Creating good labeling functions
This article will cover both high-level guidance as well as specific tips for writing good labeling functions (LFs).
High-level guidance
Good LFs:
-
Correct existing model or training dataset errors.
-
Expand the coverage of programmatic labels for a label class.
-
Have high precision.
notePrecision does not need to be at 100%. Snorkel Flow's UI highlights the precision with red if it is too low.
-
Can be crafted quickly. You should plan to write many LFs and perform many training iterations.
To write good LFs:
- Train a model as soon as possible. Then, use error analysis tools and filters to write "corrective LFs" to inject signal where the current model and/or training dataset needs it the most -- the existing errors.
- Start with the obvious and move quickly. For your first 10 LFs, try not to focus too much on perfecting each LF. You can always edit and perfect your LFs later.
- Do thorough data discovery. Use our extensive set of filters, clickable error buckets in our analysis tools, embeddings clusters, etc. to discover patterns in the data that you can encode as LFs.
- Create as many labeling functions as you can for each class. If a single rule could describe a class with 100% coverage and precision, you probably wouldn't need a model to begin with.
- Explore the wide variety of labeling function builders.
Labeling data when starting a new task
-
Discover the data to get ideas for labeling functions. Start by paging through a few examples, filtering by ground truth class, and switching between data views.
-
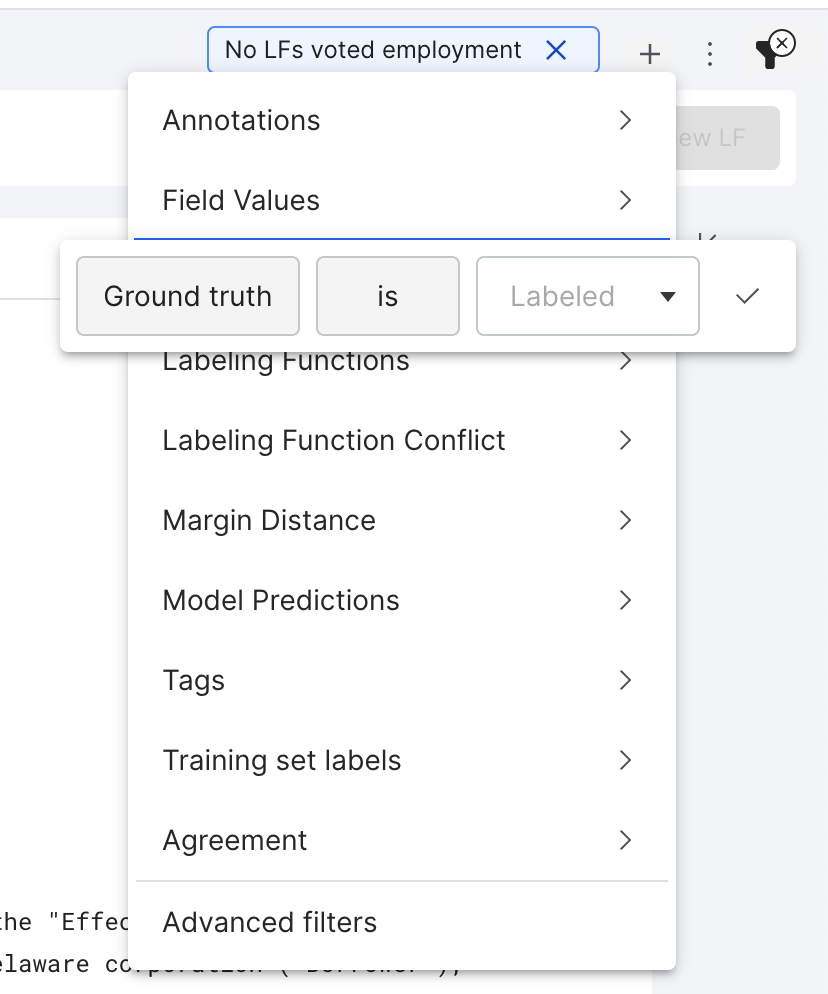
You can use filters to hone in on specific datapoints.
noteFiltering by ground truth label will limit you to only data points with ground truth labels – you may also want to look through some of the unlabeled dataset to get ideas!
-
Your goal should be to write one high coverage and empirical precision labeling function per class to train your first model and get started with error-guided data development.
If you have access to Foundation Models, an easy way to get started is to use a prompt LF to generate labels using the Foudnation Model's predictions.
-
The empirical precision in Label Studio is just a rough estimate given the data in current split. Increasing the accuracy of your labeling functions will help the performance of your model, and as a loose guideline**, we recommend refining any LFs that show up as “red” in the interface**. To refine your LF:
-
Use the
View IncorrectandView Correctfilter buttons to see data points where the LF was incorrect. Try making the LF pattern more specific and re-saving the LF to overwrite the old one. -
Add conditions to your LF using the Add condition and Negate options in the advanced options dropdown menu.
-
If you suspect your LF might be more accurate than the current estimates show, try filtering to where your LF voted but the ground truth label is UNKNOWN and supplying new ground truth labels for these examples. This might also reveal ways to refine your LF.
You can optionally view metrics on (GT) instead of estimated metrics
-
-
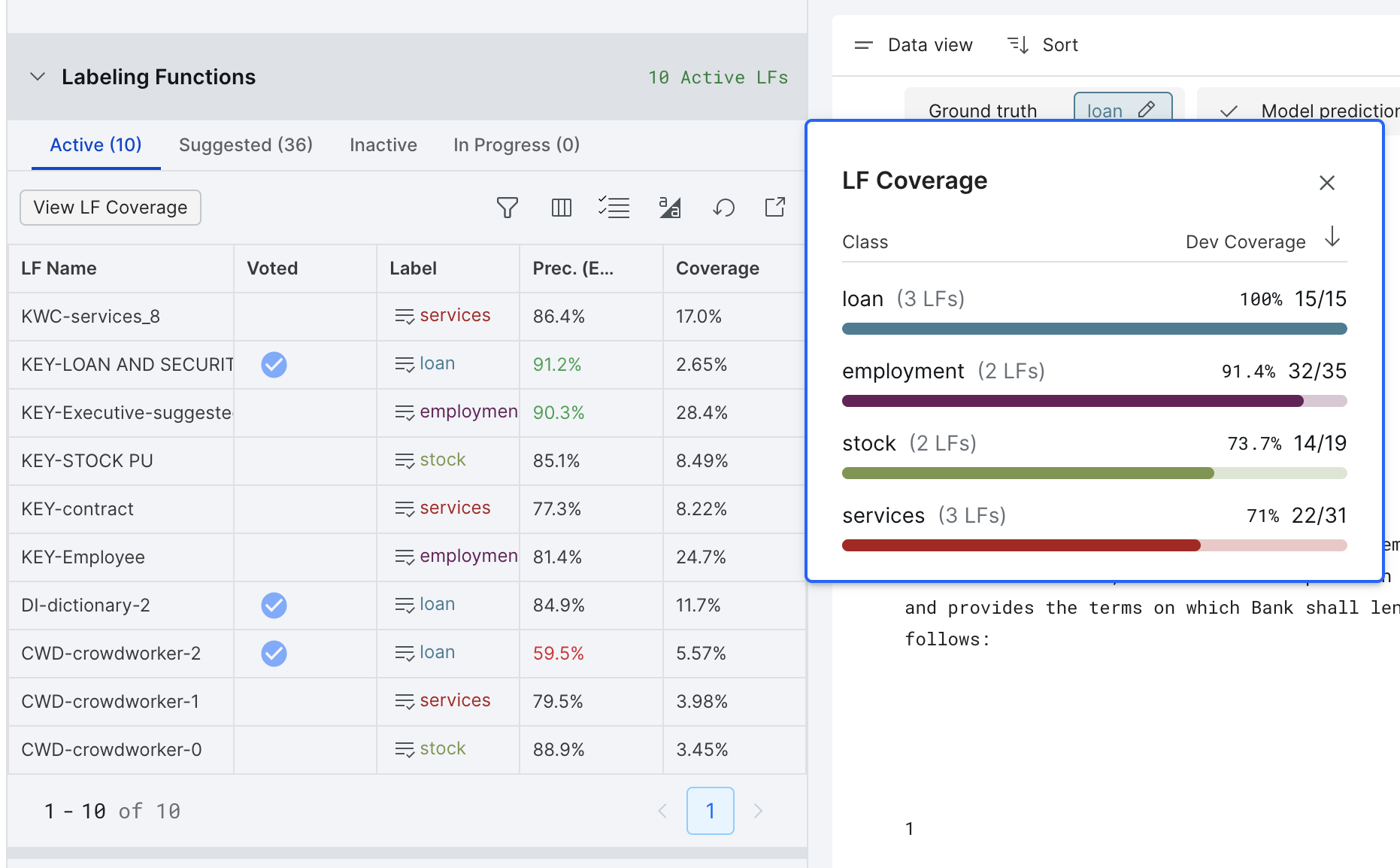
It is not necessary to achieve 100% coverage -- models can generalize.
-
As you move through, you can also assign Ground Truth (GT) labels easily with keyboard shortcuts.
- GT labels will also be used for error analysis, identifying what types of examples your model currently makes mistakes on.
-
Start error-guided analysis quickly.
The fastest way to do this is by training a model in SnorkelFlow on a Foundation Model's predictions using our prompt builder. There's no need to re-label what out of the box model already gets correct, and this will expose error buckets that can be easier to analyze and correct than the entire dev set or the entire labeled class.
Using the analysis pane to create LFs
After training a model, the Analysis pane will guide the refinement of existing LFs and the creation of new ones.
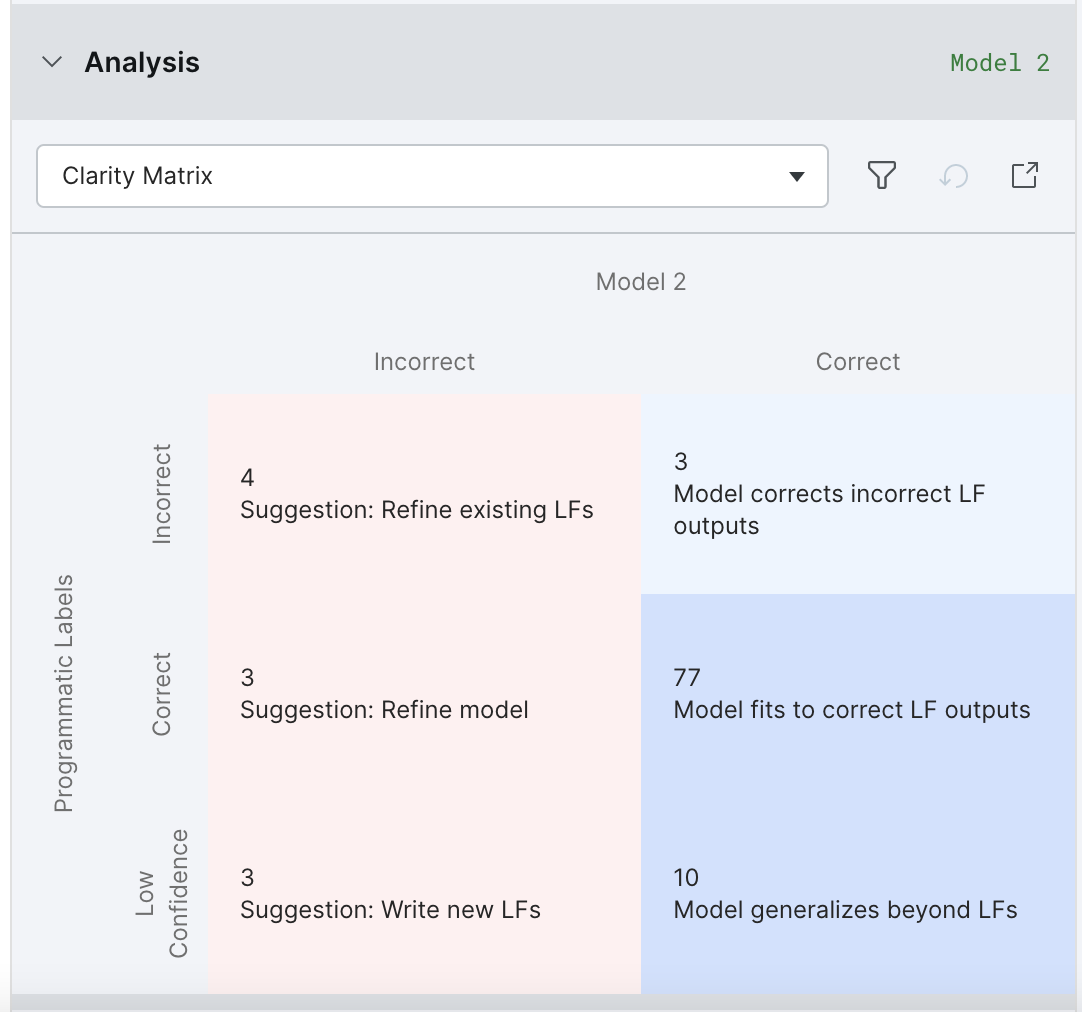
The Clarity Matrix shows how your model’s predictions fared relative to the labels from your labeling functions (de-noised and combined by Snorkel Flow) at a high level:
-
The upper-left cell with Suggestion: Refine existing LFs shows data points where the model is incorrect because the labeling functions were incorrect.
Select this cell to view and refine the incorrect labeling functions.
-
The middle-left cell with Suggestion: Refine model shows data points where the labeling functions were correct but the model was incorrect.
If after iterating on your LFs, this cell has the most errors as indicated by a higher number and a more saturated color, then you should select this cell to return to the models page and try a more powerful and/or better-tuned model.
-
The lower-left cell with Suggestion: Write new LFs shows data points where all of the labeling functions abstained, and the model did not successfully generalize.
Select this cell to write new labeling functions that cover these data points.
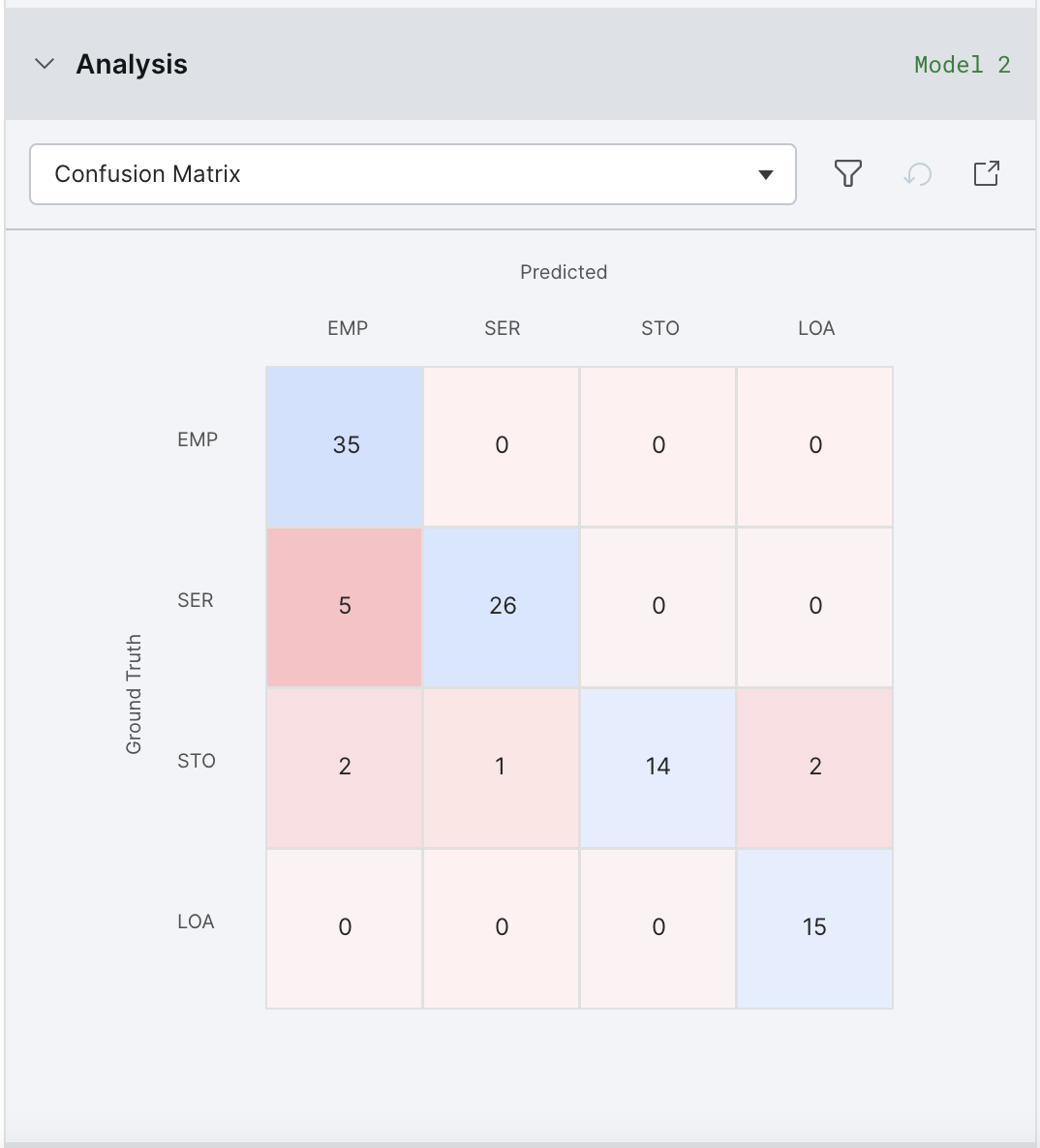
The Confusion Matrix shows where the model confused one class for another (within the off-diagonal buckets). You can click on these to filter data points and write or edit labeling functions to correct this error mode. For example, the below shows that 2 of the 15 loans are instead classified as employment. Clicking on that box would be a good place to start refining your labeling functions.
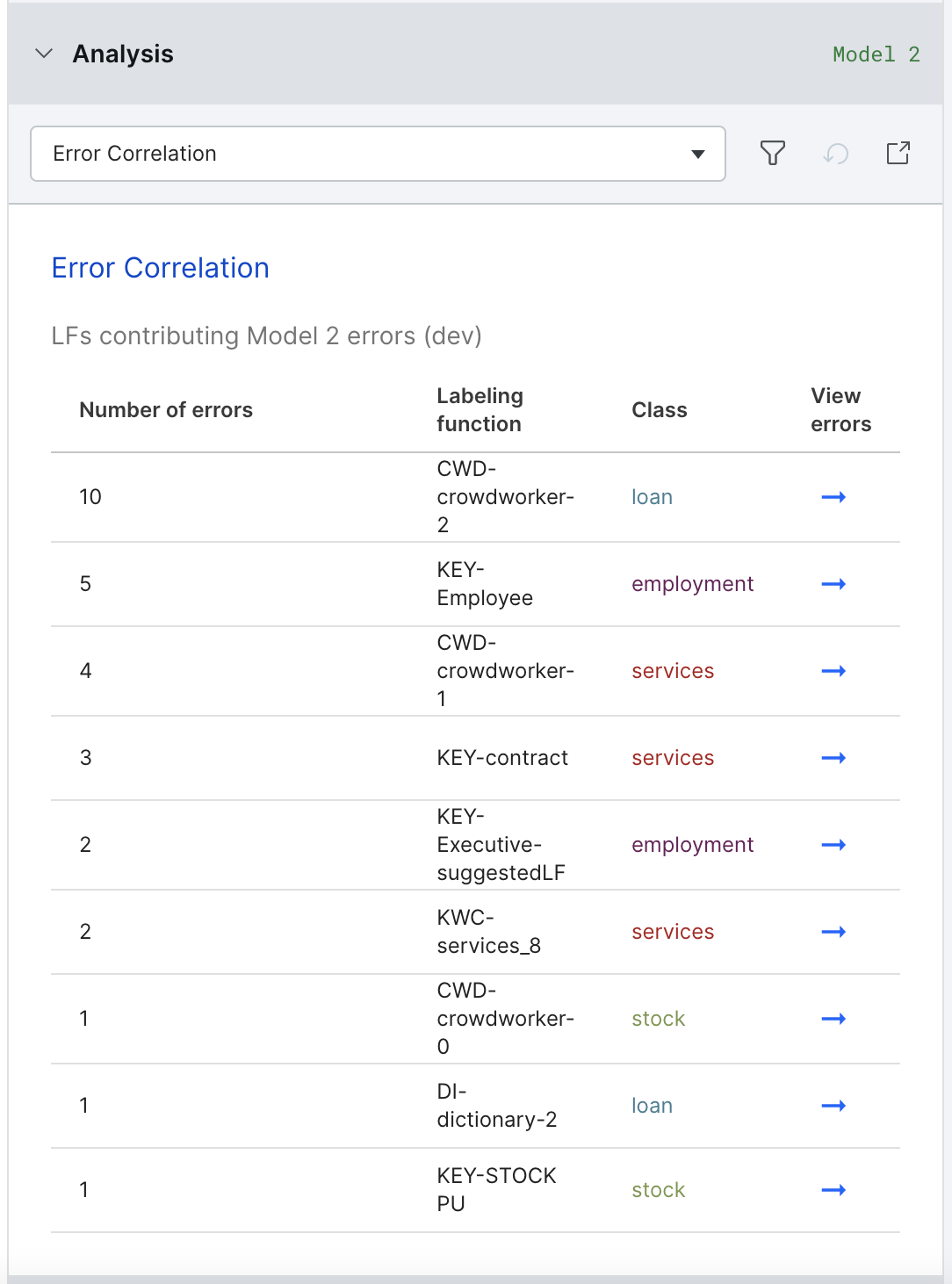
The Error Correlations view traces the model errors back to labeling functions most correlated with these errors. If an LF is correlated with a large number of errors, you may want to refine or delete it.
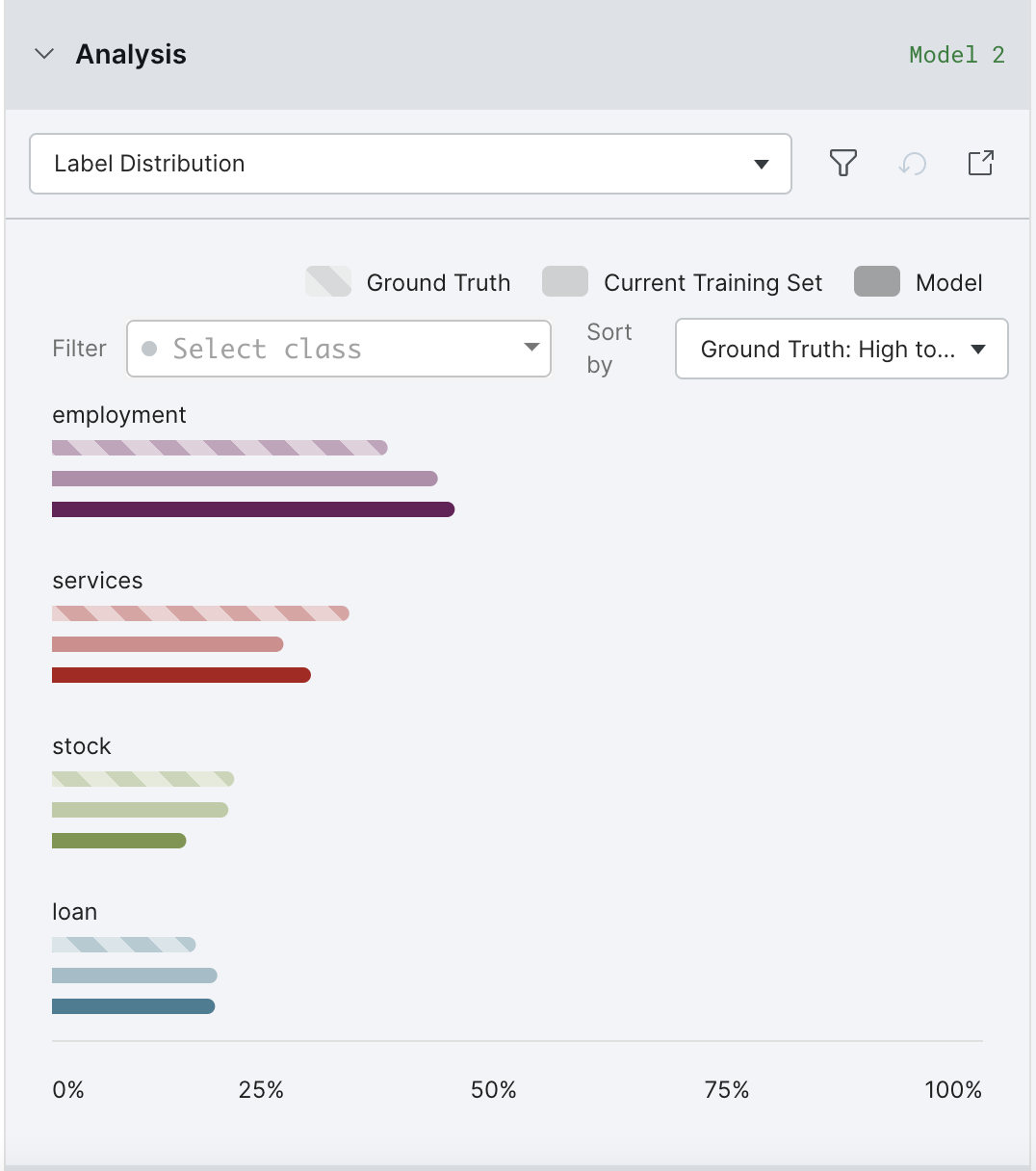
The Label Distributions view shows the relationship between the empirically-measured class distribution, and that of your labeling functions and model. If there are significant discrepancies, you may want to write more / fewer labeling functions for that class, and/or select Oversample data to match class distribution on valid split under the Tune hyperparameter options on the Models page.
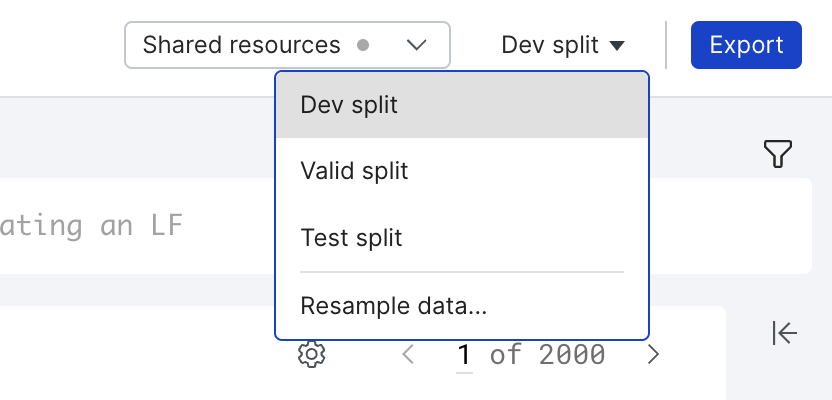
The longer you iterate, the more likely your LFs are to be tuned to the particular data points that you’ve labeled in your dev set (i.e., overfitting). For this reason, it’s a good practice to periodically refresh your dev set by resampling your dev set from the train split using the resample option on the split selector. Note that since these data points will have already been seen by the model, we suggest training a new model to maximize the usefulness of the analysis tools.
To resample your data, click Resample data... from the split selector dropdown.
For more information about resampling data, see Application data control pane.
Tips and tools
Quantity over quality
Labeling functions do not need to be perfect- though having better labeling functions will in general improve the performance of your model, as will having more, and more diverse, labeling functions.
Labeling functions will in general be noisy and incomplete in their coverage. Snorkel Flow will denoise these labeling functions as well as handle conflicts and overlaps among them, and then train a final machine learning model to generalize to data points your labeling functions do not cover. Read about our "Label Model" for more information on this topic.
You can click on the "View LF Coverage" button to see the coverage by each class.
Remove poorly performing labeling functions
While labeling functions that perform better than average can improve your end results, labeling functions that perform below average can add noise to your model and harm its performance. One way to handle this is to use the estimated accuracies in Label as a rough guide for very badly performing labeling functions, and try to remove or improve them, e.g. by adding boolean conditions to narrow them and make them more precise.
Improving existing Labeling Functions
After you’ve defined some labeling functions, you can improve their performance even further by using the below strategies:
-
Inject domain expertise directly
- Goal: Increase training set coverage with less overfitting risk (not looking at specific examples for LF ideation)
- Strategy: Reference external resources (e.g. 3+ digit SIC code categories from https://siccode.com/) to write keyword/regex labeling functions
-
Leverage “Trusted Labeling Functions” for label correction
- Goal: “Correct” noisy labeling functions (functions with low precision, and perhaps high coverage)
- Strategy: Write targeted labeling functions to override noisy labels, and select “Trust this labeling function” in the UI
-
Pass-thru servable labeling functions as modeling features
-
Goal: Augment modeling signal with high quality labeling functions
-
Strategy: Selectively pass LF outputs that are:
- Servable: Available at inference time
- High Precision: To avoid model overfitting
-
How: When defining model training configuration settings, in “Train New Model” pane, under “Feature Libraries”, click “True”, before clicking “Train Model” button.
-
-
Detect overfitting using estimated accuracies
- Goal: Mitigate overfitting in settings without a validation split
- Strategy: Remove or prune labeling functions with a large gap between Snorkel-estimated train and dev accuracy
Check on overall coverage by changing the summary statistics
On the upper left corner of the screen, you can see the performance of the current set of labeling functions on the selected split as well as dataset statistics.
