View and analyze model results
This page walks through the model results and metrics that are available in the Models pane. The Analysis pane provides additional charts, metrics, and guidance on how to refine your models. See Analysis: Rinse and repeat for more information.
Once you’ve trained a model, if you have ground truth, the Best Accuracy and Latest Accuracy are displayed in the top left corner of your application. If you don't have ground truth, then the values display--. This allows for an easy comparison between the current model's performance and the best-performing model among all iterations. You can use the drop downs to change the metrics that are shown.
Models pane
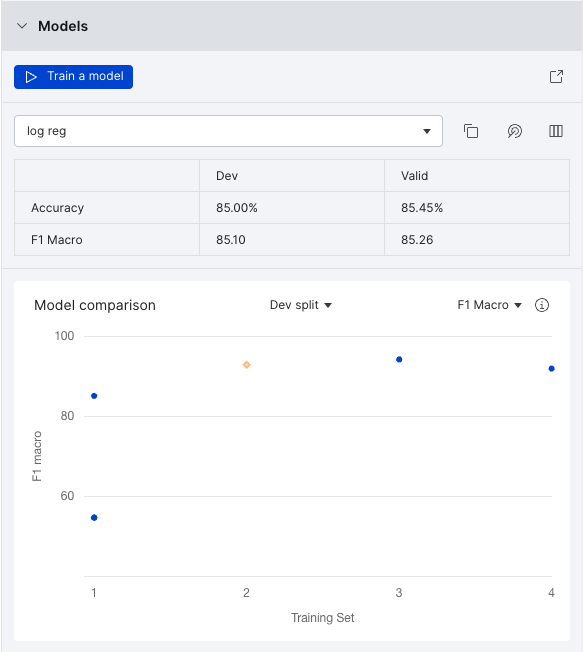
By default, the Accuracy and F1 Macro for your dev and valid splits for the most recent model are shown in the table. You can change these metrics in the Advanced options of the Models modal.
By default, the Model comparison chart shows the F1 macro of the dev split for all models. This provides a good visual comparison of how well your models are performing and whether new iterations are improving model performance. You can use the drop downs to change which split and which metric is shown in the graph.
The Models pane offers additional options:
- For more information about your model, click the
 icon in the Models pane to bring up the Models modal.
icon in the Models pane to bring up the Models modal. - If you have already trained a model, and want to make minor adjustments to it without recreating the model from scratch, select the model from the dropdown, and then click the
 icon. This will bring up the Train a model modal and automatically populate the model options based on the model selected.
icon. This will bring up the Train a model modal and automatically populate the model options based on the model selected. - To restore the labeling functions (LFs) that were active when when the model with the best performance was trained, click the
 icon. This will overwrite the current set of active LFs.
icon. This will overwrite the current set of active LFs. - To view model metrics for the test set, click the
 icon. This is hidden by default to avoid looking at test set scores while hyperparameter tuning and training different models. We recommend having another held out test set outside Snorkel Flow for evaluating final performance as well.
icon. This is hidden by default to avoid looking at test set scores while hyperparameter tuning and training different models. We recommend having another held out test set outside Snorkel Flow for evaluating final performance as well.
Models modal
For more information about your model, click the icon in the Models pane to bring up the Models modal. Here, you can view and customize metrics for all models that have been trained.
The following options are available when you open the Models modal. To view more options, click the  icon or click Advanced options.
icon or click Advanced options.
- Show Test: View the model metrics for the test set. This is hidden by default to avoid looking at test set scores while hyperparameter tuning and training different models. Select Hide Test to remove the test set metrics from the table.
- Commit: Once you are finished iterating and developing models, click Commit to save the model into the application pipeline. Committing a model is required for it to be used in deployment. In addition, you need to commit a model to be able use as input to downstream nodes (e.g., in a hierarchical child block).
- Hover over the
 icon view the config of the search space for which the best performing model was returned. Click the icon to copy the config to the clipboard.
icon view the config of the search space for which the best performing model was returned. Click the icon to copy the config to the clipboard.
More options
Click the icon to view more options:
- View search space config: View the config of the search space for which the best performing model was returned.
- Copy config: In the Search space config modal, select this to copy the config to the clipboard.
- Edit model name/description: Edit the model name and description.
- Export as CSV: Download the predictions from the model for all splits as a CSV file.
- Delete this model: Delete the selected model. It will ask you to confirm before proceeding with deletion.
Advanced options
Click Advanced options in the top right corner of the modal to expose the advanced options bar.
-
Sort by: Choose any metric on the valid set in the dropdown to sort the models. If there are ties, then the order is determined first by F1, and then by accuracy scores.
-
Tags Filter: Use the dropdown to view model metrics on subsets of the data based on tags that you have created. Note that Untagged Data refers to all data points that do not have an error analysis tag applied to them.
-
Postprocessors: When turned on, this applies all post processors for the model node before calculating model metrics. This is turned on by default.
-
Model Metrics: Selecting metrics from the Metric types option changes the metrics that are displayed in the tables in the modal as well as in the Models pane. Selecting a metric from the Primary metric option changes the metric that is optimized for during hyperparameter search and threshold setting.
- You can also register custom metrics in the Python SDK using
snorkelflow.client.metrics.register_custom_metric.
- You can also register custom metrics in the Python SDK using
-
Enable model metrics cache: Check the box to enable caching for your model metrics.
[Extraction] document-level operators and metrics
For information extraction applications, we often have different levels at which we’d like to evaluate final model performance:
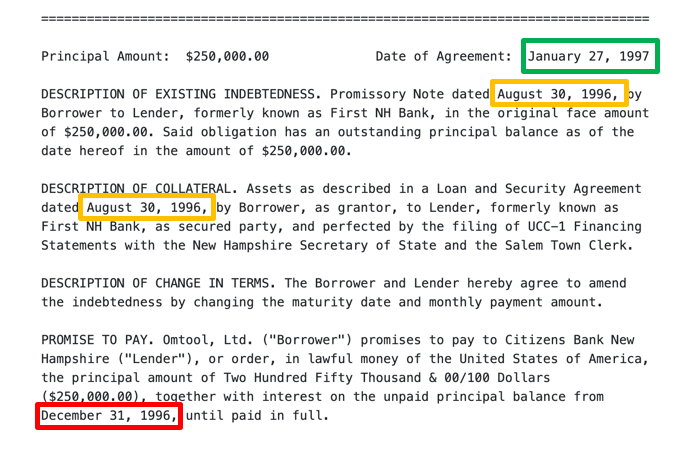
- Span level: The number of candidate spans that were classified correctly. For example, in the Information extraction: Extracting execution dates from contracts tutorial, this would be how many dates we correctly marked as either POSITIVE (an execution date) or NEGATIVE (not an execution date).
- Document level: This measures Snorkel's performance at extracting one (or several) values from the overall document. For example, the execution date of the document.
In many settings, such as the Information extraction: Extracting execution dates from contracts tutorial, we care less about classifying all dates correctly (the span level score), and instead want to find the single execution date of the document with high accuracy (the document level score).
While labeling function and model development leverage span-level candidates in Snorkel Flow, many downstream applications often rely more heavily on document-level extractions. As a result, Snorkel Flow provides a number of operators to convert raw, span-level classifications into document-level extractions. See Post processors in extraction blocks for information on how to set this up for your application.
Document level metrics
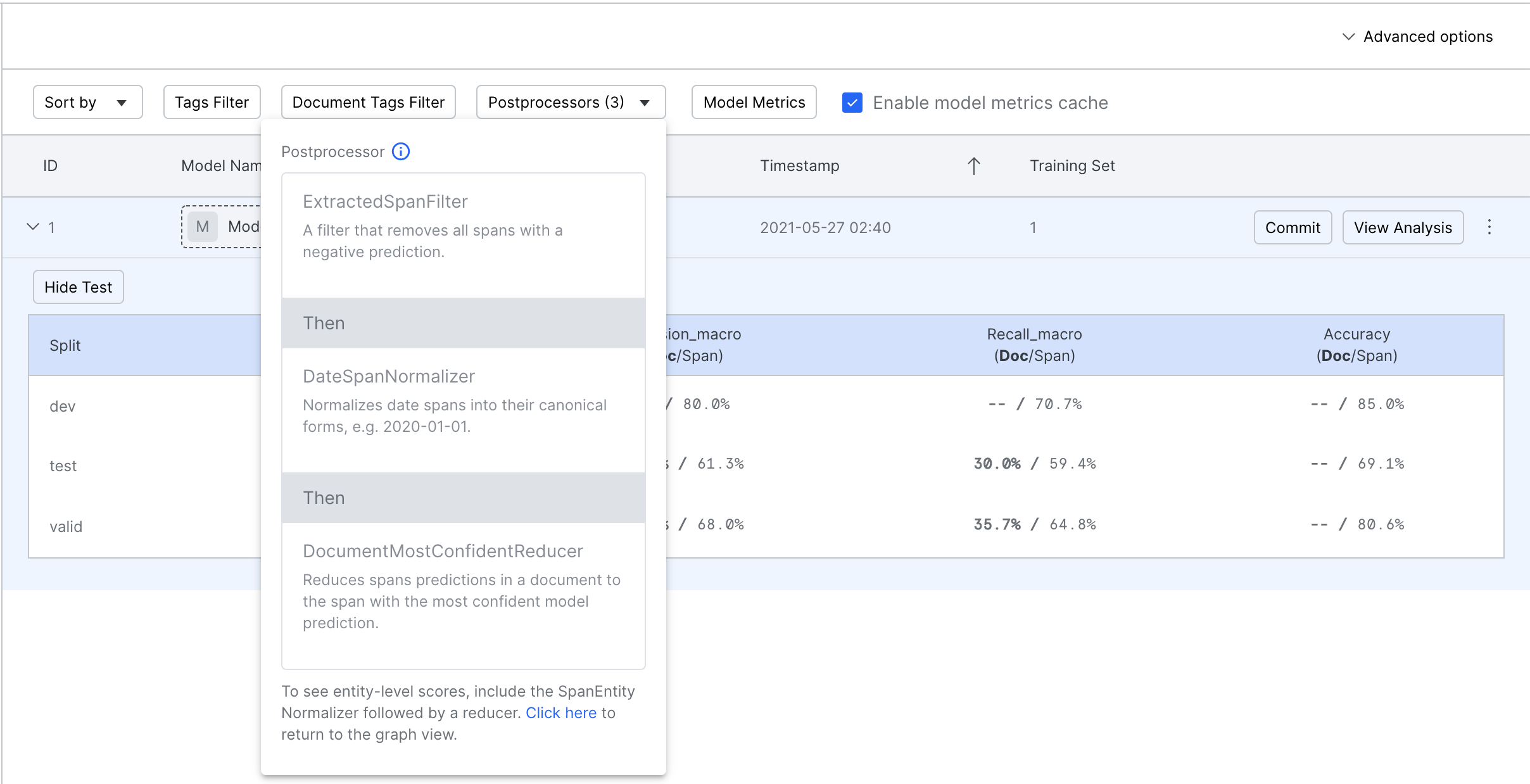
By using some combination of normalizers and reducers, you can convert span-level predictions and ground truth into document-level extractions. These are then used to compute document-level accuracy and F1.
These options are available under Advanced options. The Models table will display document-level scores (Doc) besides span-level scores (Span).
[Entity classification] entity-level operators and metrics
Similar to the extraction setting, Snorkel Flow supports operators and metrics at a higher-level than spans:
- Span-level: The number of candidate spans that were classified correctly.
- Entity-level: This measures Snorkel's performance of extracting one (or several) values for each document and entity. For example, the mention of a company entity for a particular news article.
Similar to document-level post processors and metrics, Snorkel Flow supports entity-level varieties that produce (document, entity) pairs. More information about entity-level operators can be found in Post processors in extraction blocks.
Entity level metrics
After applying an entity-level reducer, you can convert span-level predictions and ground truth into entity-level extractions. These extractions are then used to compute document-level accuracy and F1 macro.