What is data-centric AI?
This module defines data-centric artificial intelligence (AI), its core differentiation from traditional model-centric AI, and how existing customers benefit by using Snorkel Flow’s data-centric AI approach.
What is data-centric AI?
Machine learning has always been about data. With the development of powerful push-button models, data science teams can shift their focus to the data. This process, known as data-centric AI, is all about iterating and collaborating on the data used to build AI systems and doing so programmatically.
Historically, data science and machine learning teams have focused on model development by iterating on things like feature engineering, algorithm design, and bespoke model architecture. As models become more sophisticated and push-button, AI teams need to focus on data iteration as crucial to successfully and rapidly develop and deploy high accuracy models. Clean, usable data can’t be merely a static artifact in order to achieve high-performance machine-learning (ML) models.
Today, machine-learning models have simultaneously grown more complex and opaque. ML models require significantly higher volumes of and higher quality training data. Data has become a practical interface to collaborate with subject matter experts and turn their knowledge into software.
Data-centric AI vs. model-centric AI?
The shift to a data-centric approach is as much a shift in focus of the ML community and culture as a technological or methodological shift. In this sense, a data-centric approach means you are now spending time on labeling, managing, slicing, augmenting, and curating the data efficiently, while the model is relatively fixed. The following image illustrates how data-centric AI requires consistent iteration on your data to best fuel your end ML models.
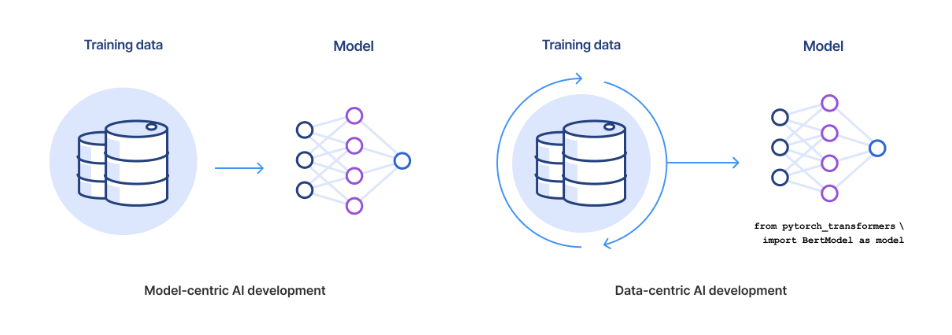
Model-centric AI largely considers the training datasets from which their model is learning as a collection of ground-truth labels. The machine-learning model is made to fit that labeled training data. This process includes things like feature engineering, algorithm design, bespoke architecture design, and more. In other words, you are really dependent on the model and treating the data as a static artifact.
This decision is not binary between data-centric and model-centric approaches. Successful AI requires both well-conceived models and good data.
Example walkthrough
To illustrate the value of Data-centric AI, Snorkel Flow helped a top-3 US bank in identifying and triaging risk exposure within their loan portfolio. The bank previously required 6 person-months worth of analyst time to manually label their documents and 1 day to develop a model for their specific project. Performing error analysis and model validation required an additional 3 months to review and improve existing datasets thus, was only completed on an ad-hoc basis and suffered from inconsistent and unreliable labels.
Their current process was severely bottlenecked by manual data labeling. Current labeling approaches weren’t auditable and were slow to adapt to existing issues:
- Outsourcing to labeling vendors: Outside manual-labeling vendors brought significant privacy concerns regarding the confidentiality of their data. Most annotators additionally lacked domain expertise, requiring additional review before use.
- Labeling with in-house experts: Utilizing Subject Matter Experts (SMEs) solely for labeling was significantly time consuming. Using SMEs solely for annotation also brings a high opportunity cost, as SMEs time could be used on higher-value efforts.
Utilizing Snorkel Flow, the top-3 US Bank built an ML model significantly decreasing total labeling time and increasing labeling accuracy:
- Increased speed: Following model development, labeling ~250k new documents requires less than 24 hours to complete
- Guided error analysis: Data scientists could rapidly iterate on model errors to improve results, collaborating with SMEs and codifying their input into their existing labeling approach.
- Minimal validation effort: Labeling validation and iteration previously requiring 3-months are now accomplished in minutes with minor code modifications
Key principles of data-centric AI
As organizations change from a Model-centric AI to a Data-centric AI approach, the utilize the below principles in their development:
- Active training data: As models become more user-friendly and commoditized, the progress of AI development increasingly centers around agile iterability and quality of training data, rather than around feature engineering, model architecture, or algorithm design.
- Programmatic data labeling: Data-centric AI should be programmatic in order to cope with the volume of training data that today’s deep-learning models require. Manually labeling millions of data points is simply not practical. Instead, a programmatic process for labeling and iterating the data is the crucial determiner of progress.
- Subject Matter Expert (SME) collaboration: Data-centric AI should treat subject-matter experts (SMEs) as integral to the development process. Including SMEs who actually understand how to label and curate your data in the loop allows data scientists to inject domain expertise directly into the model. Once done, this expert knowledge can be codified and deployed for programmatic supervision.
Benefits of data-centric AI

Organizations developing their AI solutions using Data-centric AI will capture additional value from creating higher-quality data for their models:
- Faster development: A Fortune 50 bank built a news analytics application 45x faster and with +25% higher accuracy than a previous system.
- Cost savings: A large biotech firm saved an estimated $10 million on unstructured data extraction, achieving 99% accuracy using Snorkel Flow.
- Higher accuracy: A global telco improved the quality of over 200,000 labels for network classification resulting in a 25% improvement in accuracy over the ground truth baseline.