Prompt builder (SDK)
Prompt Builder offers the ability to precisely inject Foundation Model expertise into your application via an interactive workflow.
Typically, you will use the UI to see how a prompt is performing and create new labeling functions (LFs) from the prompt. Learn more about the prompt builder here. However, prompt LFs can be previewed and created through the notebook as well.
Prompt builder supports the following application types: text classification (single-label and multi-label), sequence tagging, and PDF candidate-based extraction.
Previewing a prompt LF
Import the Snorkel Flow SDK and retrieve the model node for your application:
import snorkelflow.client_v3 as sf
ctx = sf.SnorkelFlowContext.from_kwargs() # Import context to our current application
APP_NAME = "APPLICATION_NAME" # Name of your application
NODE_UID = sf.get_model_node(APP_NAME) # Model node used in the application
The following example previews a prompt LF over 5 examples in the dev split using a Text2Text model on a multi-label classification application.
You can preview a prompt LF with the following SDK command:
sf.preview_prompt_lf(
NODE_UID,
model_name="google/flan-t5-xxl",
split="dev",
num_examples=5,
model_type="text2text_multi_label",
prompt_text="""The possible labels are anova, bayesian, mathematical-statistics, R.
What is the most likely label for the following document: {Body_q} {Body_a}\n\nLabel: """,
)
This will show the result of running that prompt LF using 5 examples in the dev split:

- output: The output of the LLM used, in this case,
google/flan-t5-xxl. - label: The in-Snorkel label that is assigned by the code mapper based on the LLM output. A default code mapper is provided for each supported application type (basic keyword mapping), but a custom one can be passed using the
output_codeparameter. - ground truth: The actual label.
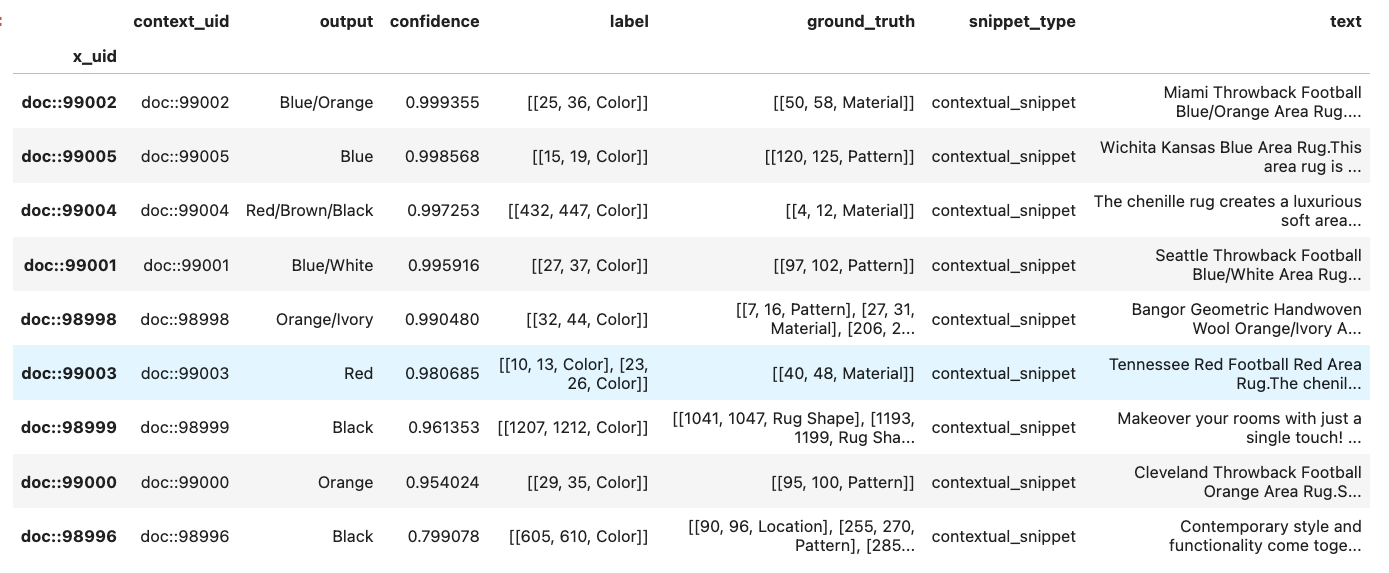
In the next example, we will preview a prompt LF over 10 examples in the dev split using a Text2Text model on a sequence tagging application. Note that the primary_text_field and label parameters are required for sequence tagging applications.
sf.preview_prompt_lf(
NODE_UID,
model_name="openai/gpt-4o",
split="dev",
num_examples=10,
model_type="text2text_qa",
primary_text_field="Description" # Required for sequence tagging applications
label="Color", # Required for sequence tagging applications
prompt_text="""List all occurrences of the exact answers to the question. Return answers separated by the delimiter ";". Make sure each answer is separated exactly by this delimiter without any additional spaces or characters.
Question: What is the color here?""",
)
This shows the result of running that prompt LF using 10 examples in the dev split:
To learn more information regarding the parameters of sf.preview_prompt_lf(), run:
sf.preview_prompt_lf?
Creating a Prompt LF
Once you are satisfied with the preview results of the prompt LF, you can create the prompt LF by calling sf.create_prompt_lf().
Here's how you can create the above prompt LF for a multi-label application:
sf.create_prompt_lf(
NODE_UID,
model_name="google/flan-t5-xxl",
lf_name="my multilabel prompt LF",
model_type="text2text_multi_label",
prompt_text="""The possible labels are anova, bayesian, mathematical-statistics, R.
What is the most likely label for the following document: {Body_q} {Body_a}\n\nLabel: """,
)
Here's how you can create the above prompt LF for a sequence tagging application:
sf.create_prompt_lf(
NODE_UID,
model_name="openai/gpt-4o",
lf_name="my sequence tagging prompt LF",
model_type="text2text_multi_label",
primary_text_field="Description" # Required for sequence tagging applications
label="Color", # Required for sequence tagging applications
prompt_text="""List all occurrences of the exact answers to the question. Return answers separated by the delimiter ";". Make sure each answer is separated exactly by this delimiter without any additional spaces or characters.
Question: What is the color here?""",
)
Note that the parameters from sf.preview_prompt_lf() stay the same for sf.create_prompt_lf(), with the exception of lf_name which is required to create the prompt LF. In addition, the split and num_examples are no longer needed as the prompt LF votes on all splits.
To learn more information regarding the parameters of sf.create_prompt_lf(), run:
sf.create_prompt_lf?
If you go to Studio (in the left-side menu) for the same node, you should now be able to see the newly created LF under Labeling Functions from the In Progress or Active tab.
Selecting Model Type
Refer to the following table to select the appropriate model_type value based on your application type, label space, and the task type of your selected foundation model.
| model_type | Application | FM Type |
|---|---|---|
"text2text" | Single-Label classification applications | Text2Text |
"text2text_multi_label" | Multi-Label classification applications | Text2Text |
"text2text_qa" | Sequence-label classification applications | Text2Text |
"qa" | Sequence-label classification applications | QA |
"pdf_text2text_extractor" | PDF candidate-based extraction applications | Text2Text |
"doc_vqa" | PDF candidate-based extraction applications | DocVQA |