Sequence LF builders
This article describes the set of builders that are available for sequence tagging applications (see the Sequence tagging: Extracting companies in financial news articles tutorial).
Sequence context builder
Label tokens based on the text surrounding a regular expression pattern. This labels the specified number of tokens if they are [LEFT], [RIGHT], or [LEFT OR RIGHT] of the provided pattern.
You can combine the “Show LF Votes” button and the “View [In]Correct” filter to see which tokens are being labeled by this LF.

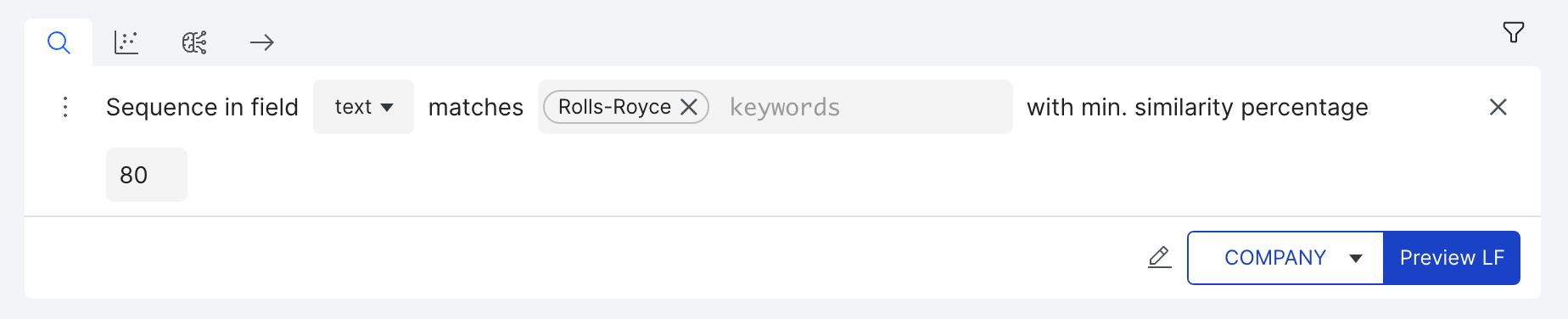
Sequence fuzzy keyword builder
Label tokens that are similar to one or more of the list of keywords (max of three) you provide, within the specified similarity ratio using the SequenceMatcher library. This is particularly useful for documents obtained through OCR.
Sequence keyword builder
Label a sequence of one or more tokens that match any words or phrases you provide.
The Sequence Keyword builder allows a maximum of three (3) keywords/phrases per builder. To add more, you can * combine additional Sequence Keyword Builders using OR, * or use the Sequence Entity Dict Builder.

Sequence substring expansion builder
If a token [matches] the whole value, [contains] the value in it, [starts with], or [ends with] the value, then specify the class to vote for. The value can be toggled as regex or not.

Sequence spaCy prop builder
This LF builder incorporates the spaCy properties of tokens for labeling them.
Prerequisite
In your DAG, add a SpacyPreprocessor node before the Model node to create spaCy properties for your data. The SpacyPreprocessor “Field” and “Target field” values are text and doc, respectively.
Label tokens that satisfy these conditions:
- The tokens in this spaCy field (
doc). - Is tagged with any
SPACY_TAGS, such asVERBorADJfor part-of-speech tags. For a complete list of tags, see the spaCy glossary
The dropdown has commonly used spaCy tags. If you have added any other spaCy tags in your application, add these as free text.
The data viewer in the spaCy field shows any tags you added. For example, the spaCy field doc in the data viewer shows custom tags NNP, IN, NNPS, and _SP:

Advanced option: You can specify the spaCy properties that fit your use case. Snorkel Flow supports POS (part-of-speech), DEP (dependencies), and TAG.
Example
If the tokens are tagged as VERB or ADJ under POS part-of-speech tags, they are not likely company names. We can label these tokens as OTHER.

Sequence NER builder
This LF builder incorporates the named entity recognition resources for labeling spans.
Label spans that satisfy these conditions:
- The spans in this field (
NER field) - is tagged with any of (
NER properties)
Prerequisite: In your DAG, add a SpacyPreprocessor node before the Model node to create Spacy properties for your data. The SpacyPreprocessor takes the your text field as “Field” and outputs “Target field” as doc, in this case, select NER field as doc. Alternatively, add a custom featurizer in the DAG to add NER field with the following format:
NER field for text Apple is looking at buying U.K. startup for $1 billion is a JSON dictionary with “ents” as key, and value is a list of entities; Each entity is a dictionary with ‘start’, ‘end’ and ‘label’ as keys.
Note
{
"ents": [
{'start': 0, 'end': 5, 'label': 'ORG'}, # Apple
{'start': 27, 'end': 31, 'label': 'GPE'}, # U.K.
{'start': 44, 'end': 54, 'label': 'MONEY'}, # $1 billion
]
}
If the spans are tagged as ORG, they are likely company names. We can label these spans as COMPANY. In this example, “Apple” would be labeled as COMPANY.

Sequence entity dict builder
Label all tokens containing patterns from a dictionary provided through a JSON file.
Only the values of the JSON are used by the labeling function; the keys can be used for organizational purposes, but are otherwise ignored. See the example below for reference.
Label tokens that satisfy these conditions:
- The tokens in this field (
text) - Contains the patterns from this file (
file_path)
Note
Example
Our JSON file maps Fortune 500 stock tickers to company name aliases. The keys (stock tickers) are ignored for the purposes of this labeling function. If any of the values in the JSON match a span in the document, we label the matched tokens as COMPANY. Here is an example of the JSON file: s3://snorkel-workshop-data/financial-news/f500_ticker_key_fixed.json
{
"WMT": [
"Walmart",
"www.walmart.com",
"Wal Mart Stores Inc"
],
"XOM": [
"Exxon Mobil",
"www.exxonmobil.com",
"Exxon Mobil Corp"
],
...
}
The location of the JSON file needs to be an S3.

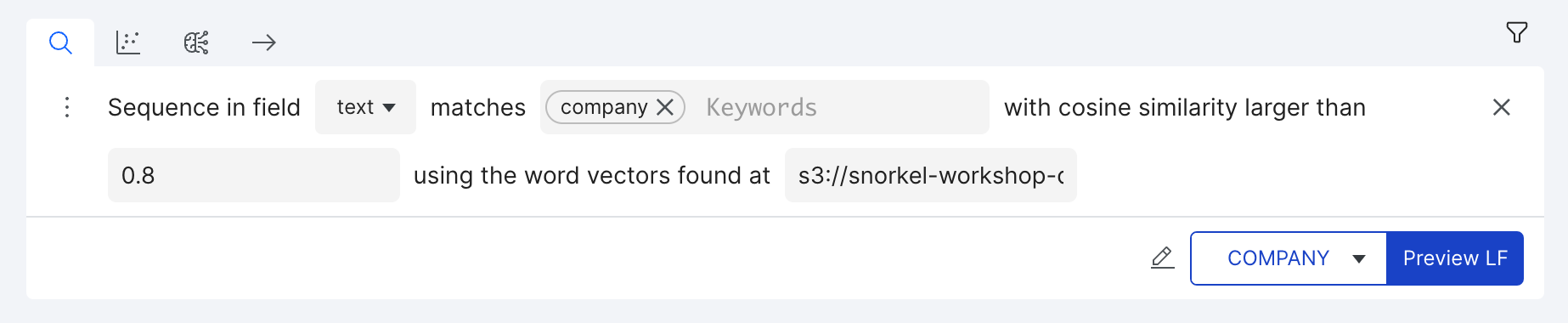
Sequence word vector builder
Label all tokens with a cosine similarity score greater than or equal to the provided threshold. This score is calculated between the associated word vectors loaded from the provided file path.
- Keywords - The keywords that will be compared to the tokens within the text field
- Cosine Similarity - Indicates the threshold at which a token will be considered similar enough to one of the keywords so as to be labeled. A score of 1.0 represents an identical word. Typical scores for matching are in the 0.4 to 0.8 range.
- Word Vector Path - Indicates the S3 or MinIO path to a file containing pre-trained word vectors. This file should be formatted such that each line contains a single token followed by the vector values delimited by spaces.
Note
Sample word vector file format for 4-dimensional vectors: scale 0.96014 -0.18144 0.22938 0.28215 solution 1.1908 0.23095 -0.169 0.043158 banking 0.17391 -0.69398 0.11051 0.7731 ...
Sequence letter case builder
Vote the class of a token based on whether it’s lowercase, uppercase, or fully capitalized. By default, this LF uses the regex \b word boundary to tokenize. You can set the Word Boundary Tokenizer to off under the advanced menu, which will use a spaCy tokenizer instead.
The nearby tokens are merged by default; you can turn off Merge Nearby Tokens under the advanced menu, which will vote on individual tokens.
