Warm start
Warm start is the Snorkel Flow tool for getting your first training labels using state of the art foundation model (FM) based techniques. It's designed to give you a high-coverage labeling function (LF) where the foundation model is forced to give its best guess on every datapoint. This starting point can then be improved upon by the addition of other Snorkel Flow labeling functions.
FM warm start supports the following application types: Classification (both single and multi-label, not PDF) and Sequence Tagging.
Warm start is not accessible within studio on a CPU-based deployment of Snorkel Flow. To use warm start without a GPU, you must use the SDK. See Utilizing external models and Warm start SDK for more information.
Running warm start
To access warm start in the UI, head to the Labeling Functions accordion inside your application. Then under Suggested, click the Warm Start LFs icon shown below.
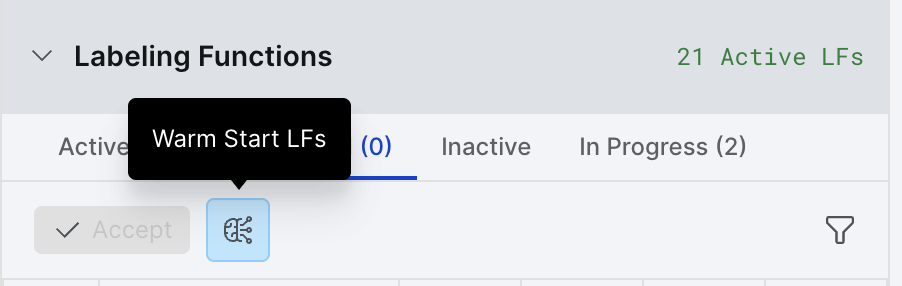
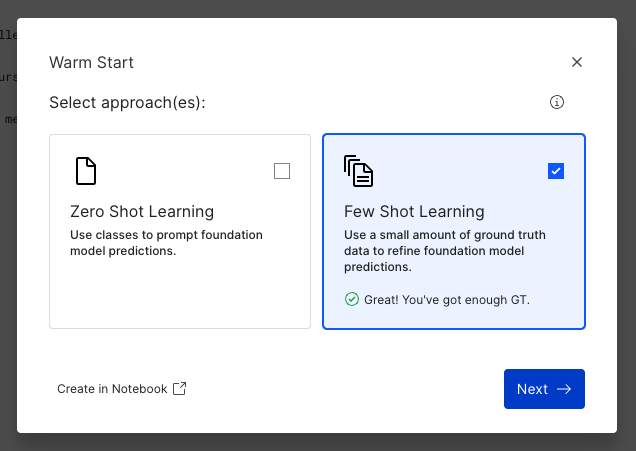
This will launch the modal, where you select either zero-shot or few-shot learning. These techniques are described in the next section.
Follow the steps and at the final stage click Create LFs. This will kick off a long-running process to label your data using a foundation model. You can then monitor the progress in the Labeling Functions tab, under In Progress. If the LF is not showing, try clicking the refresh button.
Warm LF types
There are two types of LFs that can be created from the warm start wizard: zero-shot learning and few-shot learning.
Zero-shot learning describes the process of using only problem metadata, such as class names and descriptions, to make a prediction of the label for each datapoint.
Few-shot learning describes the process of additionally using a few (in the order of 10) labeled examples per class to make a better prediction of the label for each datapoint.
Zero-shot LFs
Zero-shot labeling functions don’t require any labeled training data and instead utilize the label names to make an initial vote on each datapoint. These LFs will likely be less accurate than few-shot LFs, but may generalize better to unseen distributions of data. In order for them to work well they require sensible label names. For example, if the task is to categorize news articles, sensible label names could include: [“Sport”, “Science & Technology”, and “Business”].
Few-shot LFs
Few-shot labeling functions leverage existing ground truth labels to fit a model to your task. These tend to be more accurate than zero-shot LFs. Few-shot LFs are currently the recommended approach if you have enough ground truth labels. At least five labels are required per class, but no more than 50 labels per class will be used to ensure that the LFs generalize well.
Model selection
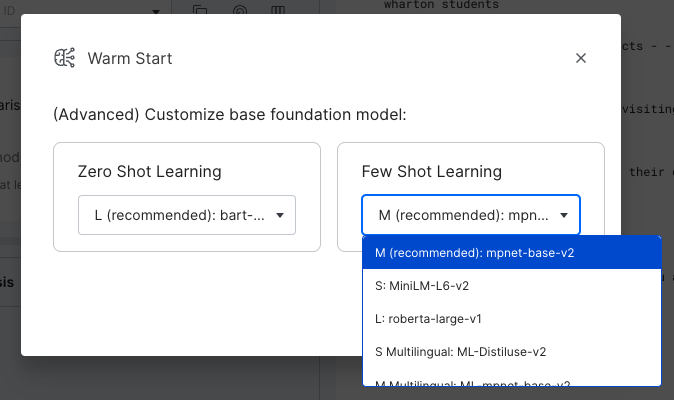
Each method has a set of pre-trained models that you can select from. These models serve as the base for any information that will be distilled into the LFs created. Tradeoffs can be made between different choices:
- Accuracy: larger models tend to be more accurate.
- Speed: larger models will be slower to run.
- Domain: specialized models (e.g., Multilingual) may be more appropriate for your problem, and lead to better accuracy than the more general model.
For more advanced configuration, use the Warm start (SDK).
Model selection has a big effect on the wait time for, and accuracy of, the warm start LF. For document classification, below is a handy guide to help you pick.
Zero-shot LF models
Here are the models that are available for zero-shot LFs.
L (recommended): FLAN T5 Large: (google/flan-t5-large):
- A large English model that usually achieves good performance.
- Expect it to complete in 30mins - 2 hours. For especially large datasets with long documents, it can take longer.
M: FLAN T5 Base: (google/flan-t5-base):
- A medium size English model.
- It runs 2x faster than our recommended model.
- It typically achieves a 10% relative drop in warm start F1 score compared to our recommended model.
Few-shot LF models
Here are the models that are available for few-shot LFs.
M (recommended): mpnet-base-v2 (sentence-transformers/paraphrase-mpnet-base-v2):
- A medium size English model with good all-round performance.
- Expect it to complete in 30mins - 2 hours. For especially large datasets with long documents, it can take longer.
S: MiniLM-L6-v2: (sentence-transformers/all-MiniLM-L6-v2):
- A small English model.
- It runs 3x faster than our recommended model.
- It typically achieves a 25% relative drop in warm start F1 score compared to our recommended model.
L: roberta-large-v1: (sentence-transformers/all-roberta-large-v1):
- A large English model.
- It runs 2.5x slower than our recommended model.
- It can achieve an larger warm start F1 score compared to our recommended model.
S Multilingual: ML-Distiluse-v2: (sentence-transformers/distiluse-base-multilingual-cased-v2):
- A small multilingual model.
- It supports 50+ languages: ar, bg, ca, cs, da, de, el, en, es, et, fa, fi, fr, fr-ca, gl, gu, he, hi, hr, hu, hy, id, it, ja, ka, ko, ku, lt, lv, mk, mn, mr, ms, my, nb, nl, pl, pt, pt-br, ro, ru, sk, sl, sq, sr, sv, th, tr, uk, ur, vi, zh-cn, zh-tw.
- It runs 15% slower than our recommended model.
- It typically achieves a 25% relative drop in warm start F1 score on English tasks compared to our recommended model.
M Multilingual: ML-mpnet-base-v2: (sentence-transformers/paraphrase-multilingual-mpnet-base-v2):
- A medium size multilingual model.
- It supports 50+ languages: ar, bg, ca, cs, da, de, el, en, es, et, fa, fi, fr, fr-ca, gl, gu, he, hi, hr, hu, hy, id, it, ja, ka, ko, ku, lt, lv, mk, mn, mr, ms, my, nb, nl, pl, pt, pt-br, ro, ru, sk, sl, sq, sr, sv, th, tr, uk, ur, vi, zh-cn, zh-tw.
- It runs 70% slower than our recommended model.
- It typically achieves a 10% relative drop in warm start F1 score on English tasks compared to our recommended model.
Editing warm start LFs
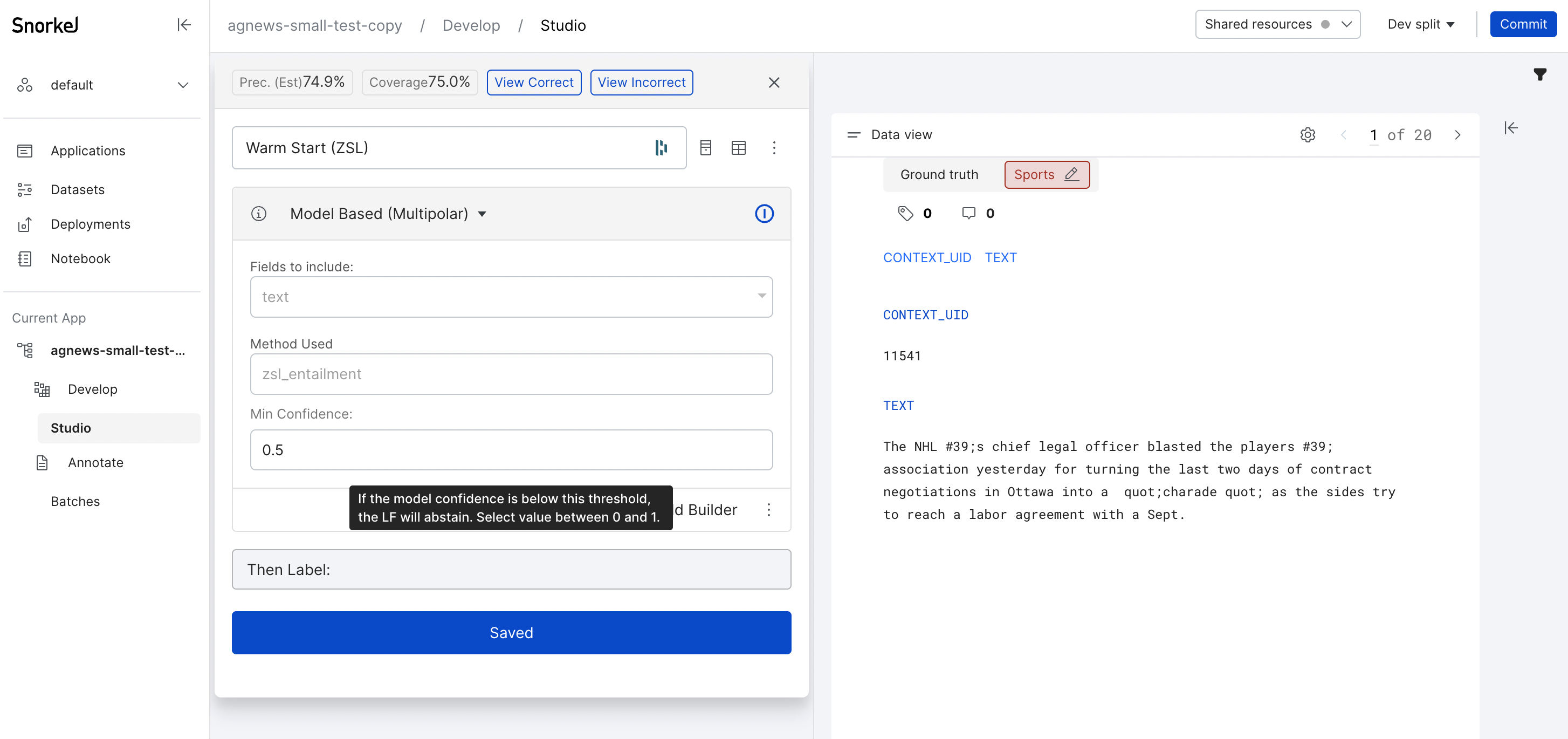
Once a warm start LF is active, you can edit the confidence threshold to further customize it. The confidence value reflects the foundation model's certainty in its predictions. Increasing the threshold trades off coverage for precision:
- Higher confidence thresholds mean that the model must be more certain before making a prediction. This increases precision, but decreases coverage.
- Lower confidence thresholds mean that the model can make more predictions, even when less certain. This increases coverage, but decreases precision.
For more advanced warm start capabilities and granular configuration, see Warm start (SDK).