Embedding based cluster LFs
The embedding based cluster workflow allows you to supercharge your programmatic labeling by leveraging embeddings to build labeling functions (LFs) in your Snorkel Flow application.
To use the embedding based cluster workflow, you’ll need to add an EmbeddingFeaturizer or RegisterCustomEmbedding upstream of your model node.
Ground truth labels are required to generate clusters. Generally, this workflow works best with a mix of data points that have ground truth labels and data points that are unlabelled.
Snorkel Flow does not support embedding-based cluster LFs for text sequence tagging and multi-label applications.
Using embedding based cluster workflow in Studio
In Studio, the embedding based cluster workflow helps you identify themes of similar data points and then directly action on them by creating cluster LFs. Additionally, we have tools to find documents similar to any input text, as well as drag-to-discover functionality to easily explore your embeddings. To enter the embedding based cluster workflow, click the Embeddings icon and text within the LF composer toolbar as shown below.
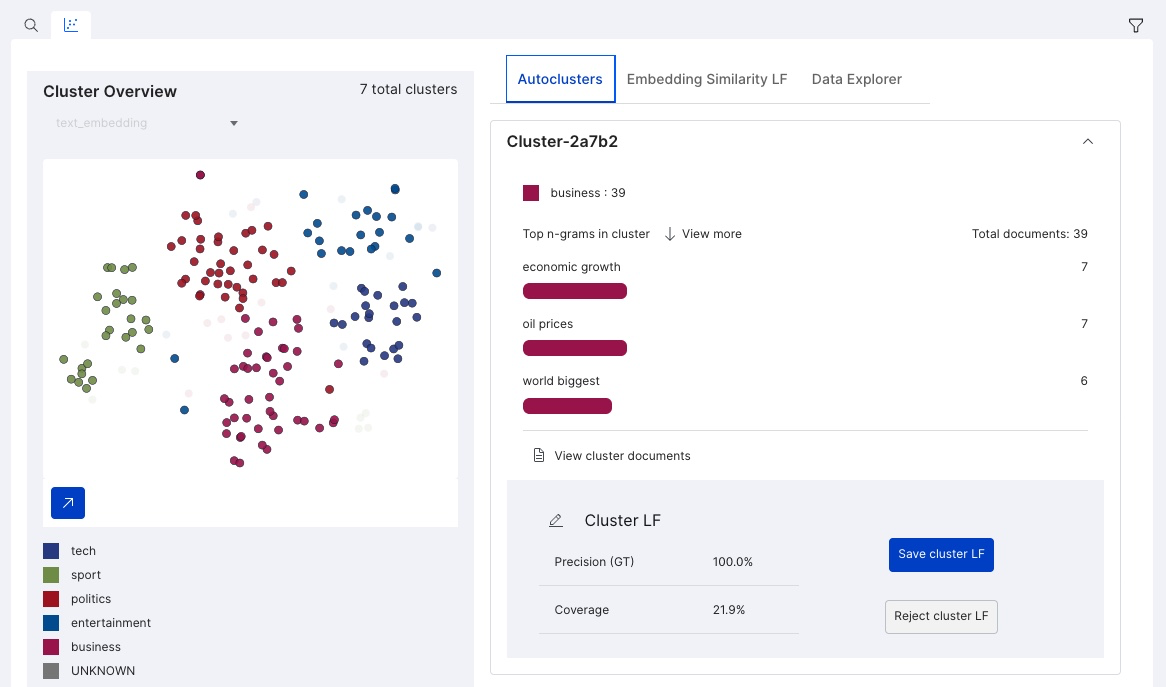
Autoclusters
Autoclusters provide auto-suggested cluster LFs. The two main panels of this view are:
- Cluster Overview
- Provides a 2 dimensional visual representation of the embeddings.
- Allows you to choose which embedding field to work with.
- Allows you to select any point to bring up the related cluster detail in the LF panel.
- Cluster Details
- Lists the auto-suggest cluster LFs sorted by coverage.
- When a cluster is selected, it highlights the related data points in the Cluster Overview.
- Allows you to drill down to specific example documents in the cluster.
- Shows the top n-grams and ground truth proportions in the cluster.
- Shows the precision and coverage metrics of the preview LF.
- Save cluster LF saves the LF to your active LF list.
- Reject cluster LF minimizes the details from further listings with the possibility of reevaluation.
Clusters are automatically recomputed whenever the active set of data points changes. This includes resampling the development set, applying a filter, or previewing a text-search-based LF.
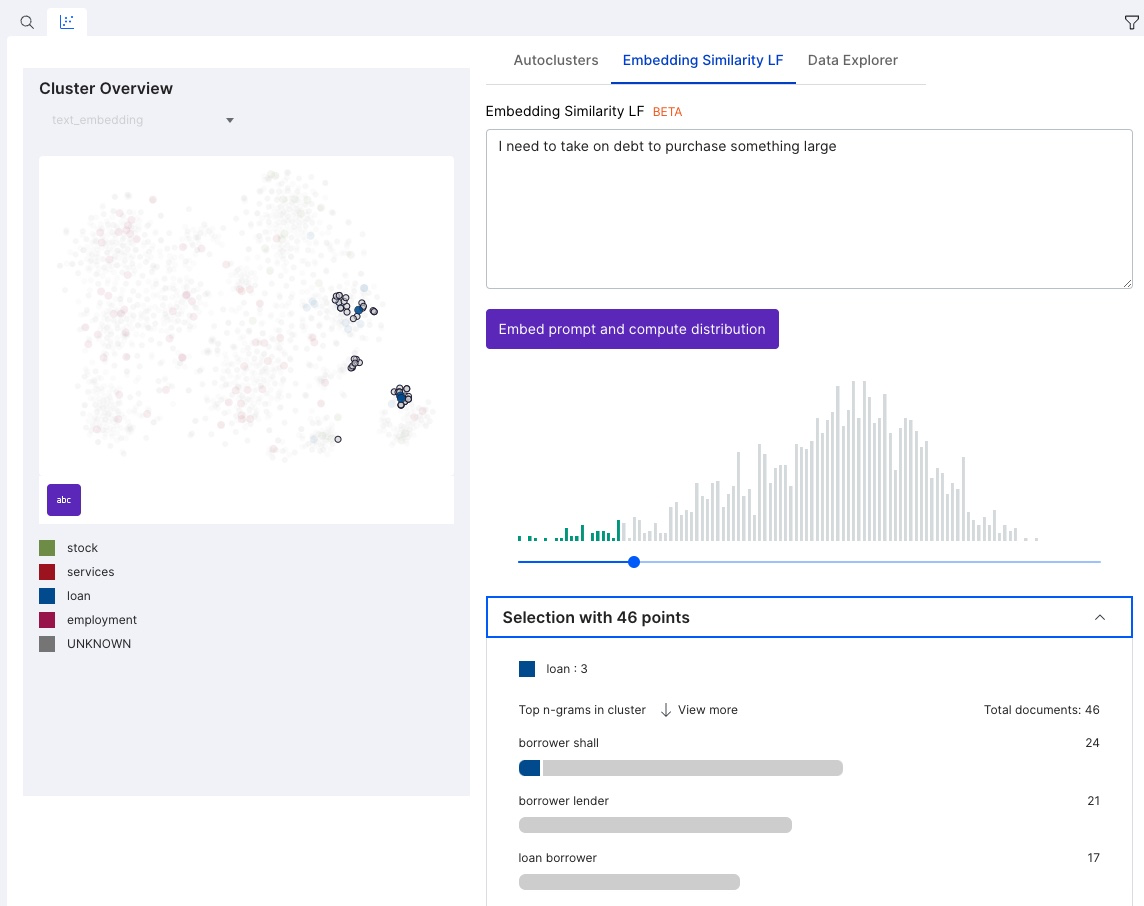
(Beta) Embedding similarity LF
In addition to the automatically generated clusters, you can also create your own clusters by using the Embedding Similarity LF tab. This tab lets you enter any text, for example, a sentence from a document that you want to find similar examples for. Snorkel will then compute the embedding of the entered text, calculate the similarity between each data point and the entered text embedding, and create an interactive histogram of the results. You can select a threshold beneath the histogram to see the pertinent data points, and then create a cluster LF from the selected data points.
This functionality does not work with RegisterCustomEmbedding as the entered text embedding must be calculated on demand.
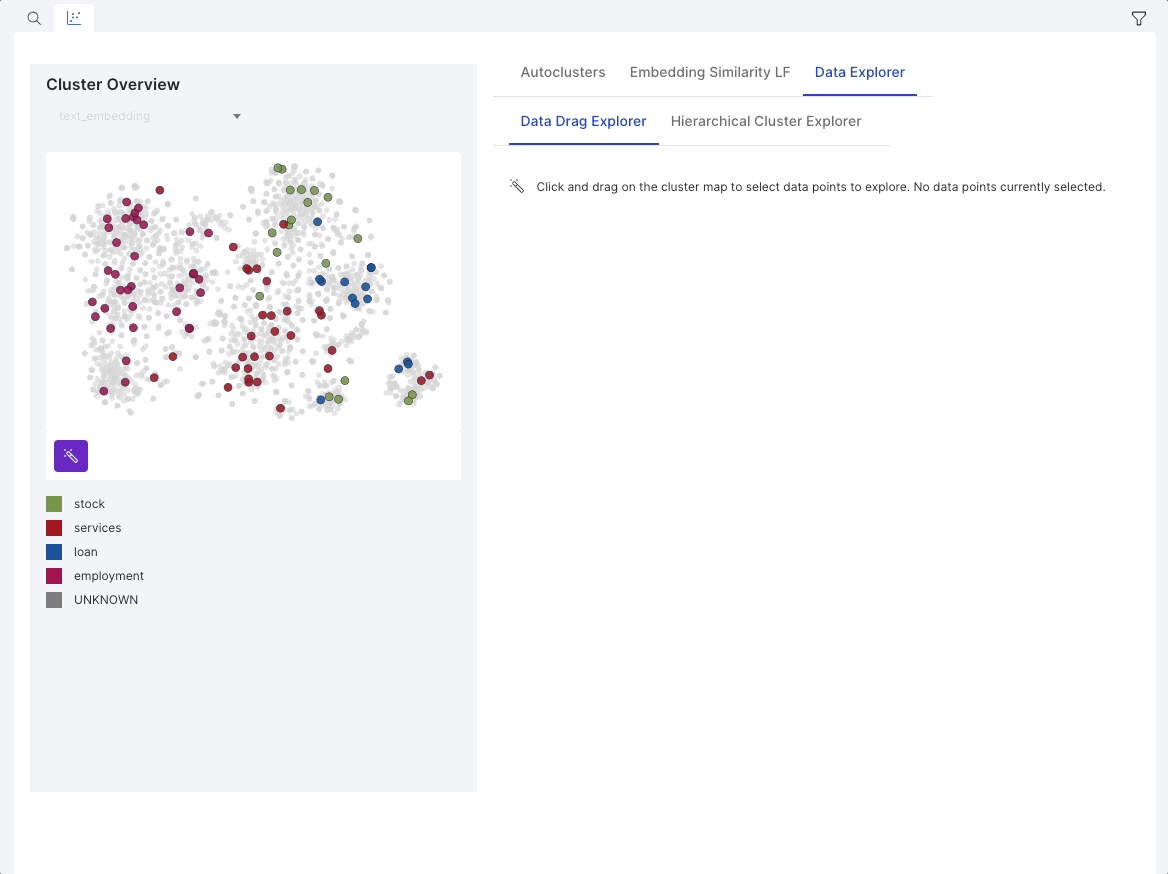
Data explorer
The Data Explorer extends your ability to leverage clusters by allowing you to visually choose your own cluster or calibrate the auto cluster settings.
Data drag explorer
The Data Drag Explorer allows you to click and drag the points that you want to cluster on the cluster map. This results in a selection of points which you can create an LF from or tag for further use.
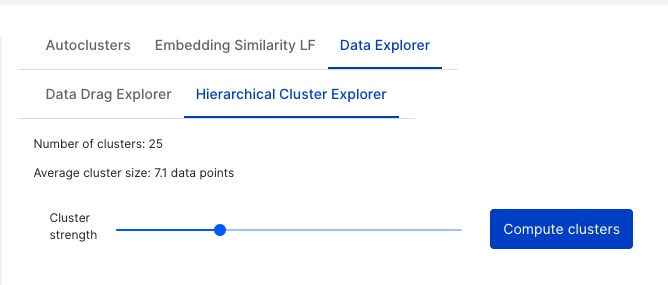
Hierarchical cluster explorer
The Hierarchical Cluster Explorer allows you to calibrate the Cluster strength to your needs, which adjusts the average cluster size in data points. After each computation of clusters, you can choose clusters to create LFs from just as with the auto suggested cluster LFs.