Re-split data
Sometimes, new data can be added to a dataset, or the data distribution can change in an application. When this happens, we may want to resplit the dataset in an application to move ground truth to different splits or to put new data into different splits. This creates a new application, copying everything from the previous application, and links the new dataset to the new application.
-
Split Size: While split size is problem dependent, the default split percentages are 70/20/10 (
train/valid/test). -
Usage:
- Select `Datasets` menu from the sidebar nav
- Select the dataset you want to re-split data on
- Click on the `New Data Source(s)` button

- Select your data source upload strategy (cloud, file, Snowflake, etc.) and then click on `Split by %`
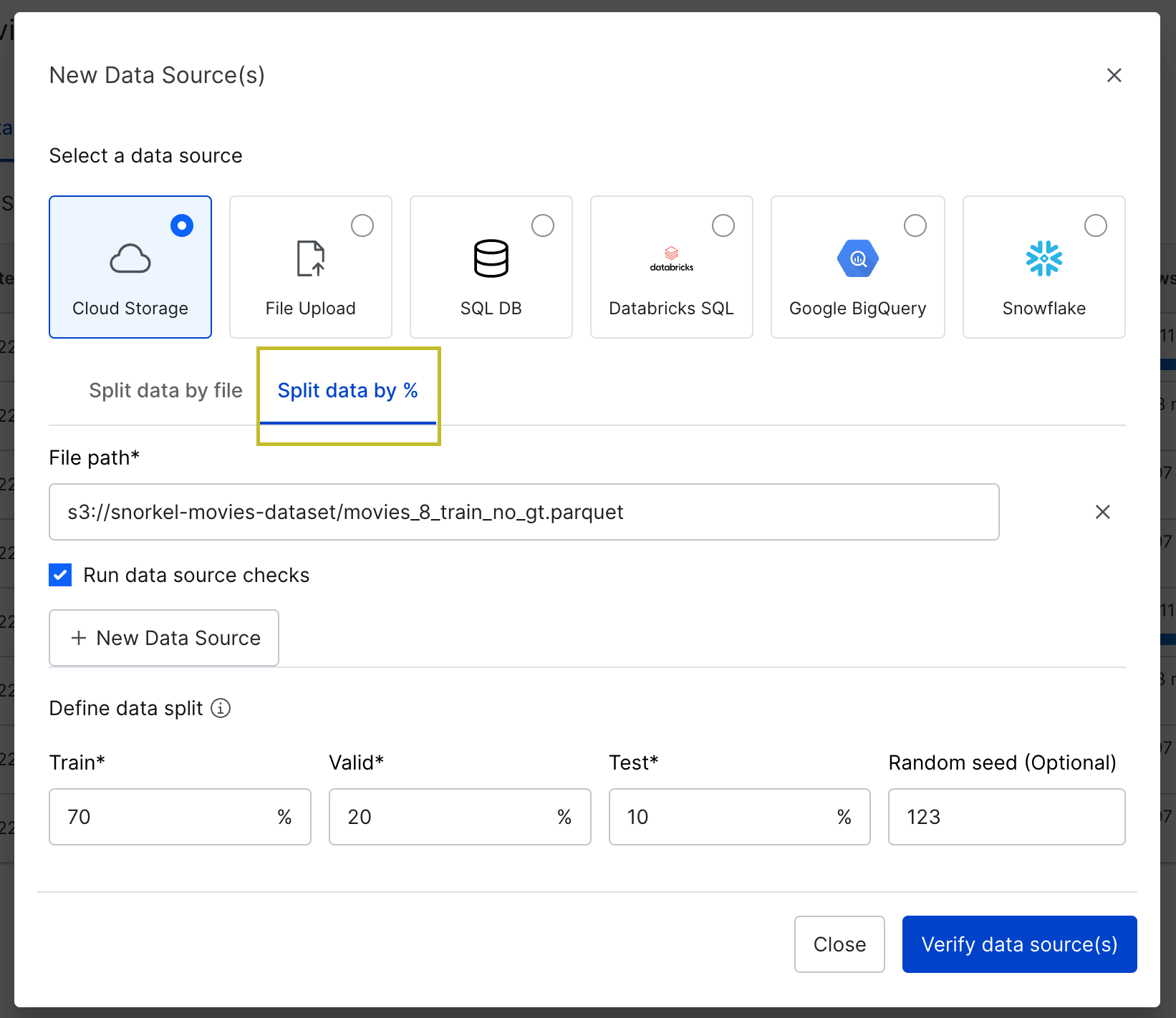
- You'll see that there are defaults already set for `train`/`valid`/`test` but you can change them as per your requirement
- Select `Datasets` menu from the sidebar nav
-
SDK: Snorkel Flow SDK supports resplitting data with the following functionality:
sf.resplit_datsources_by_percent(application_uid, datasource_uids). Additionally, an optionalsplit_random_seedparameter, as well as an optionalsplit_pctparameter, can be input to further specify a random seed or override the default split size. An example call might look like the following:
sf.create_new_application_with_resplit_datasources(
application_uid=application_info["application_uid"],
datasource_uids=datasource_uids,
split_pct=json.loads(SplitWiseDistribution(
train=train_percent,
test=test_percent,
valid=valid_percent).json()))