Manage batches and commit ground truth
This page walks through how to manage your batches and commit annotations to your ground truth to be used for development in Studio.
Ground truth refers to the set of labeled and accurately annotated data that serves as a reference or benchmark for training and evaluating machine learning models. During the evaluation phase, ground truth data is used to assess the model's performance. By comparing the model's predictions with the actual labels in the ground truth, metrics such as accuracy, precision, recall, and F1 score can be calculated.
Snorkel Flow allows you to programmatically generate labels for your training split. Snorkel recommends using ground truth (GT) labels for data points in other splits:
- In the dev split, GT-labeled examples assist with discovering and iterating on labeling functions (LFs).
- In the valid and test splits, use GT-labeled examples to evaluate model performance and facilitate error analysis.
Manage your batches
-
Once create your batches, you can manage the batches in Dataset view from the Batches tab.

-
On the top bar, select the action you want to take:
- Select the + Create a new batch button to create a new batch of data points for annotation.
- Select the Filters button to filter the batches by annotator or status.
- Select the Toggle bulk options
 icon to show the option to bulk delete batches.
icon to show the option to bulk delete batches. - Select the Export dataset across all batches
 icon to export all batches to a CSV file.
icon to export all batches to a CSV file.
-
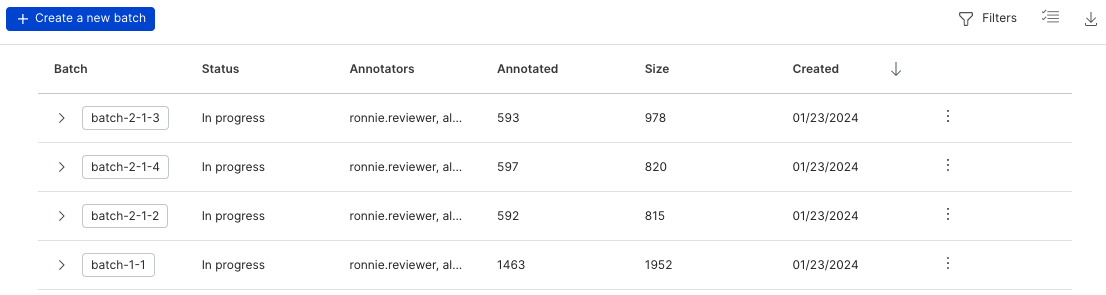
For individual batches, the following information is available:
- Date: The date the batch was created.
- Name: The name of the batch.
- Label schemas: The label schema(s) associated with the batch.
- Batch Size: The total number of data points in the batch.
- Annotators: The list of annotators that have been assigned to annotate the batch.
- Annotate: The button to start annotating the batch.
On the top bar, select the action you want to take:
- Create new batch: Select the + Create a new batch button to create a new batch of data points for annotation.
- Search batches: Use the search bar to search for a specific batch by name.
- Export data: Select the Export dataset across all batches icon to export all batches to a CSV file.
-
Enter the following options in the Export annotation batches modal:
- Include columns: Specify which columns to include in the export. This option enables you to select a focused slice of your data, or you can speed up export time by excluding large columns in a dataset.
- Include options: Specify additional information about individual data points to include such as annotations, comments, tags, filters applied, and model predictions.
- Optional settings: Specify additional options to customize your export. These options include the ability to start an export at a specific index in the dataset, setting a maximum number of data points to export, and options to configure delimiters, quote characters, and escape characters.
Manage individual batches
Select the arrow  icon next to the batch name to view additional information about an individual batch. This menu give you additional actions you can take on an individual batch:
icon next to the batch name to view additional information about an individual batch. This menu give you additional actions you can take on an individual batch:
- Aggregate: Aggregate annotations from multiple annotators.
- Commit: Commit annotations to the ground truth.
- Set as expert: Mark selected annotator(s) as an expert for the batch. To mark an individual annotator as an expert for the batch, select the annotator, and then click Set as expert. A badge icon shows up next to the annotator's name to indicate the expert status.
- Remove expert: To remove the expert designation for an annotator, select Remove expert.
- Edit batch details: Batch name and annotators list can be updated by clicking on Edit icon for a batch.
- Export batch data: Export the batch data to a CSV file.
- Delete batch: Deletes the batch.
Aggregate annotations
Typically, you'll have more than one annotator reviewing and labeling documents. You can only commit a single vote to ground truth. You can aggregate annotations instead of committing the annotations from a single person. This aggregation helps eliminate potential bias from any particular annotator.
To aggregate annotations, select the annotators that you want to aggregate, then select Aggregate.
A majority vote is the only supported aggregation strategy. This strategy takes the majority label for each data point if one exists, and leaves an UNKNOWN label where no annotations exist. These results create a new set of annotations with a single vote for each data point. The aggregated annotations can be seen in the expanded view of batch on the Batches page, under Other annotations.
The majority vote aggregation algorithm works differently for each of these task types.
Single-label
Snorkel Flow uses a simple majority algorithm as the aggregation strategy for single-label applications. Based on the number of votes for each label, the label with the most votes is applied to the ground truth as the final decision.
For example, consider a single-label application with ten annotators and two classes. Six annotators label a data point with class A, and four annotators label a data point with class B. Because class A now represents the majority vote at aggregation time, the aggregated result will label this data point as class A.
If there is a tie between two or more majority labels, Snorkel Flow uses a pre-determined random seed to perform a random choice selection.
Multi-label
Snorkel Flow uses a simple union algorithm as the aggregation strategy for multi-label applications. Based on the number of present/absent votes for each class, Snorkel Flow applies the label (present or absent) with the most votes for each class as the final decision.
For example, consider a multi-label application with ten annotators and two classes. For class A, six annotators vote present and four annotators vote absent. For class B, four annotators vote present and six annotators vote absent. By taking the majority vote of each class, the aggregated label for the data point applies present for class A and absent for class B.
If there is a tie between present and absent labels, the resulting label has an equal chance of being marked as present or unknown.
Sequence tagging
Snorkel Flow uses a simple majority algorithm as the aggregation strategy for each character in a span in sequence tagging applications. Based on the number of votes for each label in any interval where annotators disagree, Snorkel Flow selects the label with the most votes as the final decision.
If there is a tie between two or more majority labels, the resulting label is a negative class to reduce the risk of false positives, such as trailing spaces or mistaken tokens. If the tie is between only positive labels, the resulting label is a pre-determined random seed to perform a random choice selection.
Commit annotations
Once you have a set of annotations that are accurate, commit the annotations as the ground truth for development in Studio.
Only users with the Developer or Administrator role can commit ground truth.
- Select the desired annotation set. You can select annotations from either an individual annotator or from an aggregated set of annotations.
- Select Commit.
Once you commit annotations, the new annotations overwrite the existing ground truth labels in the data source.
Format for ground truth interaction in the SDK
This section shows example formats for each label space for usage in our SDK for a given datapoint.
Multi-label spaces ground truth is represented as a dictionary where there is a mapping from each label to one of PRESENT, ABSENT, or ABSTAIN:
label: {"Japanese Movies": "PRESENT", "World cinema": "ABSTAIN", "Black-and-White": "ABSENT", "Short Film": "ABSTAIN"}
Sequence tagging ground truth for a document is a list of spans, where each span is a triple of (char_start, char_end, label). The spans cannot be empty (char_start must be smaller than char_end). Overlapping or duplicating spans are not allowed. The sets of char offsets (char_start, char_end) must be sorted:
label: \[ \[0, 29, 'OTHER'\], \[29, 40, 'COMPANY'\], \[40, 228, 'OTHER'\], \[228, 239, 'COMPANY'\], \[239, 395, 'OTHER'\], \]
Single label space ground truth format is represented by their class label
label: "loan"