Create batches
This page walks through how you can create batches of documents for manual annotation when the dataset uses multi-schema annotations.
To create batches and commit annotations to ground truth, you must have the Developer role. For more information about access and permissions, see Roles and user permissions.
What are batches?
Before documents can be annotated in Annotation Studio, they must be assigned to batches. A batch is simply an arbitrary collection of data points—it can be as large as an entire split or data source or as small as a few examples.
Typically, you'll want documents manually annotated at a couple different points during the data development process:
- At the beginning of a project so that you can get some initial ground truth to begin development.
- During labeling function (LF) and model development. The development cycle is an iterative process and you may want to introduce more datapoints with ground truth. The reasons may be to improve the inbalances in the dataset, or simply to add more training data.
How to create batches
There are two ways that you can create batches in Snorkel Flow:
- Dataset Page: Best method to use if you want to quickly create batches for an entire split or data source.
- In-platform notebook: Best method to use if you have a specific list of
x_uids that you want to create batches from.
All batches that you create can be seen and managed in the Batches page. This page can be accessed by going to the dataset page, then clicking Batches as shown below.
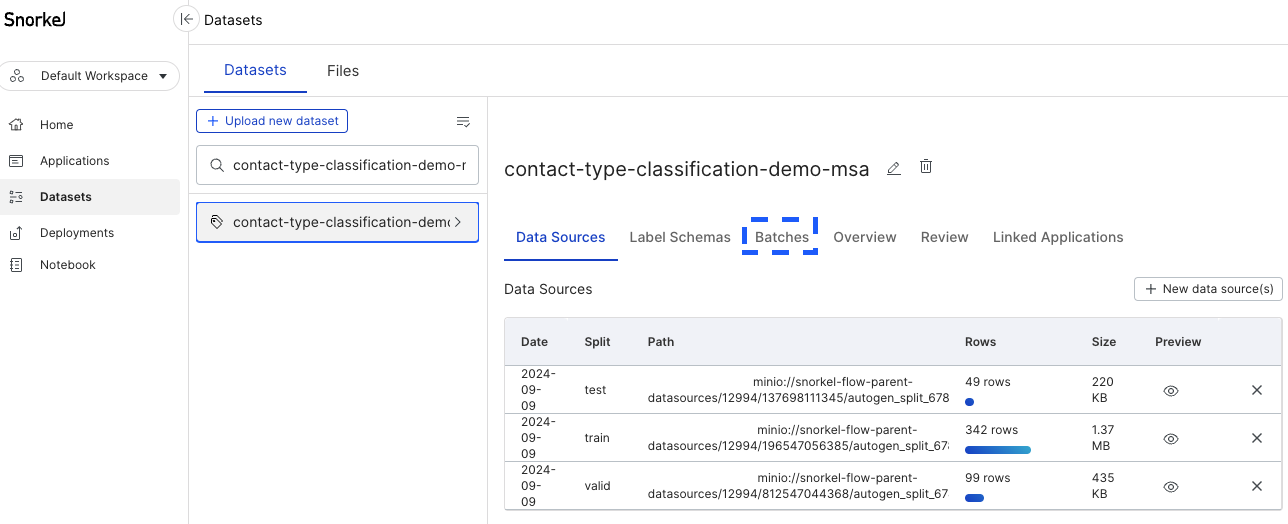
Create batches in the Dataset page
The easiest way to create batches is in the Batches page from the dataset page.
-
Go to the Batch page.
-
Select + Create a new batch to bring up the Create new batch modal.
-
Specify the following options:
- Batch name: A name for the batch. If you choose to create multiple batches (by setting the Number of batches option to a value greater than 1), then each batch will be named the specified name with an appended numerical index to differentiate the batches.
- Select a split: Specifies with which split to create the batch. Each batch comes from a single source—either a split, a data source, or an existing batch.
- Label schema(s): Specifies the label schemas to use for the batch.
- Number of batches: Specifies how many batches to divide the data source into. The default value is 1 but you can specify a value up to 100.
- Batch size: Specifies the number of data points in each batch. The maximum batch size that you can specify is 10,000 data points. If no value is provided, it will divide the data source as evenly as possible among the specified Number of batches.
- Shuffle data order: Shuffles the order of the data points in your data source. Batches are created by selecting data points in order up to the Batch size that you specify. This option enables you to randomly sample which data points go into each batch.
Once you are happy with your selections, click Create Batch. The new batch or batches can now be seen on the Batches page.
Create batches with the in-platform notebook
You can also create batches using the SDK in the in-platform notebook. This method is convenient if you have a specific list of x_uids that you want to create batches from.
You can create batches in the SDK using the Dataset.create_batches function. Some examples of how to use the function can be seen below. You can search Dataset.create_batches in the SDK documentation for more information about the parameters.
ds = Dataset(name="dataset_name", uid=0, mta_enabled=True)
# Creating batches with default parameters.
ds.create_batches(name="notebook_batch", assignees=[5,6], split='train')
# Creating a batch with specific data points using the index. Data points must be from the same split.
ds.create_batches(name="notebook_batch", assignees=[5,6], x_uids=["span::5", "span::7"])
# Creating batches with a fixed number of data points.
sf.create_batches(node, username="assigner", assignees=["user 1", "user 2"], batch_size=10)
The created batches can be seen and managed in the Batches page at the dataset page.