Hierarchical configuration for classification and extraction tasks
In this page, you will learn how to create a hierarchical task (classification, extraction, etc.).
We will demonstrate how to use Snorkel Flow for hierarchical classification problems by building upon the application templates described in the Document classification: Classifying contract types tutorial.
Create a dataset and application
Follow the dataset and application creation from the Document classification: Classifying contract types tutorial.
Create hierarchical configuration
After loading the datasources and creating the application template, we can create the hierarchical configuration by:
- Selecting the dropdown bar at the model node (the three-dot next in the model node)
- Select Build hierarchical model. This selection will prompt an interface for inputting sub-labels
- Click Split into submodels once you input all sub-labels
- Snorkel Flow will create a hierarchical DAG for the appropriate template
For example, we can split “services” into 2 sub-classes “management-services” and “non-management-services”; splitting “employment” into 2 sub-classes “executive-employment” and “non-executive-employment”. The two classes “loan” and “stock” can stay as they are.
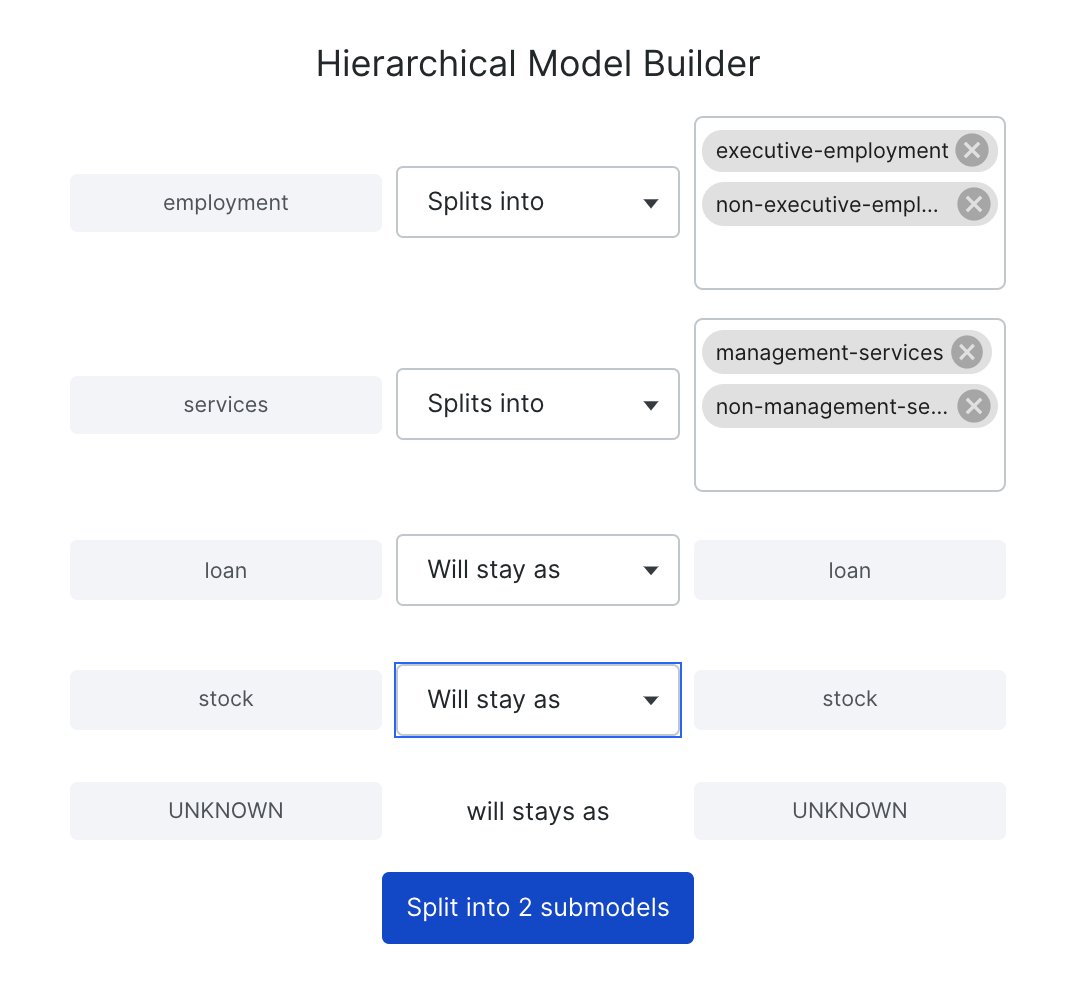
The expected output will look as follows:
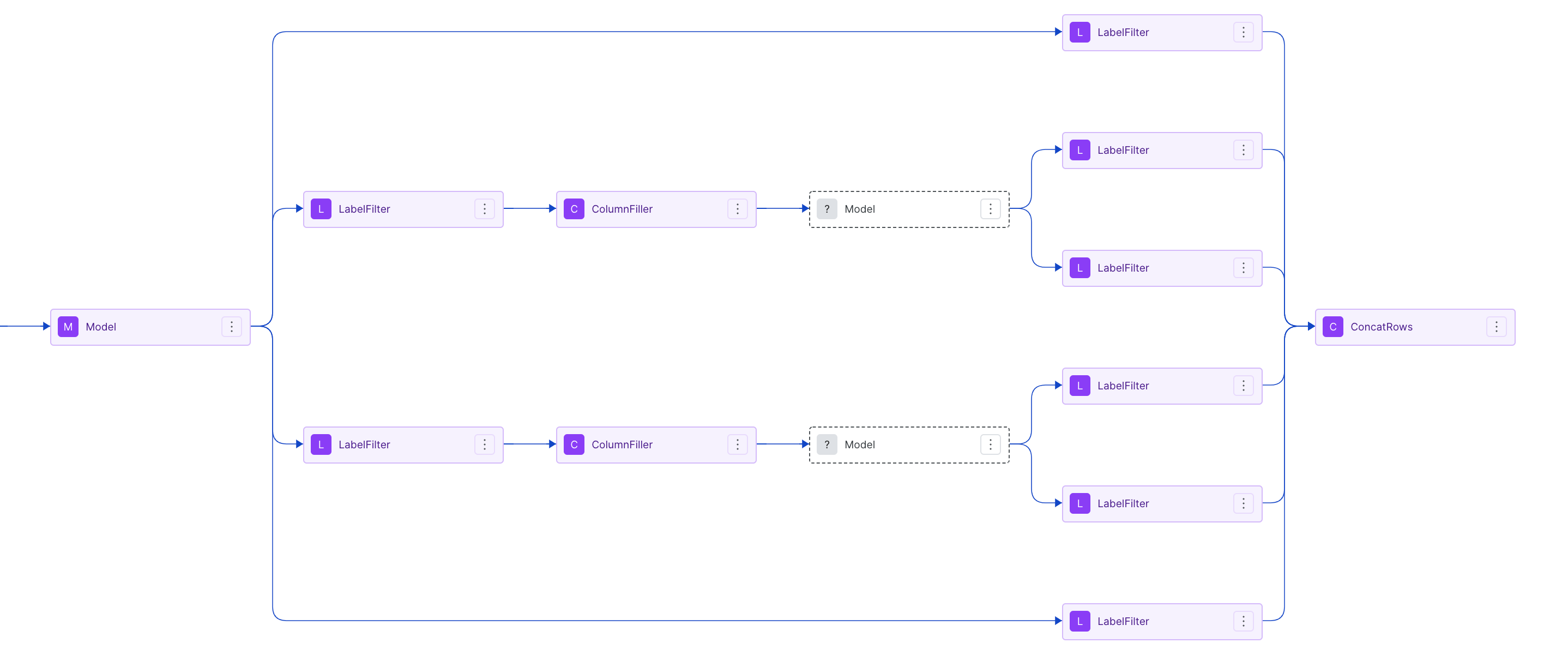
About the DAG:
- The
Modelnodes are where we iteratively write labeling functions, train the models, and analyze performance. - The
LabelFilterandColumnFillerwill ensure Snorkel Flow passes the predictions into the correct models. - The
ConcatRowswill aggregate the predictions across all models and create the resulting dataframe. This node is also the last node of the hierarchical task.
Iteration and development
The iteration process will happen at every Model node. Each model will perform a classification/extraction/etc task for each sub-labels group (e.g., “management-services” and “non-management-services”, “executive-employment” and “non-executive-employment”). You can upload the corresponding ground truths, write labeling functions, train models, and analyze performance.
Final predictions
The ConcatRows node will output a dataframe, with the preds_str column containing the final prediction.