Introduction to search based LFs
Writing a labeling function (LF)
Navigate to the Pattern based search workflow LF composer tab and type anything into the search bar to start writing a labeling function. Each application comes with a list of recommended builders that you can choose from.

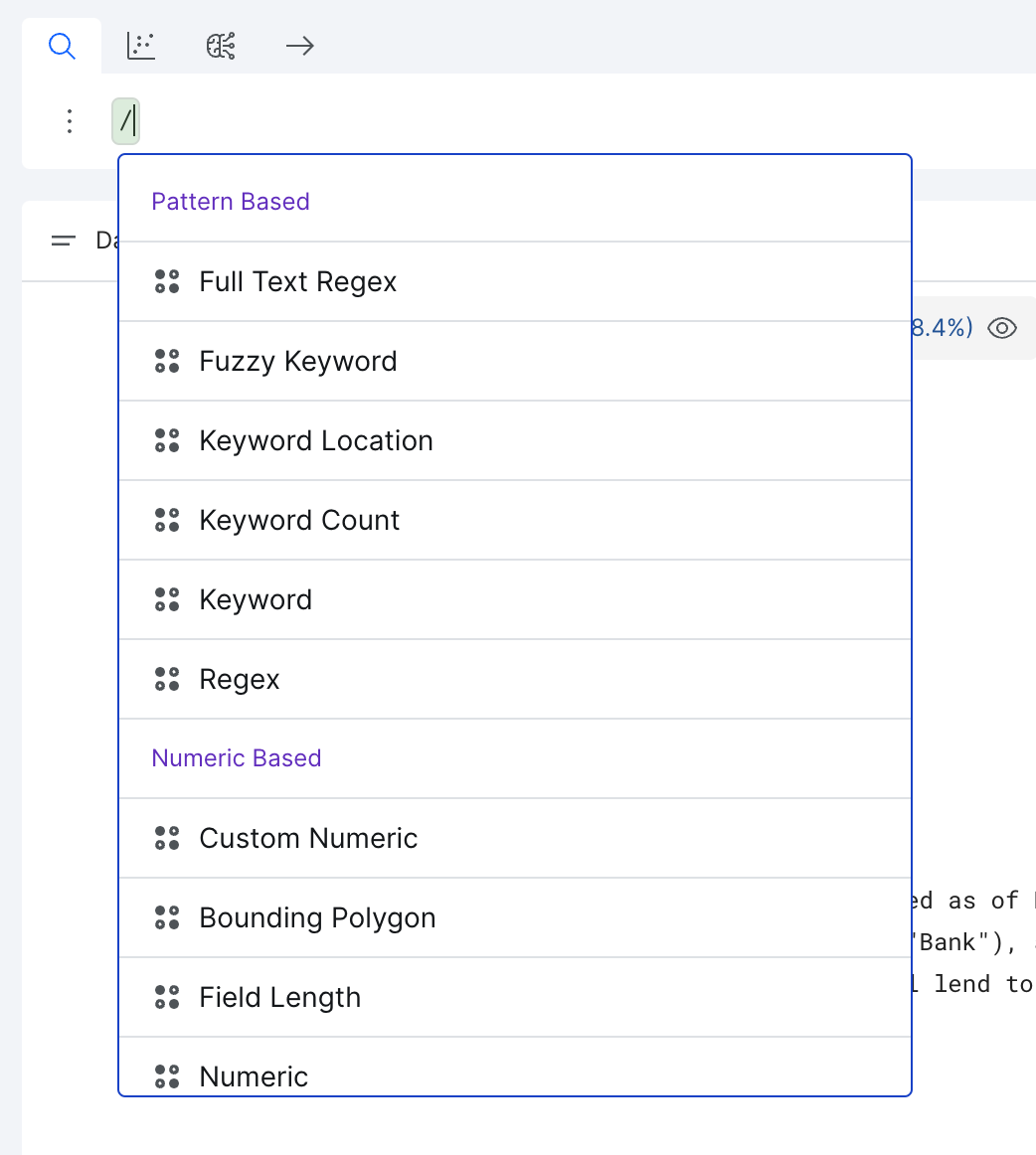
To view all builders available in the application you're working on, type / into the search bar and select a builder type.
Click on Preview LF to preview your LF, located in the bottom right of the search bar.

Preview LF will return results indicating where your draft LF will vote. The Preview LF button have now become the Create LF button.
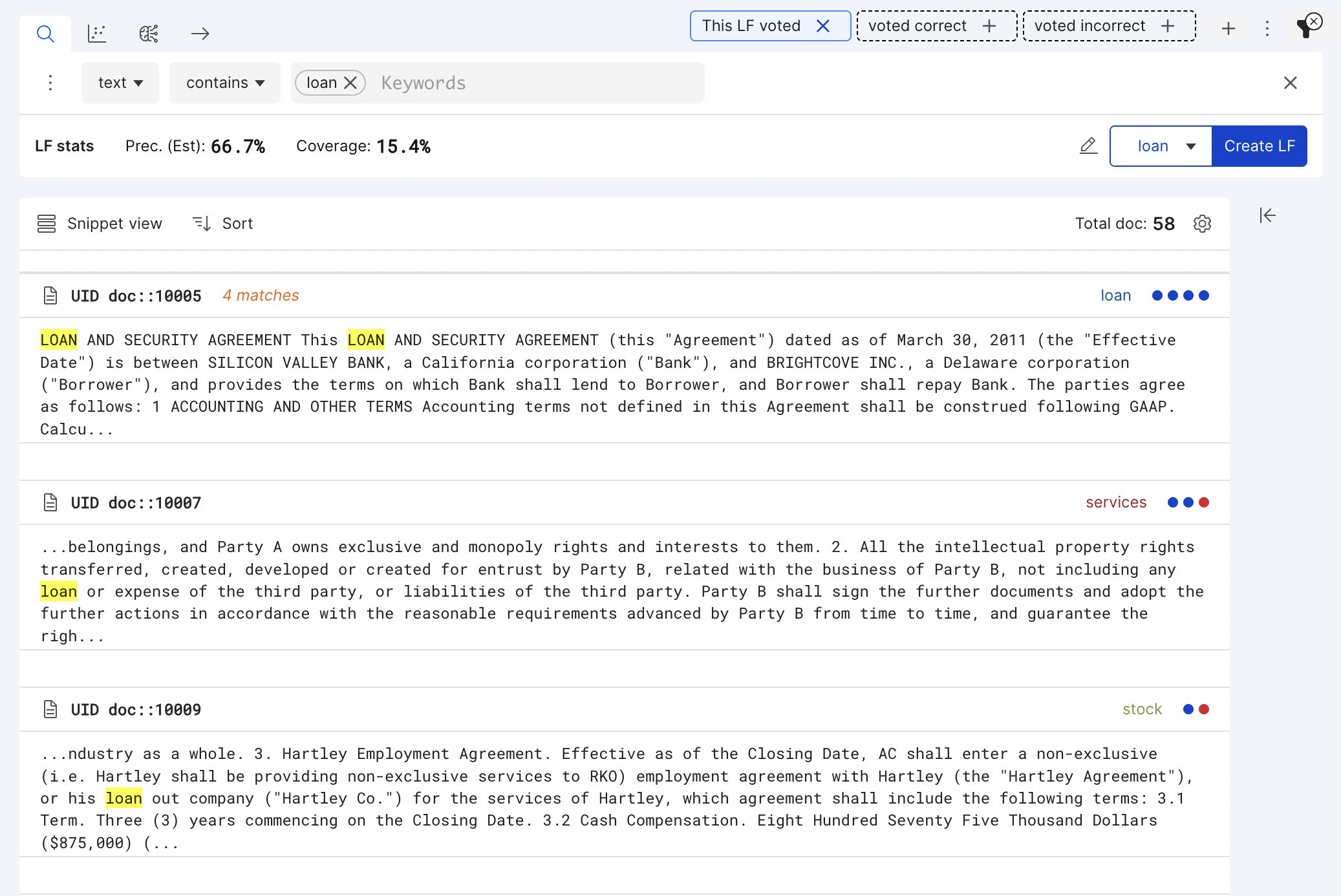
Once you’re done previewing and refining your draft LF, click Create LF. The search bar will clear, and your labeling function will appear in the Active LFs list under the LF summary section.

Understanding labeling function (LF) metrics
Preview LF metrics via LF composer
When previewing an LF you will see the following information displayed in LF composer:
- Prec. (Est): The estimated precision of the previewed LF based on correct votes relative to any GT and other LF signals. See LF summary for details.
- Coverage: The percentage of data points this LF votes on.
- voted correct filter chip: Apply a filter to show examples that were correctly voted on by this LF.
- voted incorrect filter chip: Apply a filter to show examples that were incorrectly voted on by this LF.

LF summary metrics
The Labeling Functions summary pane contains the following metrics (on the current split) that can be accessed via the Columns icon in the top right corner:
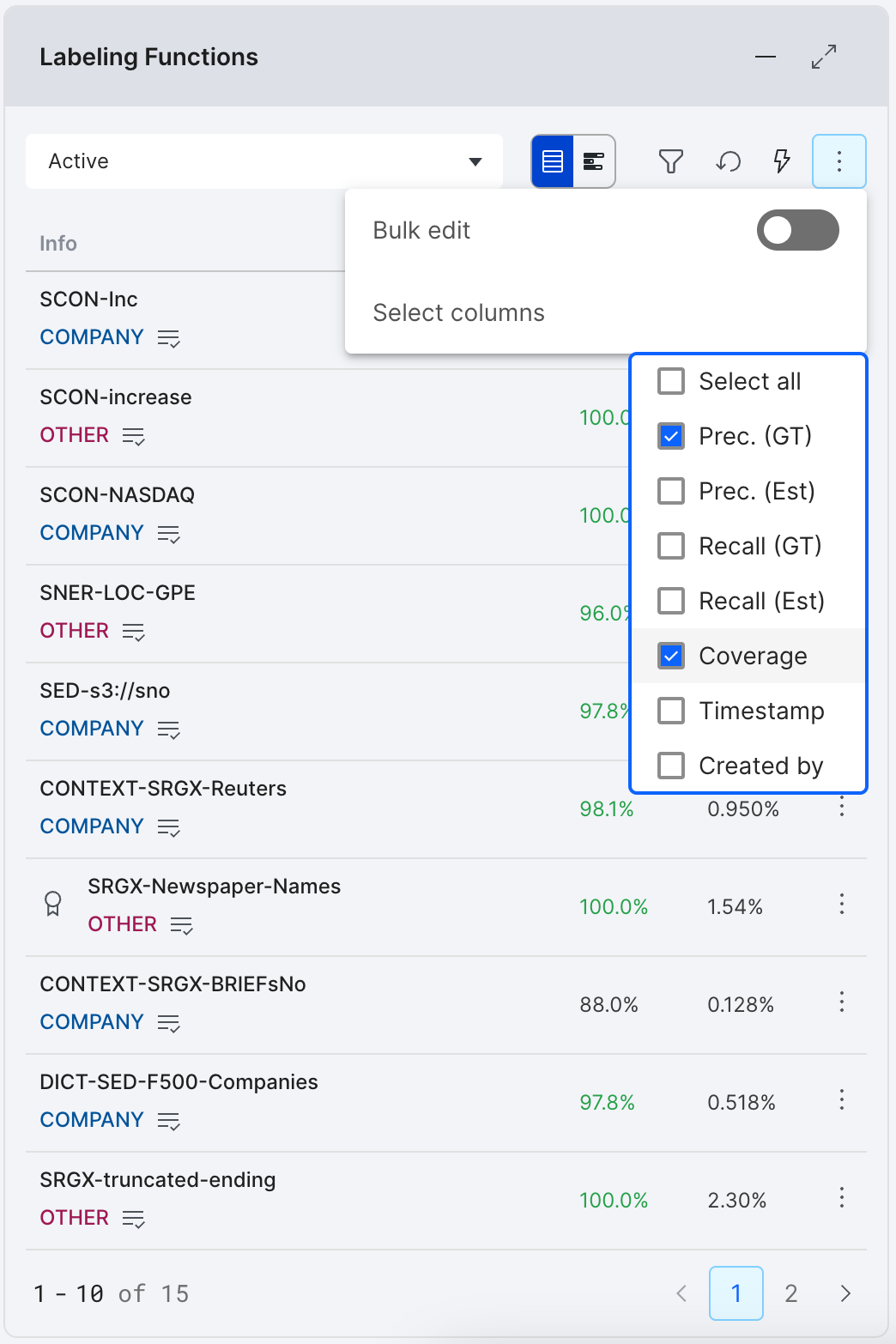
-
Labels: The label assigned by the labeling function
-
Voted (specific to the datapoint selected in Data Viewer tab):
- Gray ✓ voted, but not GT exists
- Green ✓ voted correctly based on assigned GT
- Red X voted incorrectly based on assigned GT
-
Precision (GT): The (number of correct LF votes) / (total number of LF votes), based on the existing GT labels. This is only an estimate based on a potentially very small dev set. The learned precision Snorkel Flow will use to generate probabilistic labels for data points won’t be calculated until a label package is created and can be viewed on the LF Packages page.
-
Precision (Estimated): The same as Precision (GT) but using estimated GT labels (based on LF votes) wherever manual GT labels do not exist. (Total LF votes for class in agreement with estimated GT labels) / (Total LF votes for class).
-
Recall (GT): The (number of correct LF votes) / (total number of examples in class), based on the existing GT labels.
-
Recall (Estimated): The same as Recall, but using estimated GT labels (based on LF votes) wherever manual GT labels do not exist. (Total LF votes for class in agreement with majority) / (Total majority votes for class).
-
Coverage: The percentage of data points in the current split that this labeling function votes on.
-
Count (GT): The total number of LF votes generated by this LF on the current split.
Additional labeling function (LF) functionalities
LF builder settings
Each LF will have additional configuration options available in the three-dot menu on the left side of the search bar. Clicking a active LF from the LF summary pane will also expose it in the search bar to access these options. These settings are "sticky"— they persist until for a specific user and application until they're changed.

-
Negate this builder: Only votes on data points that don't match the specified condition.
-
Advanced settings: Each builder has its own additional settings, and the most common advanced settings among them are:
- Case sensitive: if enabled, the texts should be treated case-sensitive. By default, all texts are case-insensitive.
- Regex: if enabled, the string you enter will be treated as regex.
-
Add another builder (and/or): enables you to add a new row to the search bar to combine different types of labeling function builders within one labeling function.
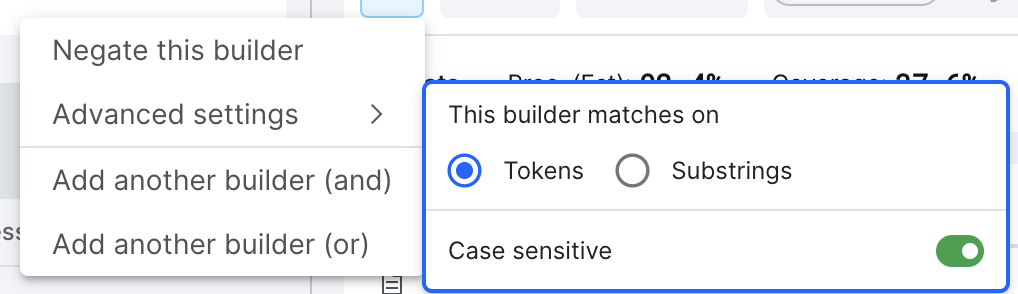
Keyword and Dictionary Builders have additional settings for how to match user-inputted words or phrases:
- Tokens: The builder will look to match the entire token (e.g., the entire word/phrase) and not vote on a label if the word or phrase appears as part of another complete word. Tokens are split on spaces.
- Substring: The builder will look to see if the word or phrase appears in the field, whether it’s a substring of another word or not.
Advanced LF options
Some LFs support advanced interactions like "autotune" for numeric LFs or "refresh" for dictionary LFs. To access these advanced configuration options, click the available buttons from any LF builder template that supports these options (see Numerical LF builders as an example).

Phrase match highlighting
For pattern-based LF builders, the matching phrases will be highlighted in the current data point in the Data view tab for doc-based applications and under the Span tab for span-based applications. Only the Keyword, Regex, and Span Context builders currently support this.
LF settings
For each labeling function, there are a few settings available in the three-dot menu to the left of each saved LF row in the Active LF list.
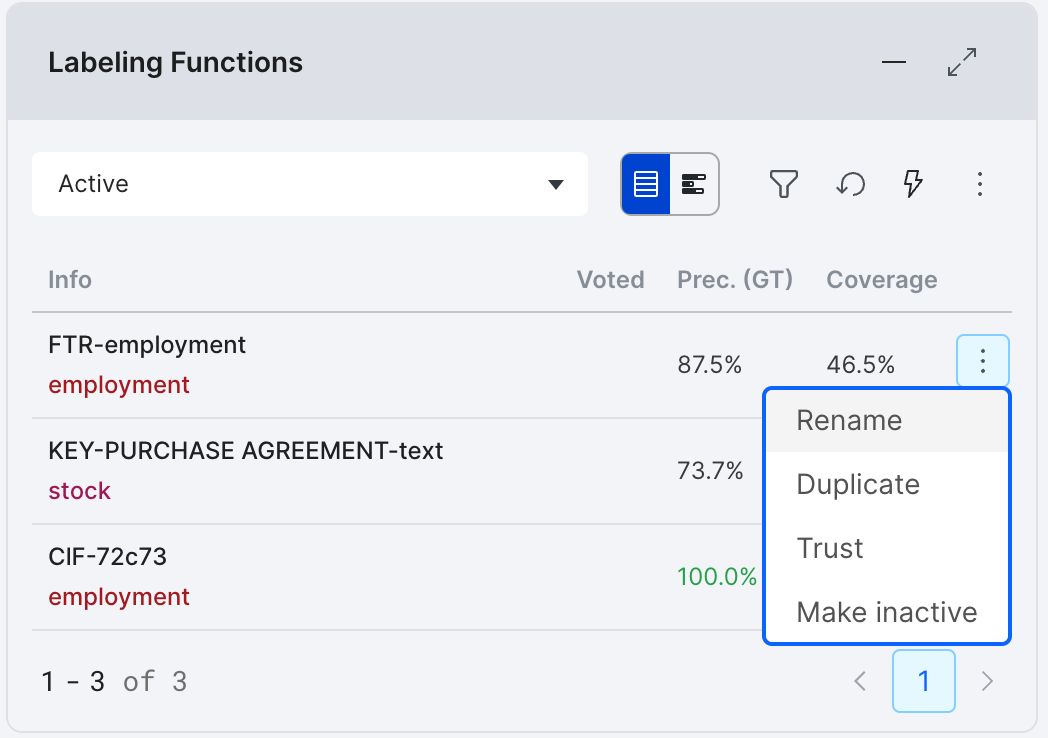
- Rename this LF: Opens an edit field for you to rename a LF. Note that each LF name has to be unique.
- Trust this LF: Tells the labeling model to default vote on datapoints with the label specified by this LF.
- Archive this LF: Sends the LF to Inactive LFs tab.