Built-in operators
In Snorkel Flow, operators perform transformations over DataFrames. Snorkel Flow includes a collection of built-in operators to perform commonly used transformations.
Pipelines that transform DataFrames in Snorkel Flow are constructed via a combination of blocks, where a block is a set of pre-defined operations that perform transformations sequentially.
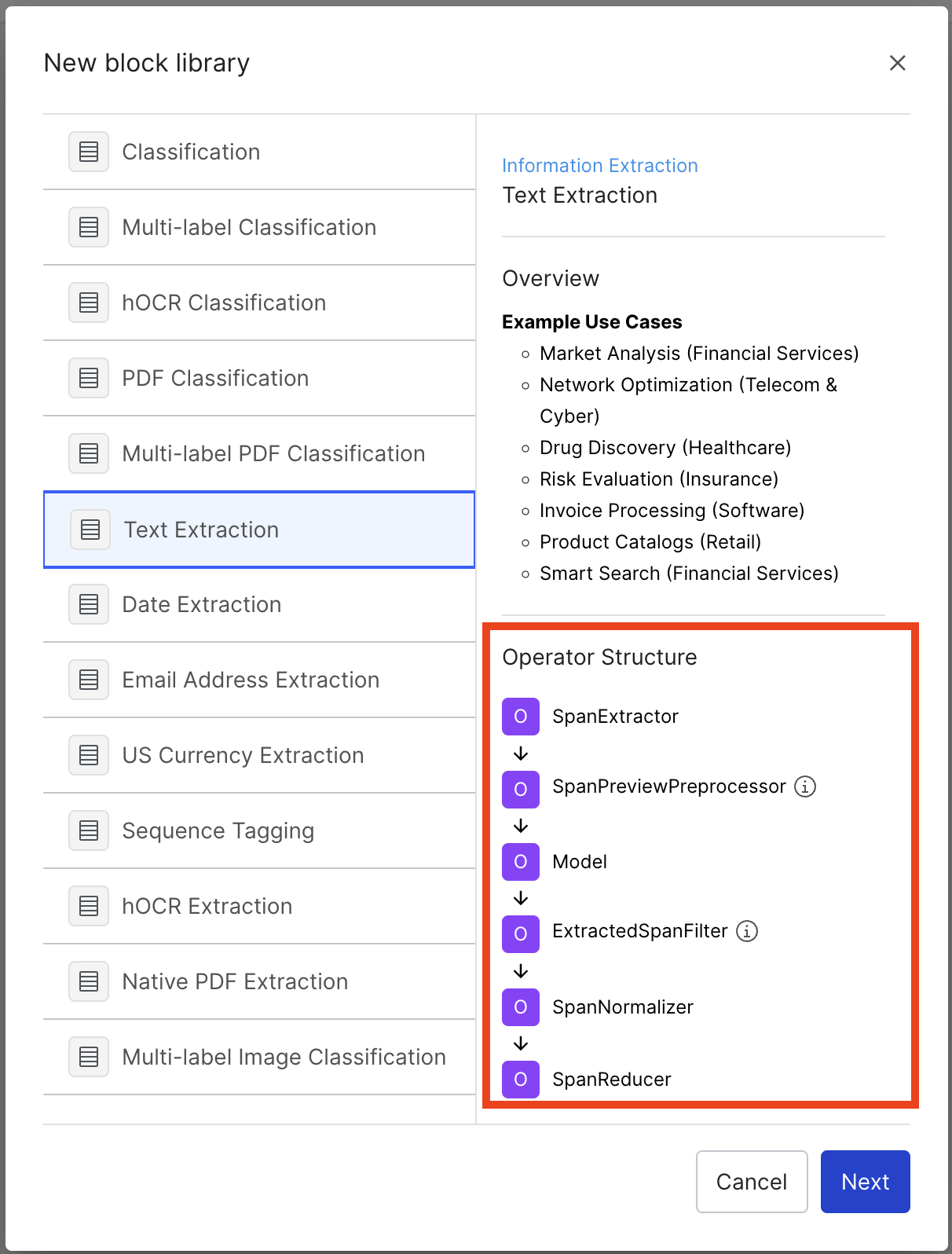
For example, the text extraction block shown below contains 6 operators: SpanExtractor, SpanPreviewPreprocessor, Model, ExtractedSpanFilter, SpanNormalizer, and SpanReducer.
Some operators run automatically while others (e.g., SpanExtractor, Model) require input from the user.
For example, SpanExtractor is a placeholder for selecting a specific span extraction operator for a user's task (e.g. NumericSpanExtractor, DateSpanExtractor).
See a full list of built-in operators.
Further detail on each Built-in operator below.
Featurizers
Featurizers are operators that add one or more columns, all known as features, to a DataFrame.
Text-based
-
Truncate: truncates any field to a maximum token length. By passing the truncated column a name, you can keep the original column as well.
-
Whitespace: converts all non-standard whitespace characters into whitespace. By default, the following UTF-8 non-standard space characters are used with the regular space: U+00A0, U+2000 to U+200A, U+202F, U+205F, U+3000. These can be overridden using the
to_replaceargument. -
SpaCy: applies the spaCy model to a field and produces a new target field containing the jsonified spaCy Doc object. For large datasets of strings, this takes longer to execute.
-
RegisterCustomEmbedding: lets you register an existing embedding column, which enables access to Cluster View. The RegisterCustomEmbedding featurizer has a few key required inputs:
- The Embedding Operator Type field specifies the type of embedding: EmbeddingFeaturizer for text embeddings, and the EmbeddingCandidateFeaturizer for sequence tagging embeddings.
- The Embedding Vector Field specifies which column contains the embedding vectors. Every row of data should have embeddings and should have the same dimension. For example, all rows should be a list of X floats. If not, an error is shown with remediation steps.
- The Embedding Source Field specifies which column the embeddings were computed over. Snorkel Flow requires a source field to compute certain summaries in Cluster View.
- The Embedding Source Candidate Field is optional, specifically for sequence tagging embeddings. This references the context of the sequence tagging task, while the Embedding Source Field references the spans that have been embedded.
This field is a beta feature for candidate embeddings in sequence tagging tasks. If you ned this feature, contact Snorkel.
The RegisterCustomEmbedding featurizer runs a set of checks on the vector column to ensure it is valid. These checks include that the vectors are all the same dimension, contain a list of floats, and are not null.
The RegisterCustomEmbedding featurizer isn’t generating new embeddings. It registers existing embeddings for use within Snorkel Flow.
Model-based
The model and model-based featurizers run predictions over the input data based on the specified feature fields and store those predictions into a prediction column. This featurizer helps to build Model-based Labeling Functions over your data.
In addition, the model-based featurizer can automatically train on any ground truth contained in your data, allowing it to act like a typical supervised model to improve your Label Model.
Model postprocessors
Model postprocessors are useful to post-process or update model predictions. Any postprocessors should be added to the Directed Acyclic Graphs (DAG) after the model node, in the same block as the model node.
- SpanFilterByLengthPostProcessor: filters and removes positive spans with length <= the provided
span_length. - SpanRegexPostProcessor: labels anything that matches the provided pattern with the provided label.
- SpanRemoveWhitespacePostProcessor: removes leading and trailing whitespace in positive spans.
- SubstringExpansionPostProcessor: if a prediction boundary fall mid-token, then it expands predictions to the token boundaries.
- SpanMergeByRegexPatternPostProcessor: if the negative label text in between the spans matches a regex pattern, merges nearby spans with the same label.
- SpanMergeByNumberCharacterPostProcessor: merges nearby spans with the same label, if the negative label text in between the spans is in the lower to upper number of characters (inclusive).
Time-based
TimestampFeatureExtractor: parses a timestamp column (pandas.Timestamp), and adds new columns for the following features: day of the year, day of the week, year, month, day, hour, and minute. These features are useful for building labeling functions or for model training.
PDF Operators
PDF Parsers
We use parsing operators to extract text and its corresponding location in the PDF, and store this information using Snorkel's internal RichDoc representation.
There are two kinds of PDFs—native and scanned. Native PDFs are digitally created (for example, exported from Word) and have metadata that can be read. Scanned PDFs are image-based and do not have this metadata. Scanned PDFs require additional preprocessing as discussed in Optical Character Recognition (OCR).
For datasets containing native and scanned documents, we recommend that you select the scanned PDF workflow.
- PDFToRichDocParser: parses native PDFs. The input to this operator is the column containing the PDF url. This operator uses a PDF parsing library to extract the text and properties of the text, including the bounding box, paragraph, and page in which the text is present. The input PDF should not have any character or font encoding issues for the operator to function correctly.
- HocrToRichDocParser: parses scanned PDFs. This operator relies on the outputs of an OCR model to extract the text and location information from images of documents. The input to this operator is a column containing OCR results in the standard hOCR format.
The parsing operators add the following fields to the dataframe:
- rich_doc_text: contains the raw text from the PDF file. This field extracts candidate spans.
- page_docs: list of RichDoc objects corresponding to each page.
- page_char_starts: list of start character offsets (the index of the first character in the page in the
rich_doc_text) corresponding to each page. - rich_doc_pkl: serialized object that corresponds to
rich_doc_text.
Optical Character Recognition (OCR)
Scanned PDF documents require the use of Optical Character Recognition to convert images to machine-encoded text. Users may run any OCR library outside the Snorkel platform, if the output is in the standard hOCR format. Snorkel Flow includes built-in libraries to run OCR. These operators are run before the HocrToRichDocParser:
- TesseractFeaturizer: uses the open-source tesseract library to extract OCR. The operator takes PDF URLs as input and outputs a hOCR string.
- AzureFormRecognizerParser: uses Azure Form Recognizer. The user is required to set up an account and provide their own form recognizer credentials. The operator takes PDF URLs as input and outputs hOCR.
For more information please see the Scanned PDF guide.
PageSplitter
The PageSplitter operator splits PDF documents into sub-documents or pages. This function allows Snorkel Flow to store data and compute labelling functions more efficiently. However, it restricts the context available when writing the labeling function (LF) to the page or sub-document.
For performance reasons, the PageSplitter is strongly recommended for large documents. Split any documents that are greater than 20 pages. Snorkel Flow filters out documents that are larger than 100 pages.
To use the default PageSplitter, select the PageSplitter when setting up your application:
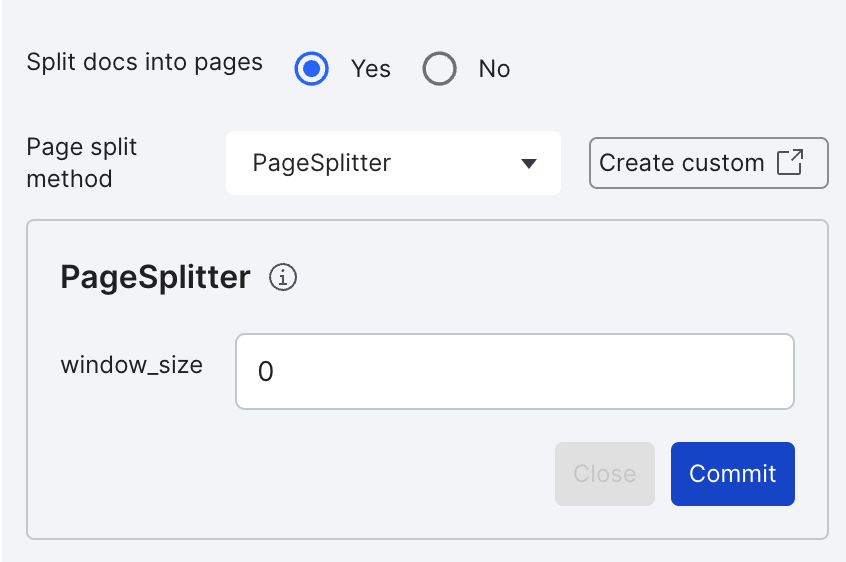
The window size specifies the number of pages before/after the current page that can be used as context for writing LFs. Use a window size of fewer than 10, and prevent window sizes greater than 50.
Snorkel Flow also supports the use of user-defined custom PageSplitters. For example, you can split documents based on sections. For more information, see the custom operator documentation.
Candidate Span Extractors
PDF information extraction applications require users to define candidate span extractors. This treats an extraction problem as a classification problem. Span extractors are defined by using a heuristic and/or model over the rich_doc_text field. This operator converts the dataframe from having a document or page in each row, to having a span in each row. For more information on built-in extractors, see Extractors.
PDF Featurizers
The following built-in featurizers add columns to the dataframe that are useful for rendering documents and defining labeling functions in Studio:
- RichDocPagePreprocessor: filters out RichDoc pages that do not contain any candidate spans. This is useful for rendering only the relevant pages in Studio.
- RichDocSpanBaseFeaturesPreprocessor: computes basic RichDoc features for each span, such as the bounding box coordinates, page number, and font size.
- RichDocSpanRowFeaturesPreprocessor: extracts row-level features such as the previous row, next row, and the row header (text to the left and top of the span that is closest to the span).
Object Detection Featurizers
Detecting layout features from the PDF image can be useful for defining labeling functions and extracting certain entities. The following built-in object detection operators are available in Snorkel Flow:
Line Detection
- LinesFeaturizer extracts all visual horizontal and vertical lines from a specified pdf page. This operator uses morphological operations. The output from this operator can be used to filter pages or combine words between lines with the TextClusterer operator.
Checkbox Detection
To enable checkbox detection in PDF documents and use the checkbox-related features when writing label functions, add the CheckboxFeaturizer and CheckboxSpanMapper operators to the application DAG.
CheckboxFeaturizer detects checkboxes in PDF documents. This operator also detects if the checkboxes are checked or not based on the threshold ratio (1.0 - 0.0). You must specify the minimum and maximum range of the checkboxes to detect. To use the detected checkboxes when writing LFs, you must add the CheckboxSpanMapper operator to the DAG.
Based on the provided criteria, CheckboxSpanMapper maps the detected checkboxes to the already extracted spans in the PDF document. You must specify the pixel distance and the four directions in which to map them. This operator must be added after the RichDocSpanBaseFeaturesPreprocessor operator in the DAG.
For each of the directions selected, a new column designating the status of the checkbox is added. For example, when left and top checkbox options are selected, the is_left_checkbox_checked and is_top_checkbox_checked columns are added with integer values. The columns will have one of the following values:
- 1: The corresponding span has a checkbox detected in the specified direction within the distance. The detected checkbox is checked.
- 0: The span has a checkbox detected in the specified direction within the distance. The detected checkbox is unchecked.
- -1: The span does not have any checkbox detected in the specified direction within the distance.
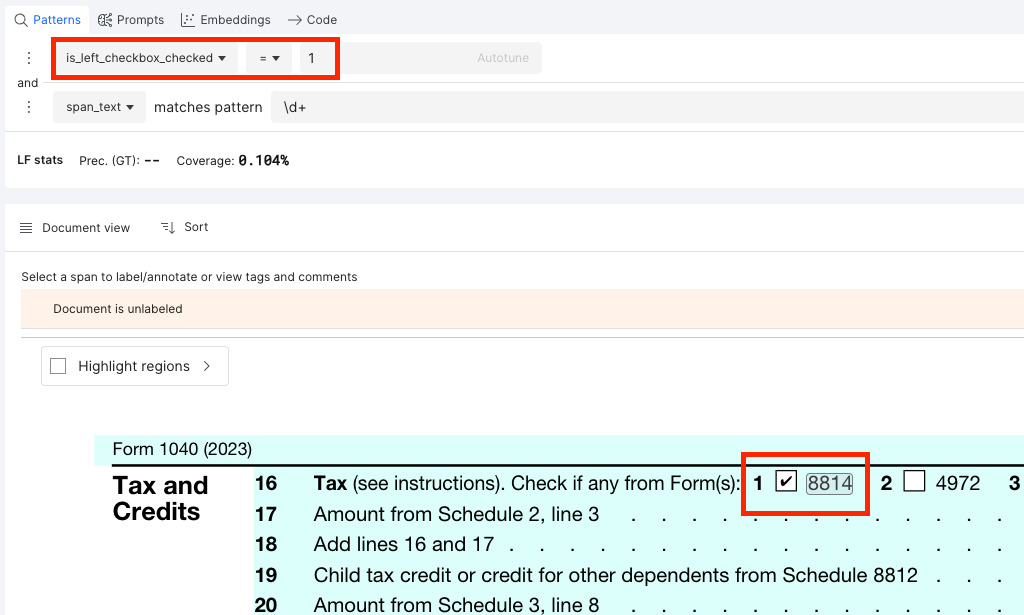
To define a labelling function using this field, use the Numeric Builder. For example, if the user wants to detect numerical spans with a checkbox checked on the left side of it, the label function can be a combination of the following conditions:
- is_left_checkbox_checked = 1: Check if the span has a checkbox mapped on the left side of it and if the checkbox is checked.
- span_text matches pattern \d+: Using regex if the span has only numbers in it. This is an example condition. Other conditions can be used as needed.
Layout Detection
- DocumentLayoutFeaturizer: computes layout features in a document using a deep learning model from the Layout Parser library. The Model dropdown can be used to select models from the library. Resolution specifies the input resolution of the image in DPI. Confidence threshold specifies the threshold used to filter the predictions. The Pages field optional input can be used to run the deep learning model on a subset of pages.
- TableRowFilter: filters out rows without tables. This requires the outputs from the DocumentLayoutFeaturizer operator.
Table Detection
The Table Transformer model detects tables and table structures. This featurizer is implemented using the following operators:
- TableFeaturizer operator computes the model predictions over PDF pages and saves the outputs in the tables column. Add this operator after the PDF parser node in the Application DAG. The operator has the following inputs:
- field: column with the PDF URL path.
- model: pretrained model name. The user can select any pretrained model that is compatible with the TableTransformerForObjectDetection class. Start with
microsoft/table-transformer-detectionormicrosoft/table-transformer-structure-recognition. - pages field: runs the model over a subset of pages in the document. If the document has been split using PageSplitter, enter context_pages for this field.
- TableSpanMapper operator maps the table predictions to spans. Add this operator before the Model node. Add this operator after the RichDocSpanBaseFeaturesPreprocessor operator in the DAG. The operator takes the model confidence threshold as input. This is set to 0.9 by default. It outputs the following fields to the dataframe:
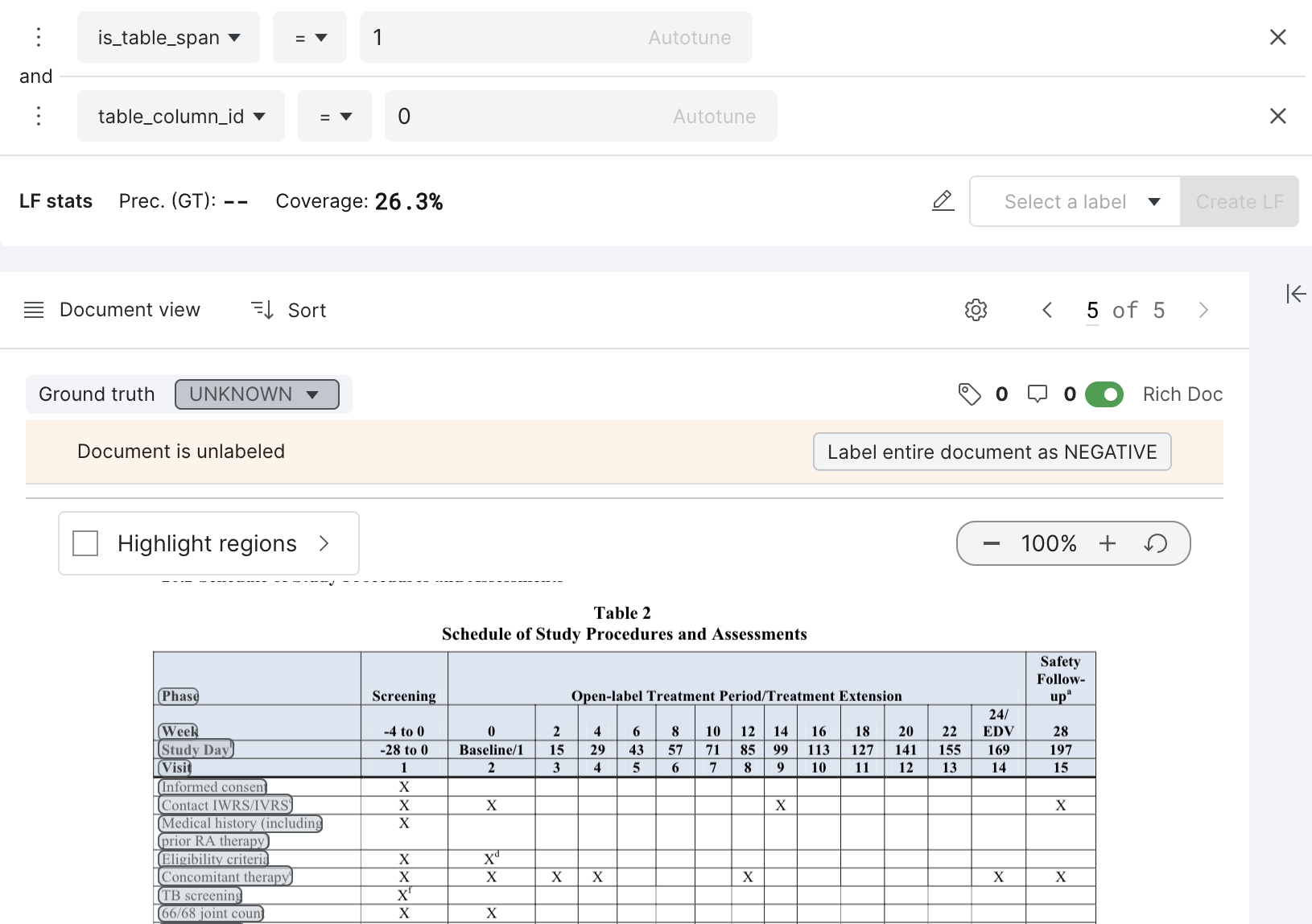
- is_table_span: an integer value indicating if the span was within a table. It is set to 0 if outside all tables, and 1 if span is within a table.
- table_column_id: an integer value indicating which column the span belongs to.
To define a labelling function using the fields, please use the Numeric Builder. This can be used to encode logic similar to the example below:
Filters
- Label: includes or excludes rows corresponding to specified label strings.
- Label Int: includes or excludes rows corresponding to specified label integers.
- Pandas Query: includes or excludes rows based on a pandas query.
- Boolean Column: includes or excludes rows based on the value of a boolean column.
- Text Size: excludes rows with text columns that are larger than specified size (in KB).
For text extraction blocks, select a filter that removes all candidates according to certain criteria:
- Regex Span: removes all candidates that match a regular expression.
- Extracted Span: filters all span rows with a negative prediction.
Extractors
Text extraction blocks require at least one extractor over a field:
-
Noun Chunk: yields all noun phrases according to spaCy.
- Per spaCy’s implementation, the noun chunker iterates over all base noun phrases in a document. A base noun is a noun phrase that does not permit other NPs to be nested within it.
- Example: For the text
Hi, my name is Dr. Bubbles!, this extractor returns two spans:my nameandDr. Bubbles.
-
Regex: yields all matches for a given regular expression.
- By default, the entire match is returned. You can specify capture group = 1.
- For example, to extract only the span that matches what’s inside the first group of parentheses.
r"$([0-9]+)"withcapture group = 1would extract only the45in$45.
-
Date: yields all the dates in documents via a pre-defined regex.
-
The regex pattern is:
(?:[0-9]{1,2}(?:st|nd|rd|th)?\s*(?:day)?\s*(?:of)?\s*.?(?:(?:Jan(?:.|uary)?)|(?:Feb(?:.|ruary)?)|(?:Mar(?:.|ch)?)|(?:Apr(?:.|il)?)|May|(?:Jun(?:.|e)?)|(?:Jul(?:.|y)?)|(?:Aug(?:.|ust)?)|(?:Sep(?:.|tember)?)|(?:Oct(?:.|ober)?)|(?:Nov(?:.|ember)?)|(?:Dec(?:.|ember)?)),?.?\s*[12][0-9]{3})|(?:(?:(?:Jan(?:.|uary)?)|(?:Feb(?:.|ruary)?)|(?:Mar(?:.|ch)?)|(?:Apr(?:.|il)?)|May|(?:Jun(?:.|e)?)|(?:Jul(?:.|y)?)|(?:Aug(?:.|ust)?)|(?:Sep(?:.|tember)?)|(?:Oct(?:.|ober)?)|(?:Nov(?:.|ember)?)|(?:Dec(?:.|ember)?)).?\s*[0-9]{1,2}(?:st|nd|rd|th)?\s*(?:day)?\s*(?:of)?,?.?\s*[12][0-9]{3}) -
Example: for the text
Today is January 1, 2021. And tomorrow is 01/02/2021, this extractor will only return theJanuary 1, 2021span. -
See the Spacy NER section for an alternative extractor for dates.
-
-
US Currency: yields all US monetary values via a pre-defined regex.
- The regex pattern is:
\\$([0-9]{1,3},([0-9]{3},)*[0-9]{3}|[0-9]+)(\\.[0-9][0-9])? - Example: For the text
5 bucks (or $5.00) is actually €4.10., this extractor returns the span$5.00. - See Spacy NER for an alternative extractor for currency.
- The regex pattern is:
-
Spacy NER: yields all matches for a given NER tag according to spaCy.
spaCy’s NER models were trained on the OntoNotes 5 corpus and can predict several span labels:PERSON: People, including fictionalNORP: Nationalities or religious or political groupsFAC: Buildings, airports, highways, bridges, etc.ORG: Companies, agencies, institutions, etc.GPE: Countries, cities, statesLOCATION: Non-GPE locations, mountain ranges, bodies of waterPRODUCT: Vehicles, weapons, foods, etc. Excludes servicesEVENT: Named hurricanes, battles, wars, sports events, etc.WORK_OF_ART: Titles of books, songs, etc.LAW: Named documents made into lawsLANGUAGE: Any named languageDATE: Absolute or relative dates or periodsTIME: Times smaller than a dayPERCENT: Percentage (including%)MONEY: Monetary values, including unitQUANTITY: Measurements, as of weight or distanceORDINAL:first,secondCARDINAL: Numerals that do not fall under another type
-
Token: yields every token, given a selected tokenization strategy.
Tokenization options include
spacy(see implementation) andwhitespace, which captures tokens by the regex\S+.
Entity classification blocks support another pre-processor that serves as an extractor and linker:
-
EntityDictSpanExtractor: extracts all candidates according to a pre-specified dictionary of entities and links them to a canonical form. The dictionary should map each canonical form to a list of aliases:
{canonical_form: [alias1, alias2, ...], ...}.
This extractor includes these options:ignore_case: whether to ignore casing when matching entities.link_entities: whether to link aliases with their canonical form as thespan_entity.
-
DocEntityDictSpanExtractor: extracts all candidates according to a pre-specified dictionary of entities, filter by a dictionary of documents to expected entities, and link them to a canonical form.
- The
entity_dict_pathspecifies a dictionary to map each canonical form to a list of aliases:{canonical_form: [alias1, alias2, ...], ...}. - The
doc_entity_dict_pathspecifies a dictionary to map each document UID to a list of expected span entities:{context_uid: [entity_1, entity_2, ...], ...}.
- The
This extractor includes these options:
-
ignore_case: whether to ignore casing when matching entities.link_entities: whether to link aliases with their canonical form as thespan_entity.
- EntityDictRegexSpanExtractor: extracts all candidates according to a pre-specified dictionary of regexes and links them to a canonical form. The dictionary maps each canonical form to a list of regexes:
{canonical_form: [regex1, regex2, ...], ...}.
This extractor includes these options:ignore_case: whether to ignore casing when matching entities.link_entities: whether to link regex with their canonical form as thespan_entity.
- TextClustererExtractor: extracts all the horizontally and vertically clustered texts. Texts that are horizontally clustered form a span. The vertically clustered texts are extracted under region_text.
Normalizers and linkers
In extraction-based blocks, select normalizers or linkers that map the span_text to a more canonical normalized_span field.
- Dates: transforms all dates found in extracted spans into the
YYYY-DD-MMformat. - US currency: transforms all US dollar values into a standard value by removing all special formatting (such as dollar signs, commas, and whitespace) and then casting the numeric value to float.
- Capitalization: transforms all string values to lowercase and only capitalize the first letter. This is helpful when working with candidates that refer to cities, names, etc.
- Numerical: transforms all numbers into words (e.g.,
42toforty two). - Ordinal: transforms all ordinal values to words (e.g.,
42ndtoforty second). - Entity Dict Linker: maps existing candidate spans to a canonical form. This is similar to the above extractor, except it skips the tagging step.
- Span-Entity: assumes that normalized spans are already defined by the
span_entityfield.
Span-based
Under Advanced Settings, extraction blocks allow the following load-processors:
- Span Joiner: joins extracted candidates with their original contexts.
- Span Previewer: adds a field containing a localized preview of an extracted candidate. You can adjust the character window to change how many characters around the extracted span are included in the
span_previewfield. - Context Aggregator: adds a
context_spanscolumn with aggregated spans for the currentcot_uid. This can help express notebook LFs related to other spans in the same document.
Filters
The same filters specified in the Featurizers section are available as post-processors. These are useful if you want to filter examples based on the model prediction.
By default, extraction blocks also include an ExtractedSpanFilter to remove any negative span predictions.
Reducers
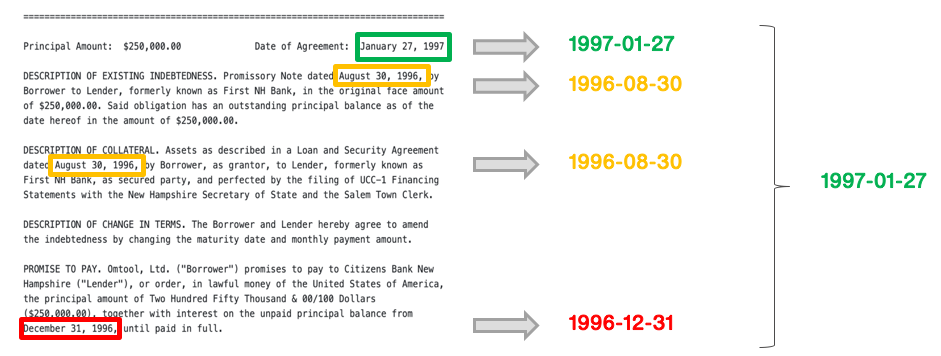
Reducers heuristically aggregate, select, or convert candidate-level predictions to become document or entity-level extractions. For instance, you might know for your text extraction block, you may expect one extraction per document. In this case, you apply a reducer that selects the most-confident span per document.
Similarly, in a company sentiment classification block over news articles, you may expect a single classification per document-entity pair. You can apply a most-common reducer to find the most common sentiment for a particular company in a document.
Snorkel Flow currently supports the following reducers in document/entity-level varieties:
- Most Confident: selects the most confident span-level candidate based on confidence measured by model probabilities.
- First: selects the first positive occurrence of an extraction in a particular document.
- Last: selects the last positive occurrence of an extraction in a particular document.
- Most Common: selects the most common candidate as the extraction for a particular document.
Miscellaneous
- ColumnDropper: drops one or more columns from your DataFrame.
- ColumnRenamer: renames one or more columns in your DataFrame. For example,
{"old_column_name": "new_column_name"}.
Post-processors in extraction blocks
Filters, normalizers, and reducers are examples of post-processors that operate over model predictions. After applying post-processors in extraction blocks, you’ll be able to see document or entity-level metrics. For an end-to-end example of this, see Information extraction: Extracting execution dates from contracts.
Embedded data table viewer
Enhance data exploration of your tabular data by utilizing the embedded table data viewer. This functionality visualizes any columns that have nested information.
Data format prerequisite
To be compatible with the TableConverter operator, the format for each row in the column to be converted should be a list of elements or dictionaries. All dictionaries also need to have the same key names and number of keys.
If converting from a pandas dataframe, use the sample code below. This code creates the list of elements for one row in your dataset:
filtered_df_per_row.to_dict(orient='records')
Example of a properly formatted list to be converted:
[{"name":"Christie","email":"christi@gmail.com","role":"sender", "source_ip":"127.0.0.1"},
{"name":"Jennifer","email":"Jennifer@gmail.com","role":"receiver-main","source_ip":""},
{"name":"bob","email":"bob@gmail.com","role":"receiver-cc","source_ip":""}]