Rich document LF builders
If your application utilizes rich document structure (see the Extraction from PDFs: Extracting balance sheet amounts tutorial), the following LF builders are available. These builders support heuristics based on structural characteristics of the document with respect to the span.
Rich document expression builder
Label data points by evaluating the given expression. The expression uses Python syntax, and can reference any dataframe columns, as well as special variables SPAN (representing the span) and PATTERN1, PATTERN2, and so on (referencing the first match for each given regex). The special variables have properties top, bottom, left, right, center, middle, page_id, line_id, par_id, row_id, char_start, char_end, text. If any of the regex patterns has no match, the LabelingFunction will abstain.
In the example below, the LF has regex patterns ["Fair", "[Vv]alue"] and expression PATTERN1.top <= PATTERN2.top and PATTERN1.top > PATTERN2.top - 100 and SPAN.left > PATTERN1.left - 100 and SPAN.right < PATTERN1.right + 100 and SPAN.top > PATTERN1.top. It will find documents that have the words Fair and Value (or lowercase value) with Fair not too far below Value, and label spans that are roughly below Fair.
This builder can also be used for PDF classification applications, but without the special SPAN variable.
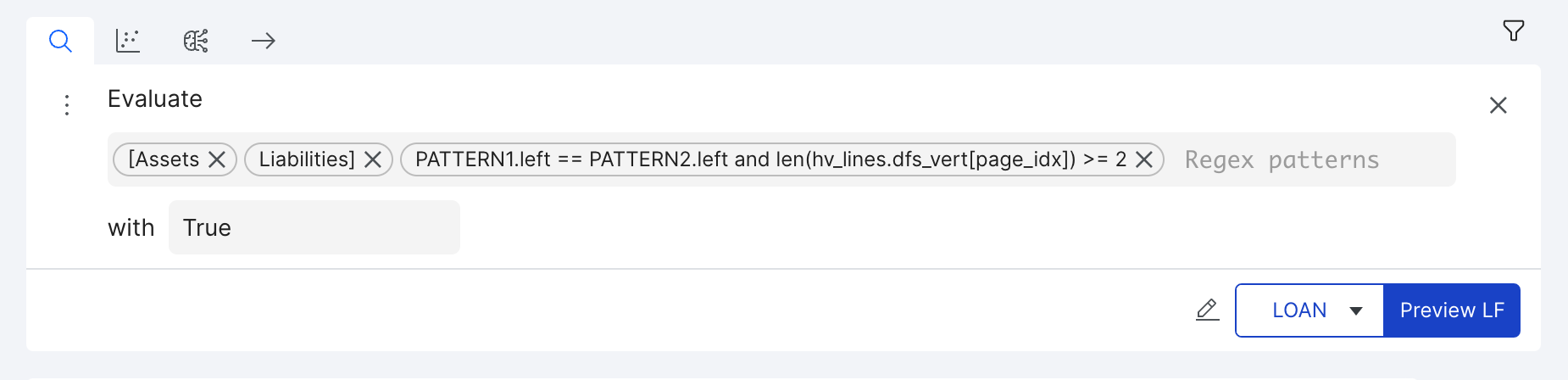
For example, consider the LF with patterns ["Assets", "Liabilities"] and expression PATTERN1.left == PATTERN2.left and len(hv_lines.dfs_vert[page_idx]) >= 2. This matches any page with Assets and Liabilities in the same column (vertically aligned), AND at least 2 vertical lines (suggesting the presence of a table). This LF could be used to identify whether a document is a balance sheet in a document classification task.
Additional Examples
-
Label any span whose
bottomis within 10 pixels of the patternTerm- Patterns:
Term - Expression:
abs(PATTERN1.bottom - SPAN.bottom) < 10
- Patterns:
-
Label any span whose
bottomis 10 pixels above the patternTermand hasImpin it’s text.- Patterns:
Term - Expression:
PATTERN1.bottom < SPAN.bottom + 10 and 'Imp' in SPAN.text
- Patterns:
-
Label any span whose lowercase text is
creditand whose document hasTermin the first 1000 pixels.- Patterns:
Term,Credit - Expression:
PATTERN1.bottom < 1000 and PATTERN2.text.lower() == SPAN.text.lower()
- Patterns:
-
Label any doc which has
Termin the first 1000 pixels of the first page- Patterns:
Term - Expression:
PATTERN1.bottom < 1000 and page_index == 0
- Patterns:
Rich document bounding box
Label documents based on the existence of a given regular expression at a specific location in the page. The bounding box coordinates can be found by hovering the cursor over the words in the Data View. In the example below the LF checks if regex pattern “Loan.15Agreement” lies within a bounding box defined by coordinates “0, 0, 2400, 1000”. We compare all occurences of the regex pattern with the coordinates. This builder can only be used for Rich Doc classification applications.

Span regex proximity
Label data points based on the existence of a given regular expression in their vicinity. This checks if the span is within some number (called the window size) of units (lines/paragraphs/areas) in a specified direction (before, after, or either direction) of the specified regex. If the window size is 0, only text in the span’s own line/paragraph/area will be considered.
In the example below, this LF labels the 8 spans that are up to 4 LINES after the regex pattern Current Assets: as ASSETS.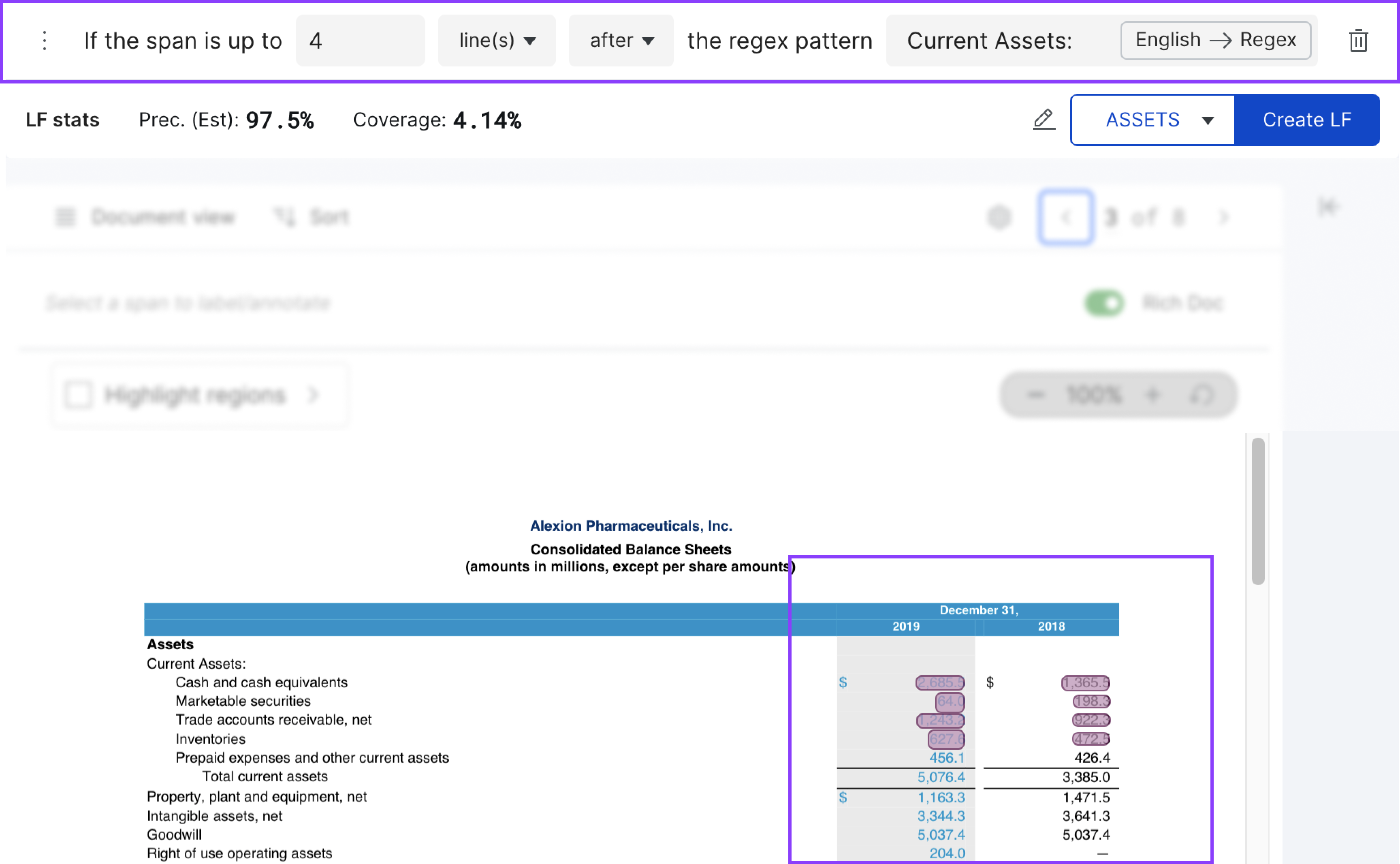
Span regex alignment
Label data points based on whether or not a given regular expression is aligned with the span in some way. Select a location (LEFT / CENTER / RIGHT / TOP / MIDDLE / BOTTOM) to compare between the bounding box of the span and the boundings boxes of any matches for your regular expression. Also select a threshold for how close the two coordinates need to be to be considered aligned. This comparison can be made in PIXELS or PAGE_PERCENT, a percentage (0-100) of the page’s total width/height, depending on which dimension is relevant for the given location. You may also optionally limit matches to the specified scope of the Span, and/or in only the given direction (e.g., if your threshold is 100 pixels, location is TOP, and threshold direction is UP_ONLY, then only matches whose top boundary are within 100 pixels above (not below) the Span on the page will be matched. If no threshold direction is specified, then matches within the threshold are allowed in both directions (LEFT and RIGHT, or UP and DOWN).
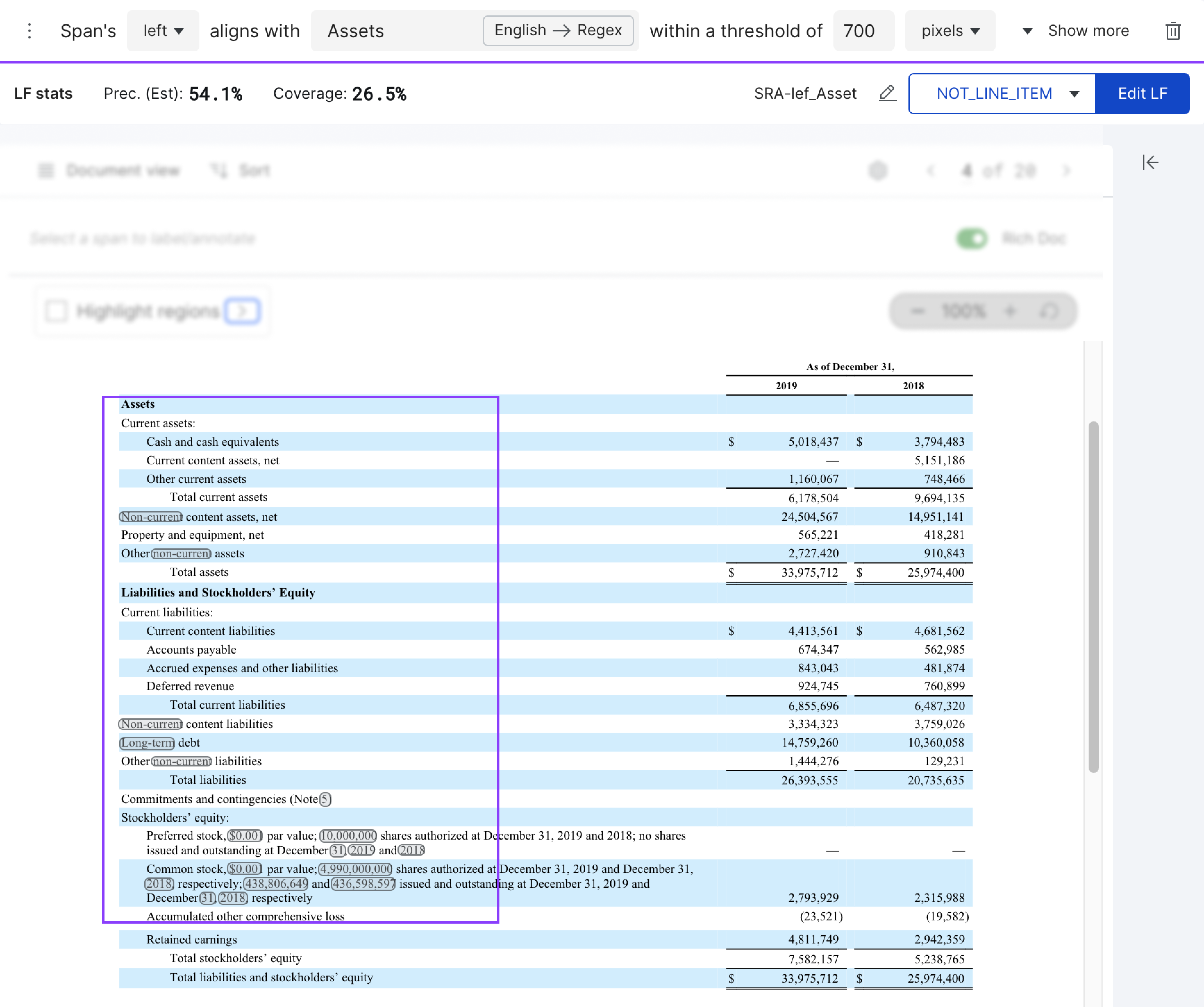
As is the example below, this LF labels the spans whose LEFT aligns with the regex pattern Assets (case-sensitive), within a margin of 700 PIXELS, as INVALID. These spans are highlighted in grey in the figure.
Span regex row (Rich-document based LFs)
Label data points based on whether or not the span is within a certain number of rows of a given regular expression. Set rows before and rows after to specify the window of rows to search, relative to the span’s current row. If both rows before and rows after are set to 0 only spans in the same row, that match the regex pattern, will be labeled.
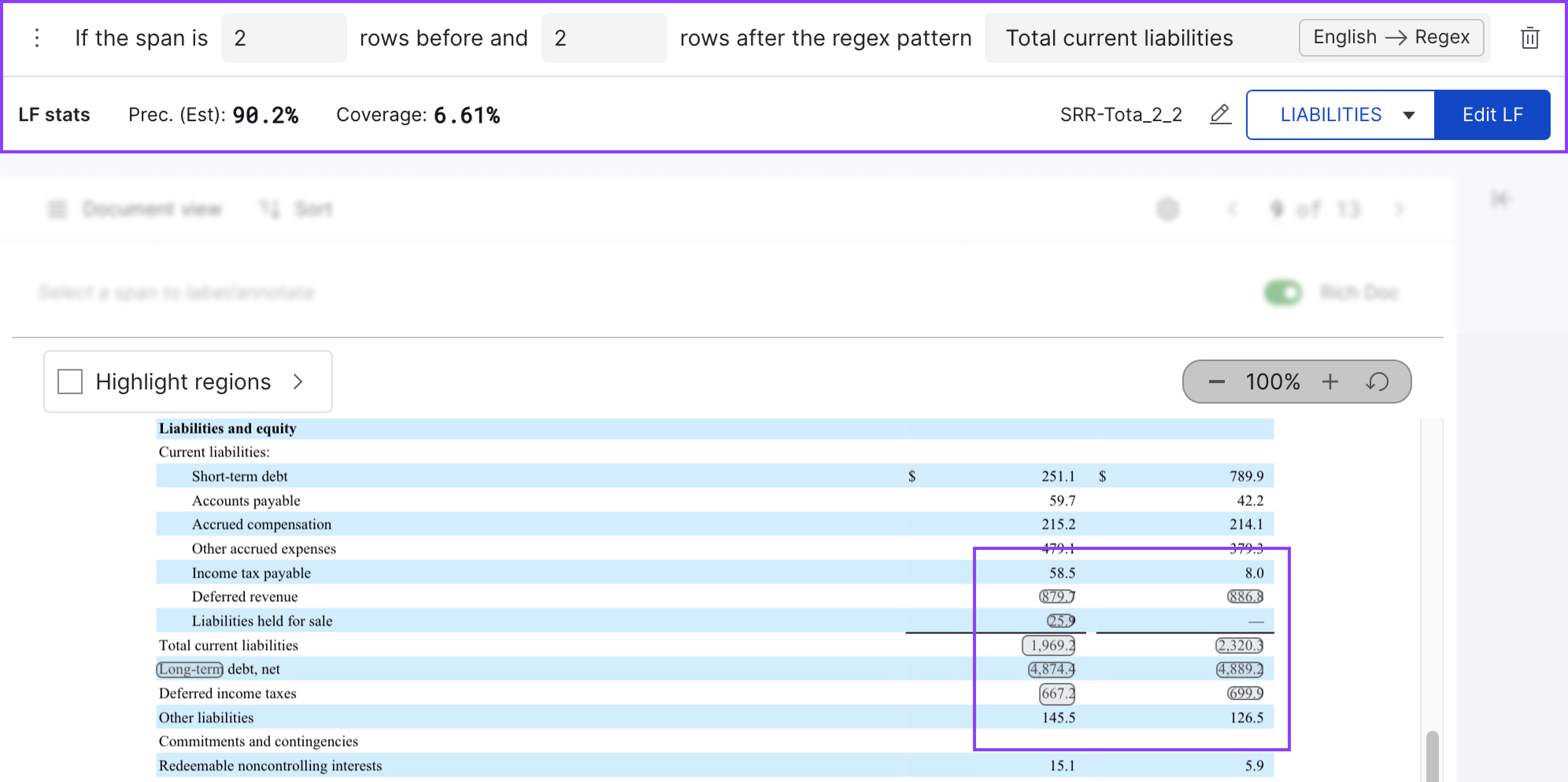
In the example below, this LF labels the 10 spans that are at most 2 rows before or 2 rows after the regex pattern Total current liabilites as LIABILITIES.
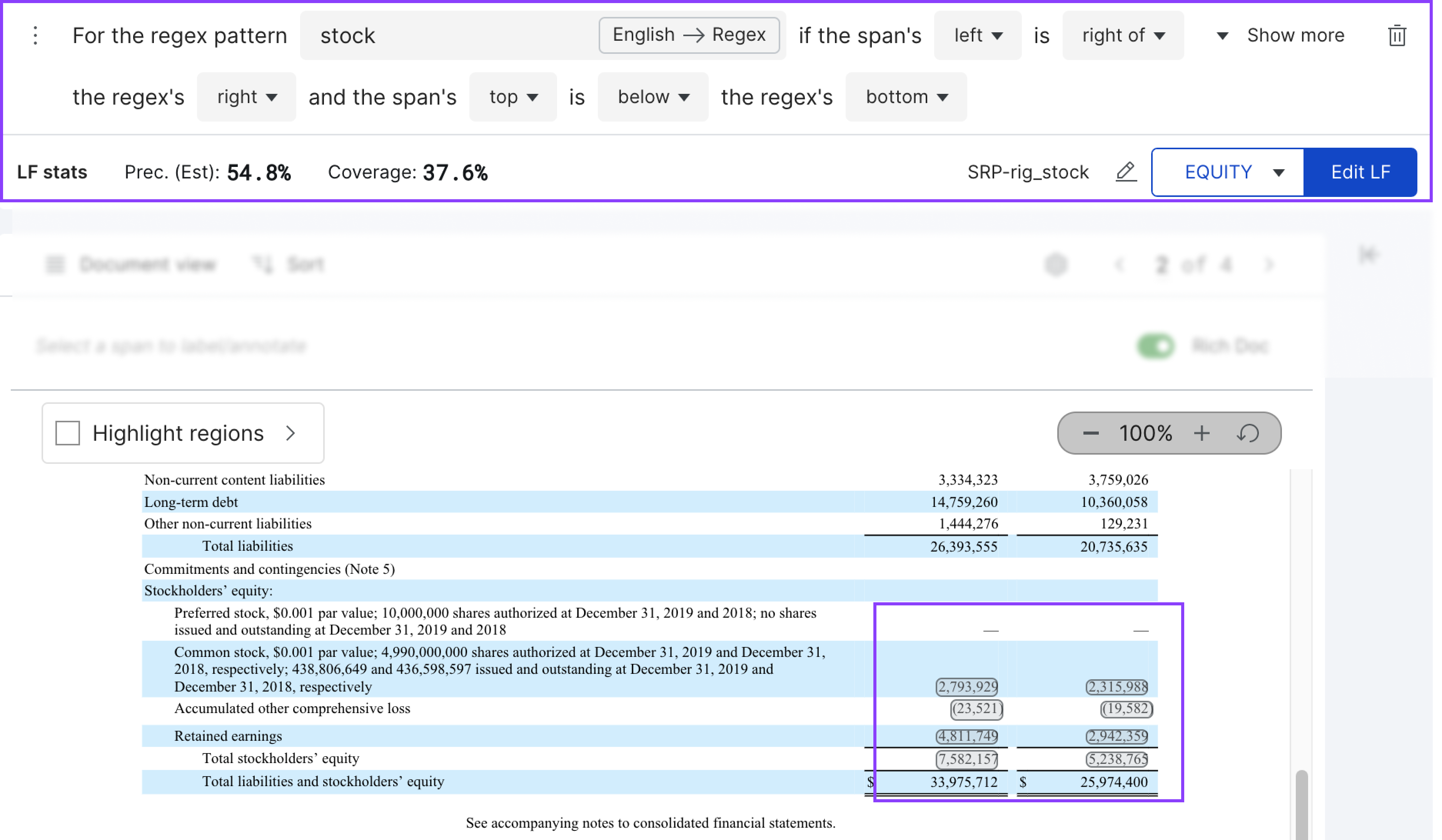
Span regex position
Label data points based on whether the span is at a specific direction with respect to the given regular expression. Select two location attributes (LEFT / CENTER / RIGHT / TOP / MIDDLE / BOTTOM) of the span to compare with two location attributes of any matches to the regular expression. You may optionally select the scope of the comparison (PAGE / AREA / PARA / LINE). You can enable only the first, only the second, or both conditions under the Advanced options.
In the example below, this LF labels 14 spans that lie below and to the right of the regex pattern stock as EQUITY.
Span page
Label data points based on the page number of the given span, using 1-indexing (the first page of the document is considered page 1, not page 0).

Span font size
Label data points based on the font size of the given span (in pixels, not points), based on the value reported in the hOCR.
