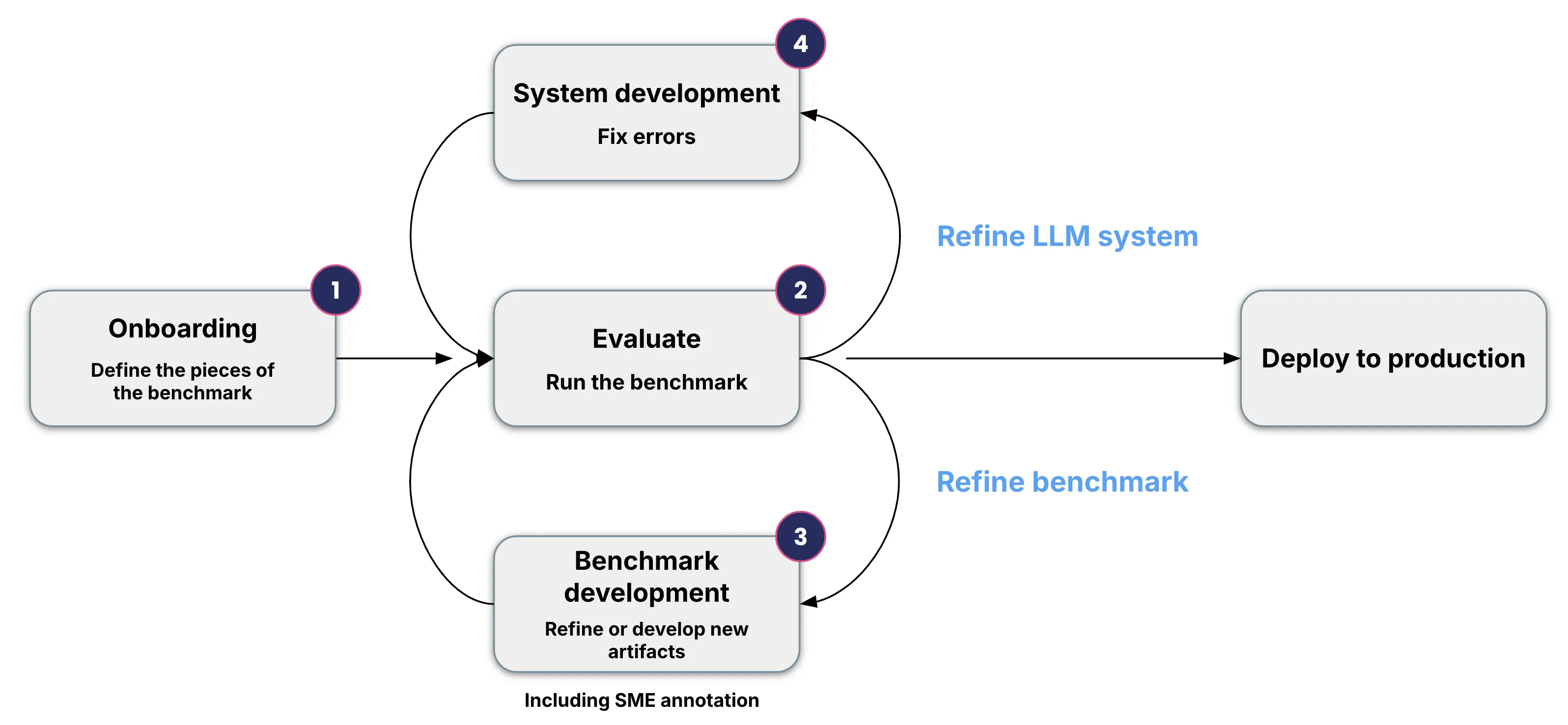
Read a summary of the evaluation workflow below, or dive into the details of each step by following the links:
- Onboarding artifacts: Set up the benchmark by defining artifacts, which can be customized: criteria, reference prompts, data slices, and evaluators. For access to our smart defaults on the evaluation criteria, evaluators, and slices, contact your Snorkel representative.
- Creating the initial evaluation benchmark: Run the evaluation, leveraging programmatic labels and fine-grained analysis to assess the model’s performance across various dimensions.
- Refining the benchmark: Refine the existing artifacts and gather ground truth labels from subject matter experts to validate and improve existing artifacts.
- Improving your GenAI system: Refine the LLM system through prompt development, RAG tuning, or LLM fine tuning.
This structured process allows AI systems to be reliably tested and refined before being deployed in enterprise environments. By following this process, enterprises can ensure that their GenAI models are aligned with critical business needs and standards.
Tutorial
To follow along with an example of how to use Snorkel's evaluation framework, see the Evaluate GenAI output tutorial.