Legacy ground truth annotations
In this article, you will learn about ground truth annotations and how to add these annotations for multiple use cases.
Ground truth refers to the set of labeled and accurately annotated data that serves as a reference or benchmark for training and evaluating machine learning models. During the evaluation phase, ground truth data is used to assess the model's performance. By comparing the model's predictions with the actual labels in the ground truth, metrics such as accuracy, precision, recall, and F1 score can be calculated.
Snorkel Flow allows you to programmatically generate labels for your training split. Snorkel recommends using ground truth (GT) labels for data points in other splits:
- In the dev split, GT-labeled examples assist with discovering and iterating on labeling functions (LFs).
- In the valid and test splits, use GT-labeled examples to evaluate model performance and facilitate error analysis.
Annotation options
There are two ways to update GT labels in Snorkel Flow:
- Updating GT labels on the Label page
- Creating and committing annotations in Annotation Studio to GT labels
Updating GT labels directly on the Label page
-
On the Label page, update GT via the taop bar or the Annotation sidebar.
-
To enter Annotation Mode on the Label page, select the icon on the right side of the dataviewer.
-
Ensure Edit ground truth is selected in the dropdown menu.
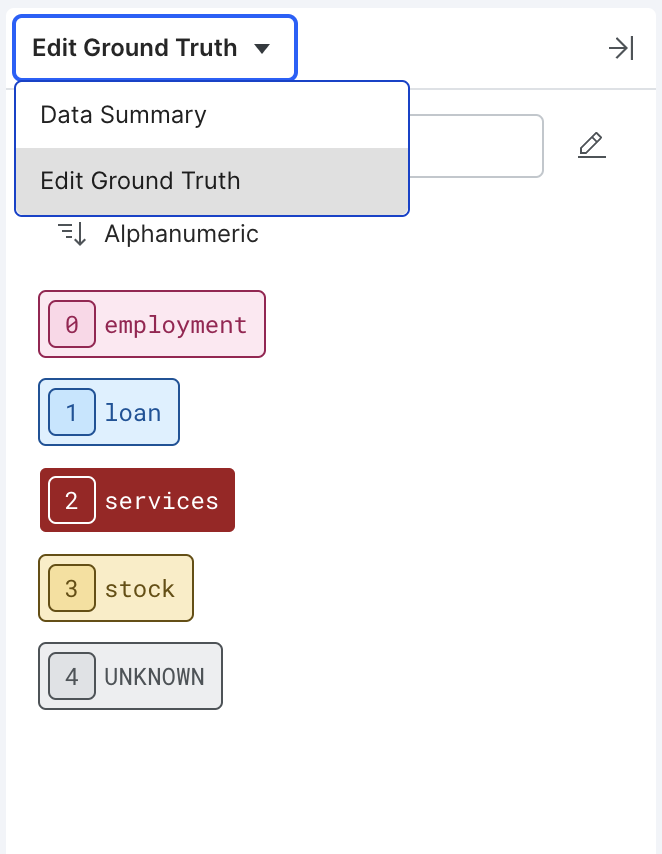
-
To exit Annotation Mode, select the icon on the top-right corner of the pane.
Annotation Studio
Annotation Studio consists of two pages: Batches and Annotate.
The Annotate page is a bird's-eye view of all data points to review annotations. You can see different metrics such as the number of completed annotations, number of annotators, label distribution, and more.
The Batches page acts as a workspace to create and manage batches of data points to annotate.
Follow these steps to apply GT labels in the Annotation Studio:
- Via the Batches page, create and assign batches of data points to specific users to annotate.
- Annotators view the data points in a batch and propose GT labels for each.
- (Optional) Aggregate annotations from multiple sources via majority vote on the Batches page to form a new set of annotations.
- Select a specific annotation set from a batch to commit as GT for those data points.
For more information about Annotation Studio, see Annotation Studio overview.
Adding annotations
The steps for adding a GT label in the Label page or proposed GT label in the Annotation page are the same, but vary by application type.
In addition to GT labels, you can add notes for free-form comments or slices for arbitrary grouping.
Classification: Adding ground truth
In Record View, modify the GT label of an individual data point using the dropdown at the top of the dataviewer.
In Annotation Mode, select on the appropriate label in the Annotation pane or use the corresponding shortcut key to the left of the label.
Extraction: Adding span ground truth
In extraction tasks, GT labels are collected for individual spans. For a description of how these spans are created, see the Information extraction: Extracting execution dates from contracts tutorial.
Once GT extractions exist, you can propagate these labels to individual spans using the auto-fill functionality in the Annotation pane. Auto-fill performs a string comparison between document level extractions and all spans found in their corresponding documents. If a span matches a specified GT extraction, it receives a Positive label. All others in that document receive a Negative label.
Entity classification: Adding entity ground truth
For entity classification tasks, you can assign a GT label per entity in each document using the Annotation pane. You can explicitly update the GT label for a given span in Record View by selecting it and updating the GT label dropdown. This change updates the corresponding entity label, too.
Auto-fill works similarly to Extraction tasks, except labels are propagated based on entity assignments, rather than string matches.