Tutorial: Document classification for SEC filings
In this tutorial, you'll use Snorkel Flow to train and build a model that classifies over 20,000 SEC filings into one of the following categories: employment, services, stock, and loan. With Snorkel Flow's programmatic labeling, you'll label your training data using Labeling Functions (LFs), train your models, and analyze the results, guiding you through an iterative development process.
This tutorial is designed for first-time users of Snorkel Flow who are new to data-centric AI, programmatic labeling, and machine learning models.
What you'll learn
- Uploading data into Snorkel Flow
- Creating a new application
- Programmatically labeling your data with Labeling Functions (LFs)
- Training your Machine Learning (ML) model
- Analyzing model errors and results
Concept: Data splits
In this tutorial, you'll upload four data splits for the example application, each with a specific purpose for model development:
- Train: The initial training dataset used to develop your machine learning model. This split does not need to have labels. However, this tutorial includes a small number of labels for development purposes, to help you understand the classification problem. This tutorial walks you through how to build consistent labels in the data in your
trainsplit. - Dev: A randomly sampled dataset used for developing Labeling Functions. To limit the amount of data in memory, Snorkel Flow randomly samples the
trainsplit to create thedevsplit. By default, it samples 10% or up to 2,000 samples. Thedevsplit dataset is viewable from your application's Develop > Studio page. - Test: The ground truth dataset held out from the training data for evaluation purposes. While not strictly necessary, it's recommended to use the
testsplit for a final evaluation of your model against a fresh set of expert-annotated labels.
To avoid biasing your evaluation procedure, do not look at data points in the test split.
- Valid: Like
test, thevalidsplit contains some ground truth labels for evaluation purposes. This split can be used to tune your ML model.
For more information about uploading and splitting data, see the Uploading a dataset article.
Upload data
Before you create the example Snorkel Flow classification application, you need to upload the data you want to classify.
You will upload this data to a new dataset in your Snorkel Flow instance. Data can be ingested into Snorkel Flow from a range of sources, including cloud storage, databases, and local files. For this tutorial, use the provided dataset from AWS S3 Cloud Storage. This is the set of SEC filings that you will classify with Snorkel Flow.
-
From the left menu, select Datasets.
-
Select + Upload new dataset.
-
In the Upload new dataset dialogue, enter the following information:
-
Dataset name: Enter
contract-clfas your dataset name. -
Select a data source: Select Cloud Storage as your data source.
-
File path and Split: Add these four datasets:
File path Split s3://snorkel-contracts-dataset/train-cleaned.parquettrain s3://snorkel-contracts-dataset/dev-cleaned.parquettrain s3://snorkel-contracts-dataset/valid-cleaned.parquetvalid s3://snorkel-contracts-dataset/test-cleaned.parquettest
-
-
Select Verify data source(s). Snorkel Flow runs data quality checks to ensure data is cleaned and ready to upload.
-
Scroll down to the Define schema section. From the UID Column menu, select
uid. This is the unique entry ID column in the data sources. -
Select Add data source(s). When the data is done ingesting from all four data sources it shows the status Data ingestion complete.
Troubleshooting: If one or more of the example data splits does not upload, delete the dataset and try to upload the data again.
After your data is uploaded, you can create your Snorkel Flow classification application.
Create an application
Create a new Snorkel Flow application. Within this application, you can start using Snorkel Flow's powerful tools to classify the documents in your dataset. To create a new application:
- From the left menu, select Applications.
- Select the dropdown arrow from the Create application menu in the top right corner of the page, then select Create from template.
- Choose the Classification template from the menu of preset application templates. This template creates an application that labels entire documents across the desired schema.
- Click Create application.
- Fill in the New Classification application dialogue. Enter the following information:
- Application name:
classification-example-app - Choose default dataset:
contract-clf - Specify required input fields:
text(leave other options unchecked) - Ground truth column (Optional):
label
- Application name:
- After inputting this information, select Autofill Labels to populate the Labels (optional) field with your labeling schema, based on existing data in your label column.
- Click Save to initiate application creation. This takes 2-5 minutes, as Snorkel Flow ingests your data into the application template and prepares the data for programmatic labeling.
- Once the application has initialized, select the Go to Studio button to access the Studio page.
Next, you will develop a machine learning model that will significantly speed up the contract classification task, starting with labeling functions (LFs).
Task overview: Programmatic labeling
The remainder of this guide will walk through a working classification example that demonstrates the three core tasks of programmatic labeling:
-
Develop labeling functions (LFs).
Labeling functions capture the mental models that your subject matter experts (SMEs) use when they label data manually as Python functions that can be applied to larger amounts of data. The end result is a large amount of labeled training data.
-
Train a machine learning (ML) Model.
Using the large amount of labeled training data, Snorkel Flow applies standard machine learning techniques to train an ML model customized to your dataset.
-
Analyze model results.
Evaluate the model's performance, and adjust the labeling functions and training until the model meets your performance criteria.
Develop labeling functions (LFs)
Machine learning model training works better with larger amounts of labeled data to train on. Labeling Functions (LFs) allow you to programmatically label large amounts of data. LFs codify expert opinion and criteria for how to label your data. These labeled data points create more training data, so you can achieve better model results at the training stage.
Follow along with the steps in the example to create a precise LF for employment contracts.
Filter data
The first stage in creating LFs is exploratory. Often, a data scientist and an SME work together to identify patterns in already-labeled data that are good candidates for an LF. Filter the uploaded data for only documents that are already labeled employment. Do this from the Studio page for the classification-example-app:
-
Select the Filter icon in the top right corner of the page.
-
Select Ground Truth.
-
Select Ground truth + is +
employmentfrom the dropdown menu.
-
Select the checkmark (✓) to filter viewable data for documents already labeled
employment.
Use Snippet view
You can choose the most efficient view of the data.
- From the Record view menu, choose Snippet view to see a small chunk of text from each document.
Create, assess, and improve the first labeling function
As you scan the documents in the employment set, notice that most start with EMPLOYMENT AGREEMENT. Let's create an LF that labels all documents containing the text EMPLOYMENT AGREEMENT as employment:
-
In the text box in top middle pane with the description Type anything to start creating an LF, type
/. -
Select Keyword under the Pattern Based section. This brings up the dialogue text + contains + Keywords.

-
In the Keywords field, enter
EMPLOYMENT AGREEMENT. -
From the Select a label on the right side of the LF builder, select
employment. -
Select Preview LF. The Record view now shows documents that match the LF. Snorkel Flow also displays metrics for this LF:

- Prec. (Est): Measures the precision of the LF for your current data split. That is, it measures how often the LF correctly labels the documents, based on the ground truth. In this example, the precision is 93.6%, which is highly accurate. Your results may vary.
- Coverage: The % data in your split that fit this criteria. In this example, the coverage is 32.4%. Your results may vary.
-
Select Create LF to add this LF to the active LFs for the model you're going to train. You can see this LF added to the Labeling Functions pane.

-
To achieve higher precision, incorporate a second criterion for the
EMPLOYMENT AGREEMENTLF to exclude all documents that contain the textpurchase. Select theKEY-EMPLOYMENT AGREEMENT-textlabel from the Labeling Functions menu. -
To build a multi-part LF, select the three-dot menu next to the first factor. Select Add another builder (and). From the three-dot menu, select Negate this builder to use the NOT option.

-
In the Keywords field, enter
purchase.
Create five more labeling functions
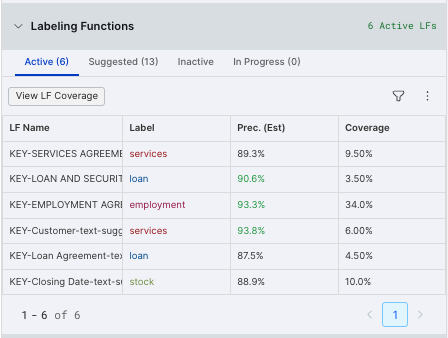
Repeat Steps 1-6 in the previous section to create five more labeling functions for the SEC filings dataset. Snorkel Flow can auto-detect the label after you select Preview LF for each LF. Create these LFs:
| LF Type | Keywords | Label |
|---|---|---|
| Keyword | Customer | services |
| Keyword | SERVICES AGREEMENT | services |
| Keyword | LOAN AND SECURITY AGREEMENT | loan |
| Keyword | Closing Date | stock |
| Keyword | Loan Agreement | loan |
Once you've created each of these LFs, you will see the six active LFs in the Labeling Functions pane on the left side of the page. Note that your values may vary from the example.
TIP
Learn more about Creating good labeling functions.
Now more of your data has programmatically added labels. Next, you'll create a model from this larger training dataset.
Train a machine learning (ML) model
Now that you've created several LFs for your model, you are ready to train your first ML model! After training the model, you will then compare the model's label predictions with the expert-assigned labels for the valid data split.
-
Expand the Models pane and select Train a model.
-
Choose Fast model, which is significantly faster than the other options. It runs a subset of the training data through the model and provides a good baseline to gauge this model's results. Select Train Fast Model to begin model training for the SEC filings dataset.
A status bar appears that shows the model training % progress.

Once the model is finished training, it updates the Models table with the most recent model metrics.
Assess model accuracy for the valid split
Model assessment is the key to achieving high-quality results with your custom ML model. In this example, your goal is to achieve at least 90 accuracy and 90 F1 Macro for the valid data split.
Here are some example results from running a Fast model with the existing LFs:

- Accuracy: 84.84%
- F1 Macro: 82.51
These results are a good start, but below the desired 90 Accuracy and 90 F1 success metrics when evaluating the model against the pre-labeled valid data split.
Next, you will use the Analysis pane to identify which data points and labels your model struggles to predict.
Analyze model errors and results
After running the first ML model, you can view the model performance in the Analysis pane.
This tutorial uses the two most common error analysis visualization tools, the Clarity Matrix and Confusion Matrix to analyze and improve the example document classification model. To learn about all of Snorkel Flow's analysis visualization tools, read Analysis: Rinse and repeat.
Interpret results from the Clarity Matrix
The Analysis panel shows the Clarity Matrix by default.
The Clarity Matrix table compares labels created by LFs with labels created by the model, and compares both of them to the valid data split. Example Clarity Matrix output:
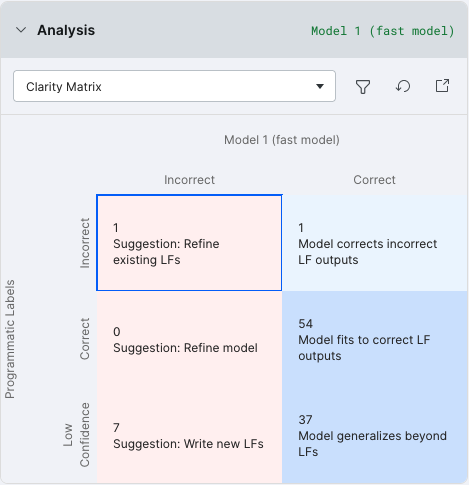
Explanation of the Clarity Matrix table:
| LF | Model | Definition | Suggestion |
|---|---|---|---|
| Incorrect | Incorrect | The model learned the wrong thing from the LF. | Refine the LF for accuracy. |
| Incorrect | Correct | The model extrapolated correctly, despite the incorrect LF. | No action. |
| Correct | Incorrect | The model was inaccurate despite correctly-labeled data. | Refine the model. |
| Correct | Correct | The model trained correctly from the LF-labeled data. | No action. |
| Low confidence | Incorrect | The model extrapolated incorrectly. | Write more LFs to give the model more training data. |
| Low confidence | Correct | The model extrapolated correctly. | No action. |
Select any cell in the table to view the corresponding data points in the Record view.
(Optional) Use the Clarity Matrix to refine an incorrect LF
These next steps show how you can use the Clarity Matrix to improve your LFs and the subsequent iteration of your model. Your output may be different from the example, so you may not be able to follow these steps exactly. In that case, just read through the steps so you can learn more about how to improve LFs.
-
From the Clarity Matrix, select the Refine existing LFs cell. You can see the specific document that the LF labeled incorrectly. In the Record view, the Ground truth is
employmentbut the Model 1 prediction and Training set 1 label are forservices. So, we should look for aservicesLF.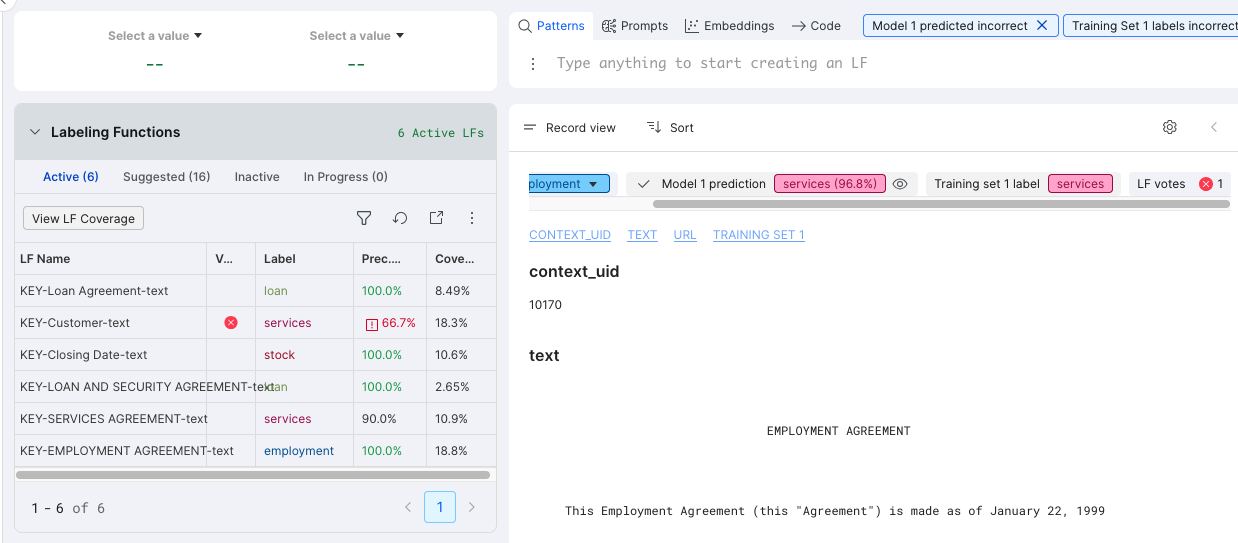
-
Expand the Labeling functions pane. You can see that the
KEY-Customer-textlabel Voted incorrectly and has low Prec. (GT). This makes it clear that this is the LF that needs to be refined. -
Incorporate a second criterion for the
CustomerLF to exclude all documents that contain the textEMPLOYMENT AGREEMENT. Select theKEY-Customer-textlabel from the Labeling Functions menu. -
Select the three-dot menu next to the first factor. Select Add another builder (and). From the three-dot menu, select Negate this builder to use the NOT option.
-
In the Keywords field, enter
EMPLOYMENT AGREEMENT. -
Select Preview LF.
-
Select Save LF.
(Optional) Use the Clarity Matrix to expand LF coverage
Continue to use the Clarity Matrix to write additional LFs. Your output may be different from the example, so you may not be able to follow these steps exactly. In that case, just read through the steps so you can learn more about how to expand your LF coverage.
-
From the Clarity Matrix, select the Write new LFs cell.
-
From the Record view dropdown, select Snippet view.
-
Look for patterns in the documents that none of the existing LFs apply to. In this example, there are several
stockdocuments that need an LF. -
Let's add another LF that addresses more of the
stockdocuments:LF Type Keywords Label Keyword STOCK PURCHASE AGREEMENT
NOTLOAN AGREEMENT+EMPLOYMENT AGREEMENTstock
Interpret results from the Confusion Matrix
Select the Confusion Matrix from the dropdown menu in the Analysis pane.
The Confusion Matrix compares every actual label with every predicted label. For example, select the cell in the LOA row and the SER column to view documents that are actually loan agreements in our valid dataset, but were classified as service agreements.

(Optional) Use the Confusion matrix to expand LF coverage
Use the Confusion Matrix to write additional LFs. Your output may be different from the example, so you may not be able to follow these steps exactly. In that case, just read through the steps so you can learn more about how to expand your LF coverage.
-
From the Confusion Matrix, select the cell in the
LOArow and theSERcolumn. -
From the Record view dropdown, select Snippet view.
-
Look for patterns in the documents that none of the
loanLFs apply to. -
Let's add another LF that addresses more of the
loandocuments:LF Type Keywords Label Keyword Loan Partyloan
(Optional) Train a new model
Now that you've refined and added more LFs, train another fast model by following the steps in the Train a machine learning (ML) model section. Compare the results of this model with your first one and note any improvements or regressions.
Next steps: Iterate to improve model performance
After completing this tutorial, you now understand the most common features and capabilities of the Snorkel Flow platform and are ready to work towards achieving your model training success metrics!
For further learning, you can improve the model performance for this dataset and task by using the Analysis visualizations to tweak your LFs and models for better results. In this way, improving and adapting your model becomes unblocked from the need for hand-labeled training data and instead becomes fast, iterative, and analysis-driven.
As you continue to iterate on your results, we recommend using the following Snorkel Flow features:
- Customize your model's architecture, hyperparameters, and hyperparameter searches
- Write Search based LFs
- Make use of the additional analytical views described in Analysis: Rinse and repeat