Introduction to labeling functions (LFs)
Labeling functions (LFs) in Snorkel Flow allow users to programmatically label data. Labeling data with LFs is faster than asking subject matter experts to label it by hand.
LFs allow users to specify the conditions in which Snorkel Flow will apply a particular label to a data point. This is known as a vote for that data point to receive that label. If a data point doesn't meet the conditions for a particular LF, the LF abstains by voting UNKNOWN.
The Snorkel Flow labeling model then combines all LF-assigned votes and other signals to decide how to label each data point. The labeling model estimates LF accuracies and aggregates LFs to calculate label votes without relying on ground truth labels.
LFs can be renamed, edited, or deleted.
LF composer toolbar
LFs can be created using several tools, including:
1. Search-based
LF summary
Once LFs have been created, details about the LFs are available in the LFs table in the left sidebar. These details include the LF name, LF vote, LF metrics, LF author, and the time the LF was created. The table columns can be customized by clicking the three dots in the top right and selecting the desired columns. More strategies for LF management can be found in the article on LF management.
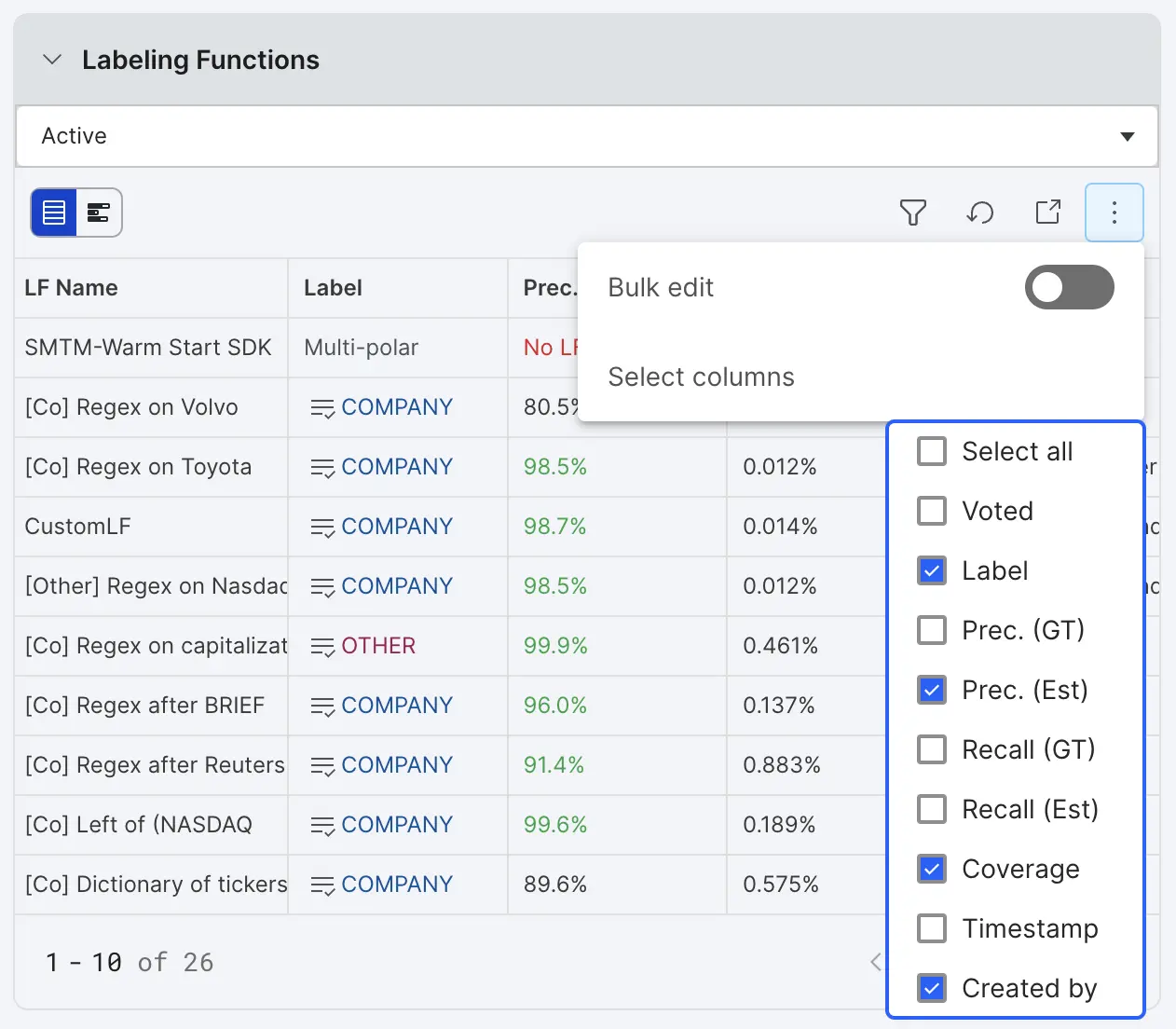
-
LF Name: The name for this LF
-
Label: The label assigned by the labeling function
-
Voted (specific to the datapoint selected in Data Viewer tab):
- Gray ✓ voted, but no GT exists
- Green ✓ voted correctly based on assigned GT
- Red x voted incorrectly based on assigned GT
-
Precision (GT): The (number of correct LF votes) / (total number of LF votes), based on the existing GT labels. This is only an estimate based on a potentially very small dev set. The learned precision Snorkel Flow will use to generate probabilistic labels for data points won’t be calculated until a label package is created and can be viewed on the LF Packages page.
-
Precision (Estimated): The same as Precision (GT) but using estimated GT labels (based on LF votes) wherever manual GT labels do not exist. (Total LF votes for class in agreement with estimated GT labels) / (Total LF votes for class).
-
Recall (GT): The (number of correct LF votes) / (total number of examples in class), based on the existing GT labels.
-
Recall (Estimated): The same as Recall, but using estimated GT labels (based on LF votes) wherever manual GT labels do not exist. (Total LF votes for class in agreement with majority) / (Total majority votes for class).ƒ
-
Coverage: The percentage of data points in the current split that this labeling function votes on.
-
Count (GT): The total number of LF votes generated by this LF on the current split.