Supported data source types
This page provides information about the data source types that Snorkel Flow supports. You can follow the steps outlined in Data preparation and Data upload to prepare and upload your dataset into Snorkel Flow.
Snorkel flow supports the following types of data sources: Cloud storage, local files, SQL, Databricks SQL, Google BigQuery, and Snowflake.
For SQL, Snowflake, Google BigQuery, and Databricks SQL, your credentials are encrypted, stored, and managed by Snorkel Flow. Credentials are not logged or stored unencrypted.
Cloud storage
Select Cloud Storage to add data sources from Snorkel Flow’s MinIO object storage or cloud services like AWS S3.
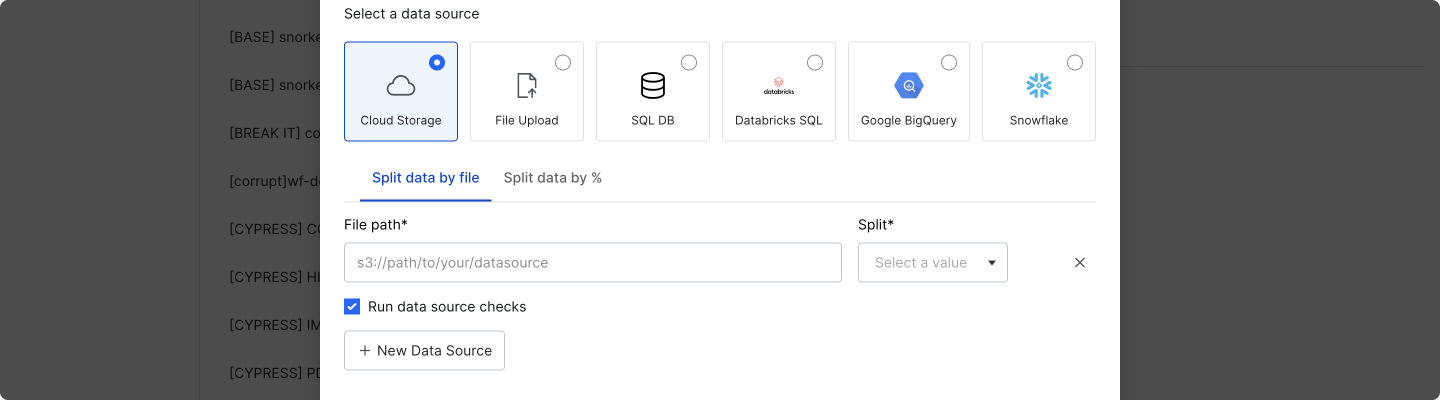
For the File path field, use:
minio://paths (e.g.,minio://mybucket/train.parquet) for files in Snorkel Flow’s MinIO object storage.s3://(e.g.,s3://mybucket/train.parquet) paths for files in AWS S3.
If you are using a cloud service like AWS S3 and your storage bucket is private, your Snorkel Flow instance will need to have access via an instance role. Please reach out to your administrator to configure access to private storage buckets.
Local file
Select File Upload to add data sources from your local machine. You must upload a Parquet or CSV file.
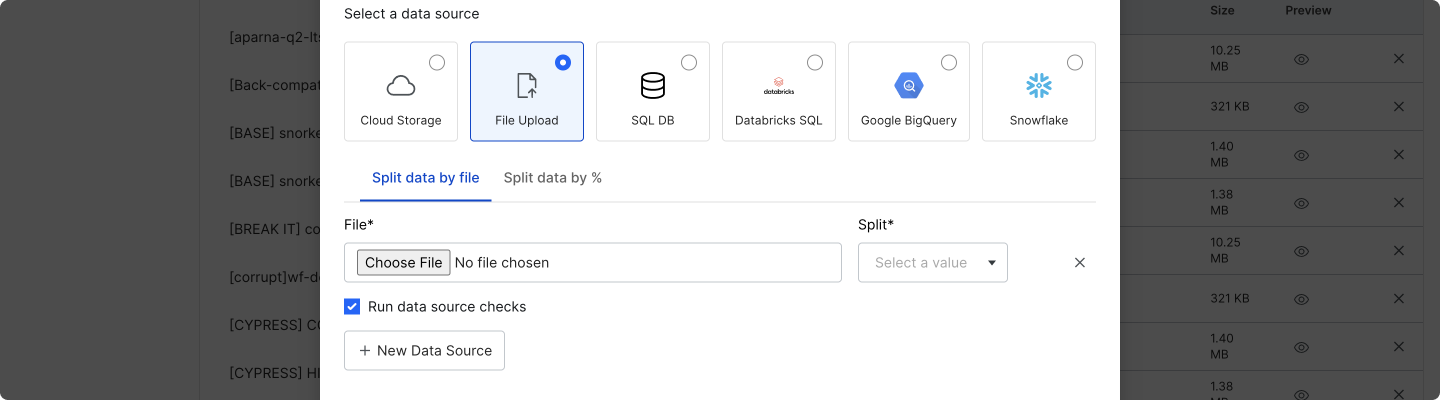
Local data upload currently only supports data source files up to a maximum size of 100MB. If your data files are too large, you should instead use MinIO or a cloud storage service like AWS S3.
SQL
Select SQL DB to add data sources from queries against SQL databases like Postgres and SQLite.
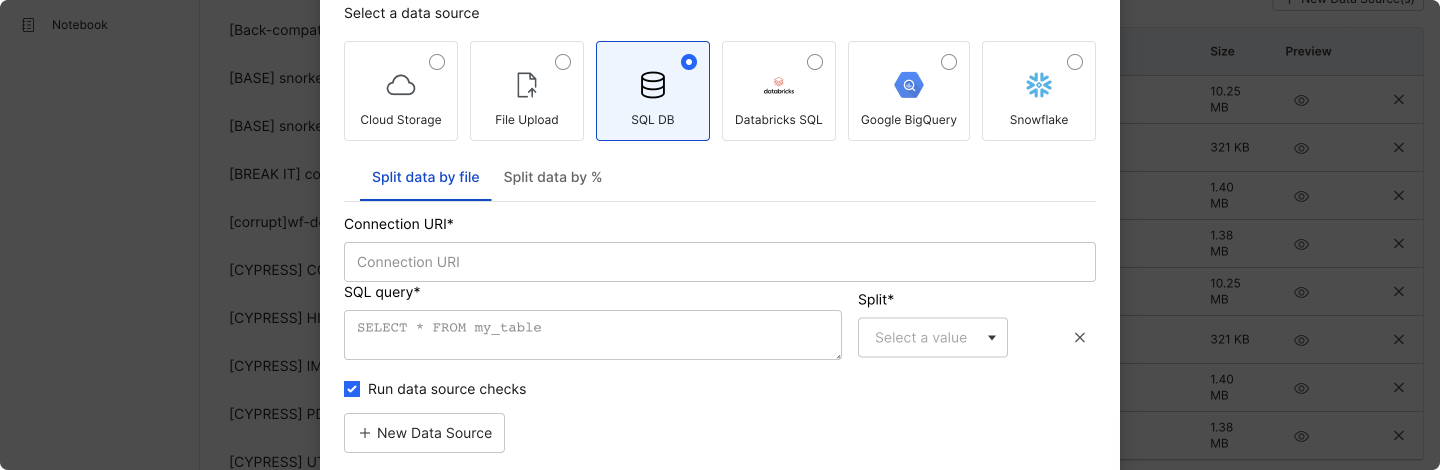
Fill out the required fields:
- Connection URI: A database connection string, for example, those that are used by SQLAlchemy.
- SQL query: A SQL query where each result row is a data point.
Databricks SQL
Select Databricks SQL to add data sources from queries against a Databricks SQL warehouse. Currently, all table columns are read.
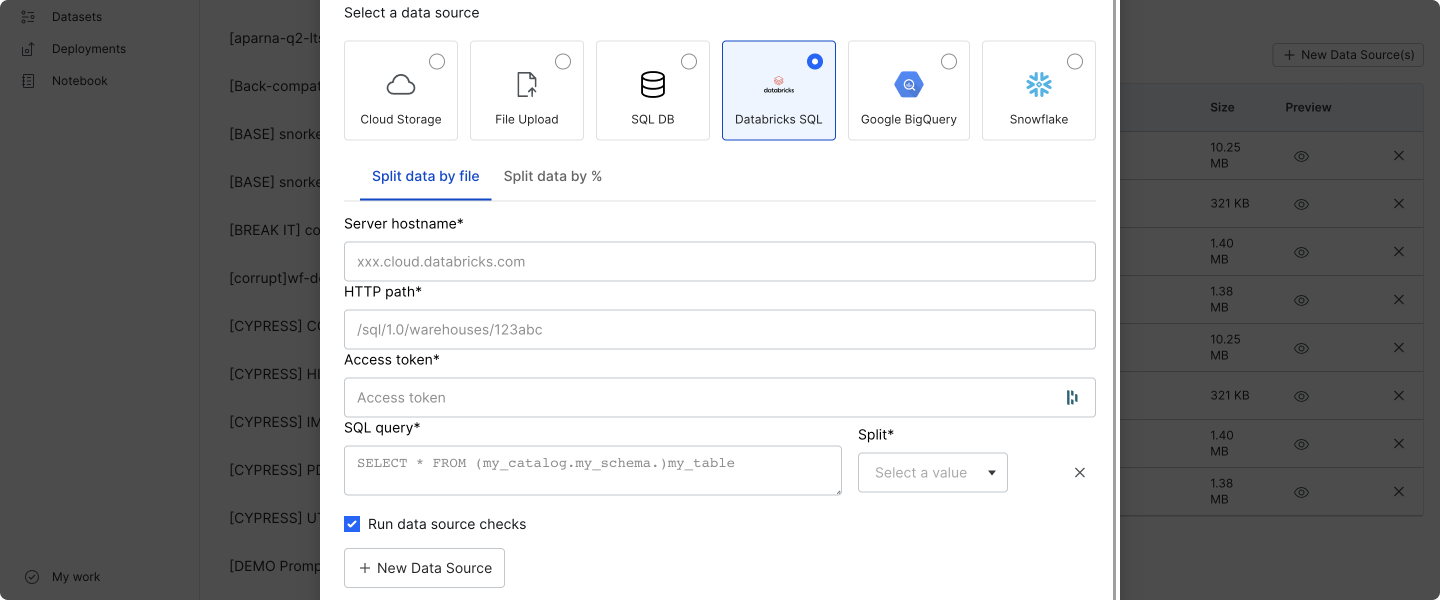
Fill out the required fields:
- Server hostname: The server hostname of your Databricks SQL warehouse.
- HTTP path: The HTTP path of your Databricks SQL warehouse.
- Access token: Your Databricks access token.
- SQL query: A Databricks query where each result row is a data point.
See the Databricks documentation for more details about these items.
Note
Your credentials are encrypted, stored, and managed by Snorkel Flow. Credentials are not logged or stored unencrypted.
Google BigQuery
Select Google BigQuery to add data sources from Google BigQuery tables. Currently, all table columns are read.
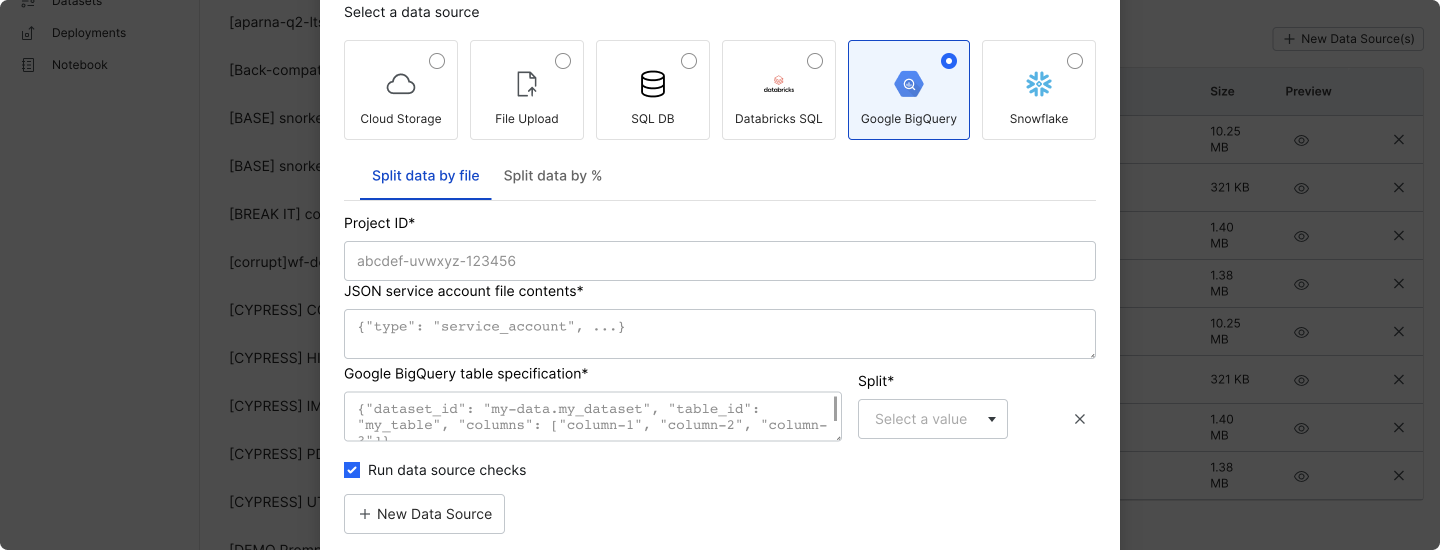
Fill out the required fields:
-
Project ID: Your Google Cloud project ID.
-
JSON service account file contents: The raw JSON contents of a key file that belongs to a service account with access to Google BigQuery. Please note that the service account requires
roles/bigquery.readSessionUserandroles/bigquery.dataViewerto read a table. -
Google BigQuery table specification: A JSON specification for the table columns to read, where each result row is a data point. The specification must have the following keys, and an example is provided below.
dataset_id: The BigQuery dataset ID.table_id: The BigQuery table ID.columns: The list of columns to include.
{
"dataset_id": "bigquery-public-data.noaa_tsunami",
"table_id": "historical_source_event",
"columns": ["id", "year", "location_name"]
}
Snowflake
Select Snowflake to add data sources from queries against a Snowflake data warehouse.
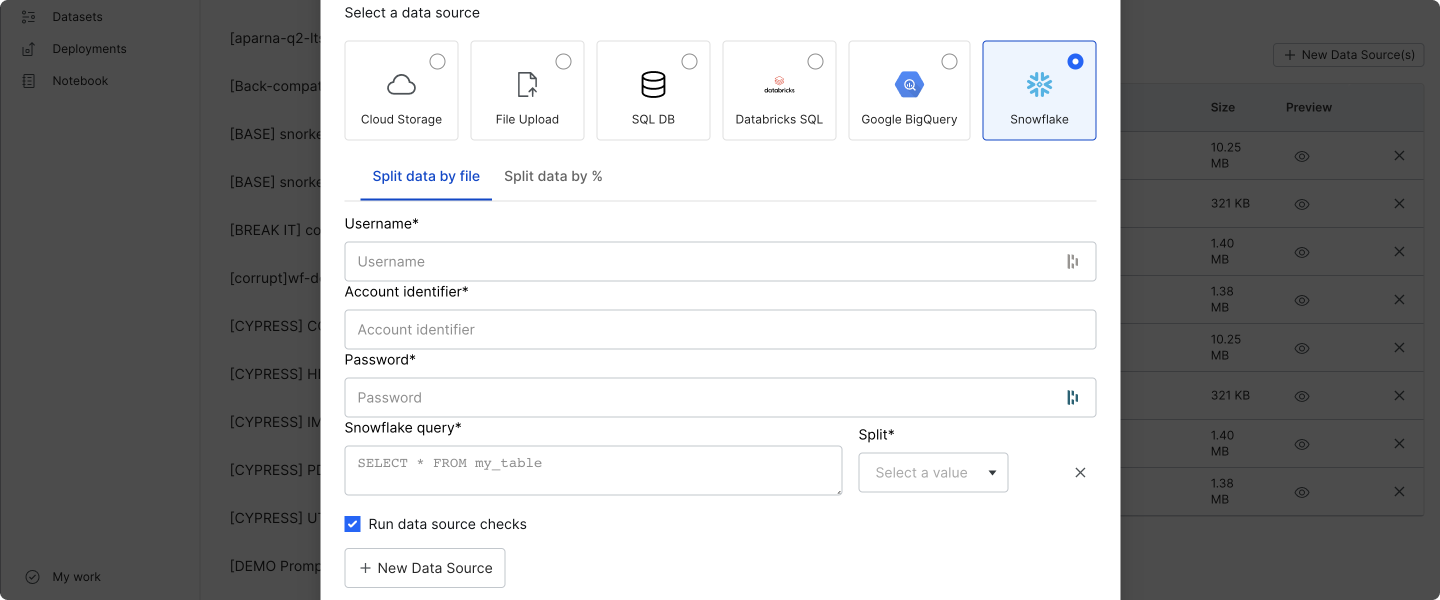
Fill out the required fields:
- Username: Your Snowflake username.
- Account identifier: Your Snowflake account identifier.
- Password: Your Snowflake password.
- Snowflake query: A Snowflake query where each result row is a data point. Queries can specify the database, schema, and table, as in the example below.
SELECT c_name, c_address
FROM snowflake_sample_data.tpch_sf1.customer
LIMIT 10;
The default warehouse that is specified for your Snowflake account will be used.