Deploying Snorkel-built models
This page walks through how to deploy a Snorkel-built application, export said deployment, and stand it up in an external production environment for inference and scoring.
Requirements
| Supported operating systems |
- Ubuntu 20.04+
- CentOS 7+
- RHEL 7+
| Supported hardware |
- CPU: amd64 (x86_64)
- GPU: Nvidia Turing GPU or later generation supported by CUDA 11.8
| | Required software |
- Docker
- Python 3.8
- pyenv/virtualenv (or Conda)
- MLflow 2.5.0+
| | Recommended minimum deployment environment specifications |
- MLflow 2.5.0+
- 16 GB RAM
- 100 GB disk space
|
Prepping and deploying a Snorkel Flow application with MLflow
Before deploying your application, ensure that each node in the DAG view is committed. Committed nodes are purple. Once all nodes are committed, the Deploy application button becomes available in the upper right hand side of the screen. A versioned application graph is bundled up and subsequently referred to as a Deployment.
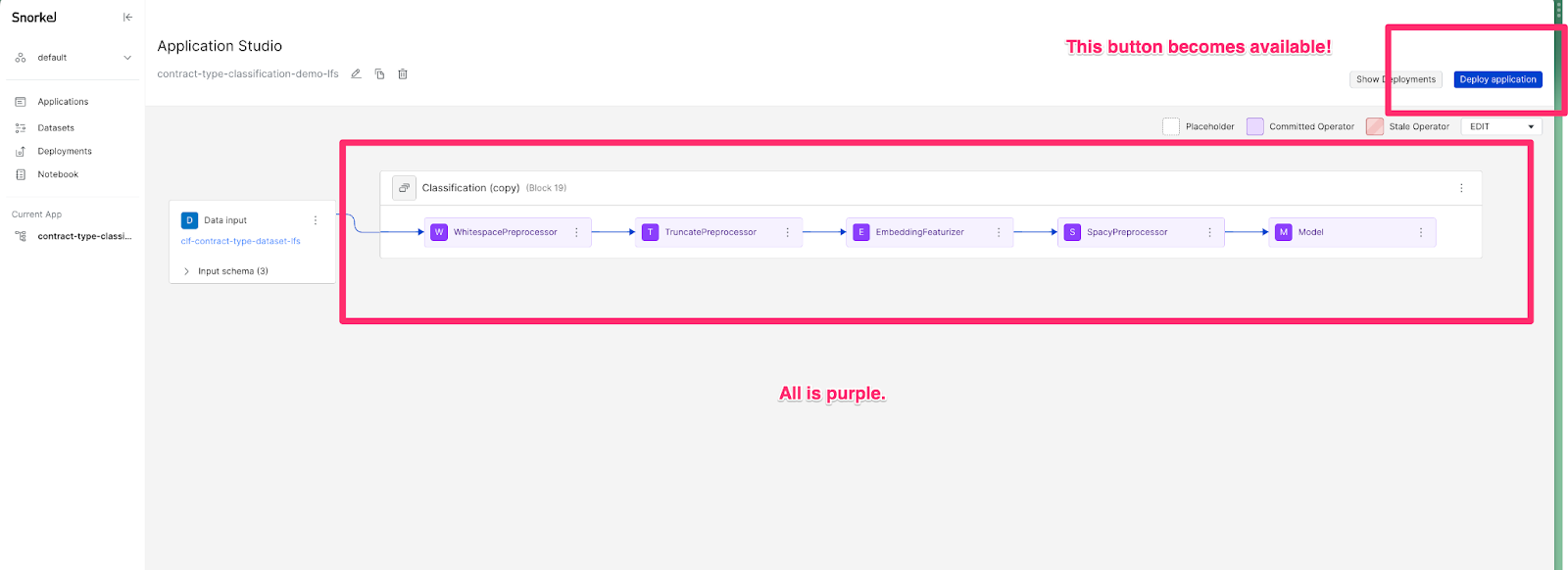
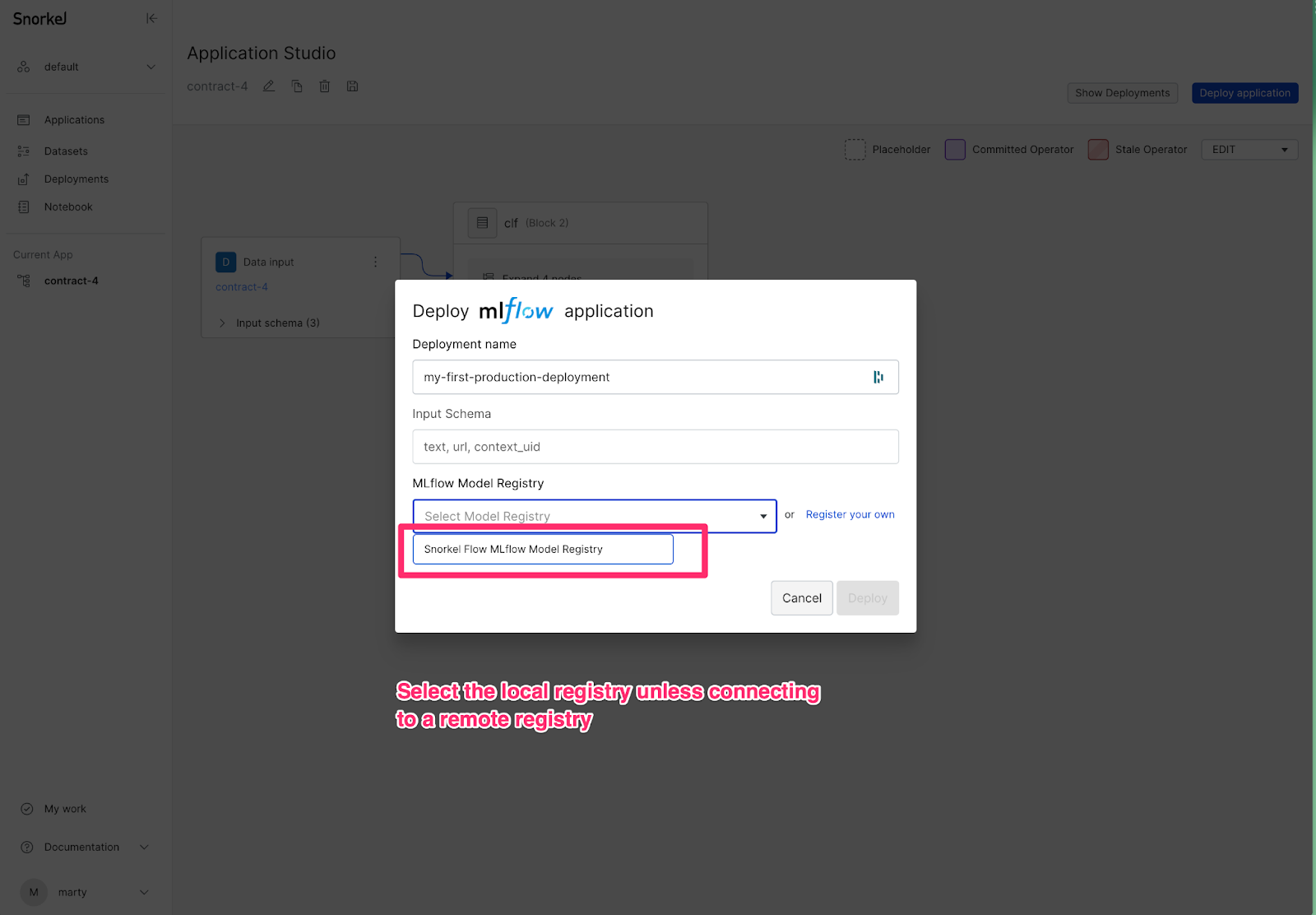
Each deployment requires a unique name and input schema. The input schema is originally generated at dataset creation, but can be updated using the SDK.
context_uid is always included in the input schema, but is strictly an optional field.
Snorkel does not support long-running application deployments in the platform. Instead, Snorkel Flow bundles deployment artifacts into an MLflow package, the open source standard for model hosting. MLflow is supported by all major cloud providers and most major model serving vendors.
By default, you can deploy applications using Snorkel Flow's MLflow Model Registry. However, you can also register connections with remote MLflow registries by clicking Register your own as shown below.
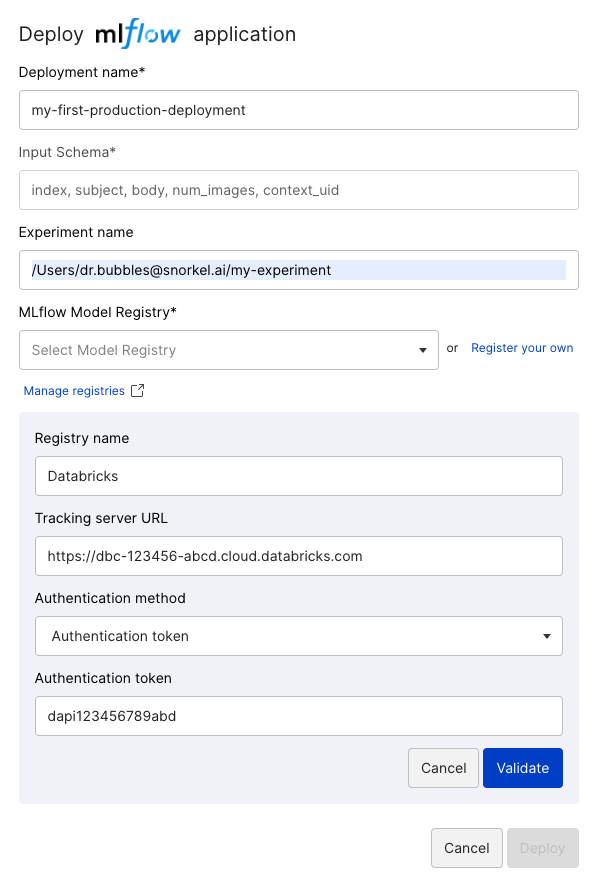
For the Databricks Model Registry (including Azure Databricks), specify the Experiment name in the format /Users/<username>/<experiment_name>, where <username> is your Databricks username. See Model serving with Databricks for how to serve the registered model on Databricks.
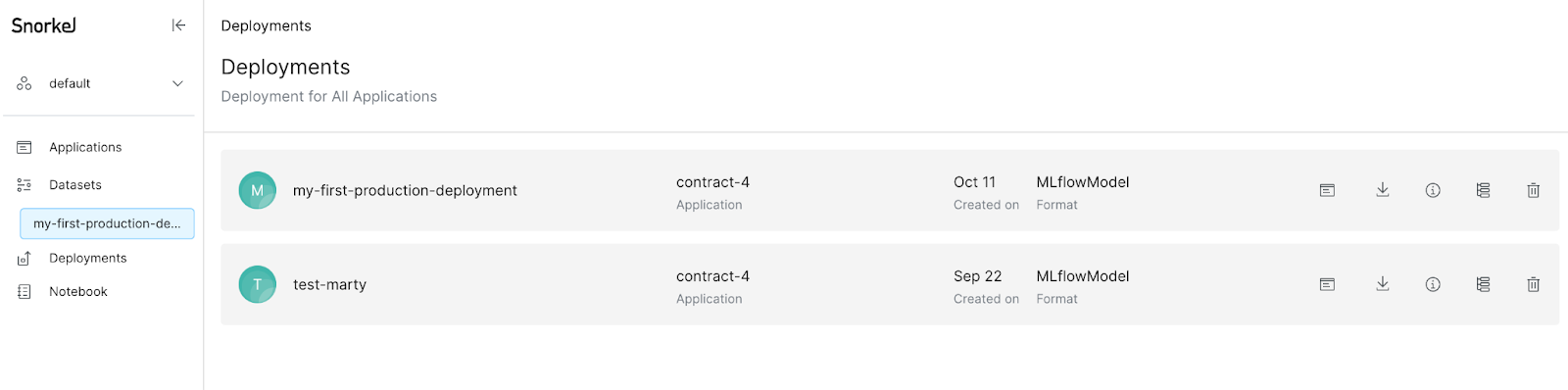
Once a workflow is deployed, you can click the Deployments option in the left-side menu to see your deployments.
Crawl: Testing deployments in Snorkel Flow’s scoring sandbox
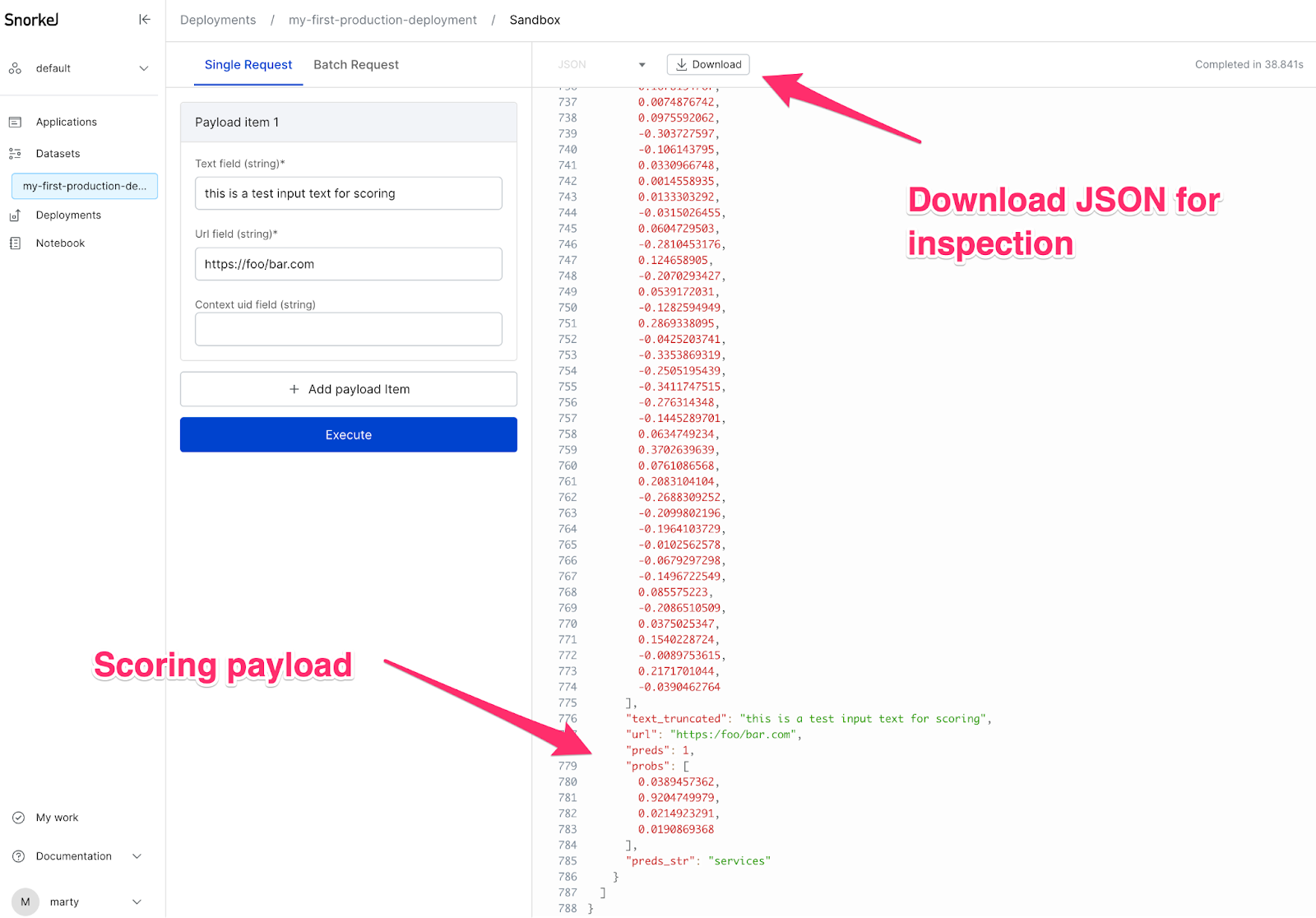
Each deployment in Snorkel Flow ships with a minimal sandbox environment that is intended for testing inference on a small number of records (< 5). To access the sandbox environment for a given deployment, click the inline associated icon  .
.
Before exporting the deployment out of Snorkel Flow, we strongly recommend using the Scoring Sandbox to ensure that a test record can be properly sent through the pipeline. This allows you to clearly understand the input fields and types that are required to generate predictions.
Configuring and right-sizing a production deployment environment
Before exporting the deployment, it is important to consider the following questions. Discuss these questions with your Snorkel account team to determine the infrastructure that is required to host the deployment:
- Does the deployment contain any expensive operators? Examples include calculating document-level embeddings, or an expensive end model or model ensemble. This will affect resource allocation and inference latency.
- How often will inference be run? What is the interval of a single time window? Yearly/quarterly/monthly/weekly/daily/multiple times per day?
- How many records will be sent for scoring per time window?
- What are the CPU and RAM resources that are available for inference? Snorkel recommends 4 CPU / 16 GB RAM minimum, but this can vary depending on the construction of the application graph (DAG).
- Will additional business logic need to be performed post-scoring? For example, will predictions only be considered if model confidence is greater than 85%? Will extracted fields need to be combined before a database insert? Post-processing and business logic can be handled in the DAG or outside of the Snorkel deployment object.
- Does the business have inference throughput or latency requirements? This will affect resource allocation.
The following table has our recommendations for T-shirt sizing a deployment. Snorkel cannot guarantee performance or uptime SLA’s surrounding deployments. Work with your Snorkel account team to right-size CPU/RAM allocations, given your business requirements.
| T-Shirt Size | Model size | Frequency and Volume | Minimum Resourcing Recommendation |
|---|---|---|---|
| Small | Small | Batch inference < 10k records yearly or quarterly | 4 CPU / 16 GB RAM |
| Medium | Small | Batch inference >10k records monthly | 4 CPU / 16 GB RAM |
| Large | Medium/Large | Batch inference > 10k records daily, live inference | 12 CPU/ 48 GB RAM |
| XL | Any | Batch inference > 1M records daily, live inference | 24 CPU / 96 GB RAM |
Walk: Testing a deployment in an external environment (local python)
To download your deployment to test locally, click the Deployments option in the left-side menu, then click the Download deployment package  button. This will download the code and libraries that are required to run the exported deployment as a zip file to your local machine. An exported deployment can also be downloaded using the SDK. Once unzipped, the export will look something like the following:
button. This will download the code and libraries that are required to run the exported deployment as a zip file to your local machine. An exported deployment can also be downloaded using the SDK. Once unzipped, the export will look something like the following:
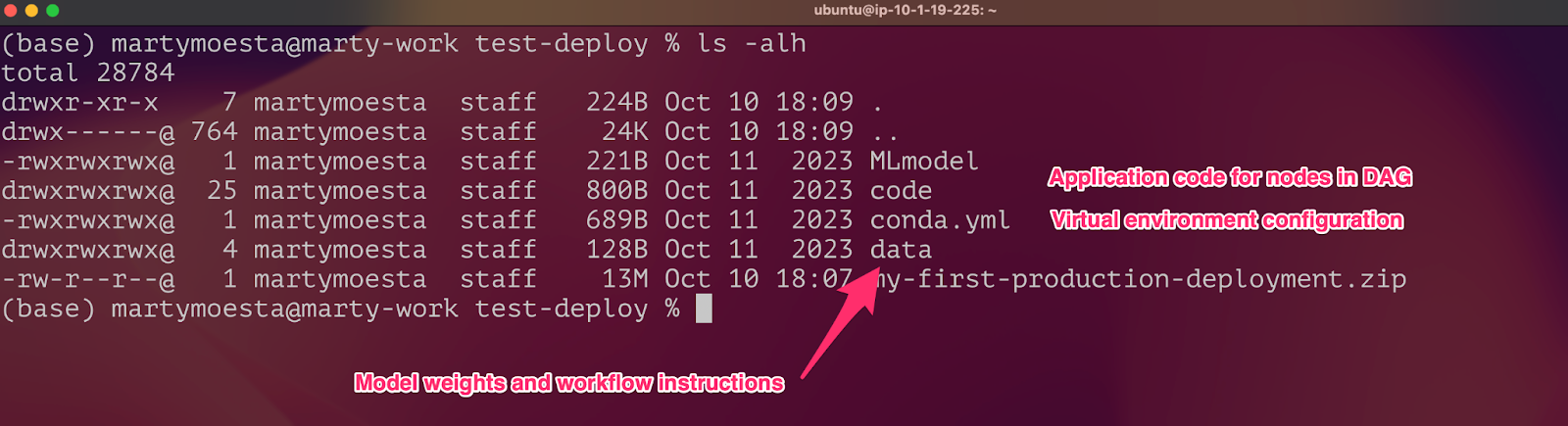
For a full explanation of the contents of the export, see the MLflow models documentation.
We recommend hosting deployments through containerized application images, either with docker or kubernetes. However, before generating an image and standing up a container, we recommend that you first test inference in a local python execution environment.
Unzip the contents of the downloaded package. The following command will unzip the downloaded package into a directory called mlflow_deployment:
$ unzip -d mlflow_deployment <<insert_downloaded_deployment>>.zip
Next, gather example scoring data. MLflow accepts json exports of Pandas DataFrames, oriented in the split format. Convert a DataFrame to valid json using the following code snippet:
import pandas as pd
import json
df = pd.DataFrame("<<insert your data here>>")
with open("scoring_example.json", "w") as f:
json.dump({"dataframe_split": df.to_dict(orient='split')}, f)
Now you can use the mlflow models predict command to score example records:
$ mlflow models predict -m mlflow_deployment -i scoring_example.json
####output
[{"text": "the quick brown fox jumped over the lazy log",
"url": "https://snorkel.ai", "preds": 2,
"probs": [0.0003, 0.0003, 0.998, 0.0004], "preds_str": "stock"}]
If your machine is equipped with GPU and want to take advantage of it, pass IS_GPU_ENABLED=1 as an environment variable:
$ IS_GPU_ENABLED=1 mlflow models predict -m mlflow_deployment -i scoring_example.json
Run: Generating a container-based deployment (Docker, Kubernetes, or Google Cloud Run)
We recommend using container-based approaches for hosting production inference workloads. Containers enable OS-agnostic workloads to run anywhere with variable resource allocations that can be easily spun up and down on-demand.
Before standing up a container hosting the deployment, an application image must first be generated. Snorkel supports Docker for management of application images and supports the MLflow Command-Line Interface (CLI) for generating the application image. To generate an application image:
- Open a terminal.
- Login to either Docker locally or Dockerhub through the docker login command.
- Navigate to the unzipped deployment directory using the command line. Execute the following command:
$ mlflow models build-docker -m **{path to unzipped deployment directory}** -n my-image-name
The build-docker command will convert the deployment export into an application image. See build-docker for more information. After the command completes, validate the creation of an application image through the docker images command.
Use the generate-dockerfile command in MLFlow 2.5.0+ to generate a Dockerfile and artifacts that can be customized further before building the application image.
Deploying the image and testing the container
Use the following command to run the recently-created image as a container using Docker:
$ docker run -p 5001:8080 my-image-name
To run a model on GPUs,
$ export IS_GPU_ENABLED=1
$ docker run --gpus all -e IS_GPU_ENABLED -p 5001:8080 my-image-name
This command will expose a REST API on all interfaces on port 5001. Validate this with the docker ps command. The /invocations API is used to score records (see Deploy MLflow models for more information). Open a separate terminal window and test record scoring with a simple curl command:
$ curl [http://127.0.0.1:5001/invocations ](http://127.0.0.1:5001/invocations)
-H 'Content-Type: application/json' \
-d @/path/to/example_scoring.json -v
In this example, example_scoring.json is a Pandas DataFrame with column input_schema that was converted to a json object using the orient = “split” parameter in the Pandas to_json() function.
Deploying to Google Cloud Run
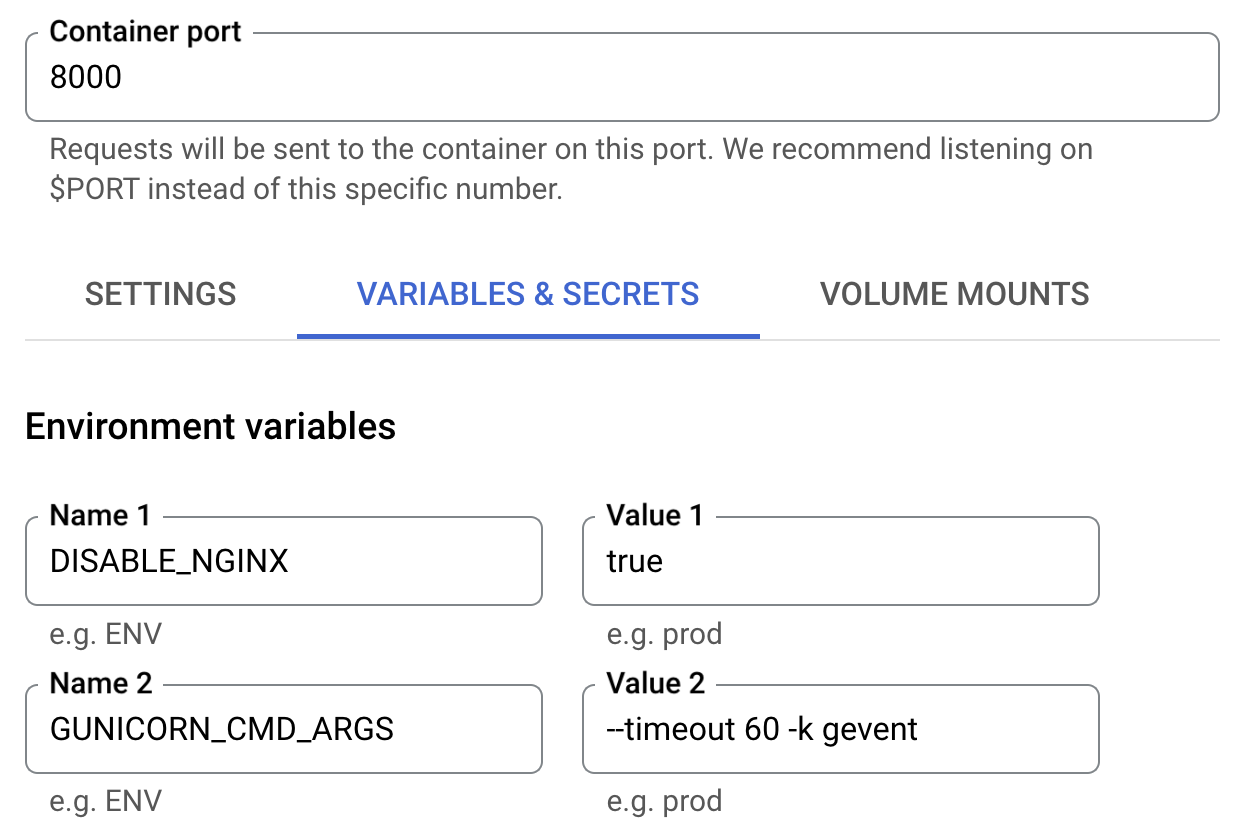
The Docker image that is built in the above section can be pushed to Artifact Registry (or Container Registry) in Google Cloud and can be deployed to Cloud Run. To do this, change the following configurations in Cloud Run.
- Set the Container port to 8000.
- Add the following environ variables:
DISABLE_NGINX=trueGUNICORN_CMD_ARGS="--timeout 60 -k gevent"
- Set the Memory 2GB or higher.
Summary
This walkthrough demonstrated how to deploy a Snorkel-built application, export said deployment, and stand it up in an external production environment. Reach out to your Snorkel account team for assistance when architecting a long-term production deployment using Snorkel-built artifacts or contact support@snorkel.ai for assistance.