(Beta) Use LLMs for extracting candidate spans in PDF Applications
PDF extraction applications often require accurate span extractors; however, defining span extractors can be challenging. For example, extracting addresses from PDFs. In addition, in Snorkel Flow, different models are trained for each type of span extractor. This requires SMEs to annotate and review the same document multiple times.
To address these challenges and inefficiencies, this page walks through how to utilize LLMs to define candidate span extractors for PDF applications.
This functionality is a beta launch that is only made available on a request basis. Please contact your Snorkel representative if you are interested in getting access.
Set up your application
Follow steps 1-3 in Create application: A guided flow to set up your application:
- Access the onboarding workflow and enter an application name.
- Upload your data.
- Specify your data and task type. In this example, we are selecting PDF extraction. Both scanned and native PDF types are supported. For information about scanned PDFs, see our Scanned PDF guide.
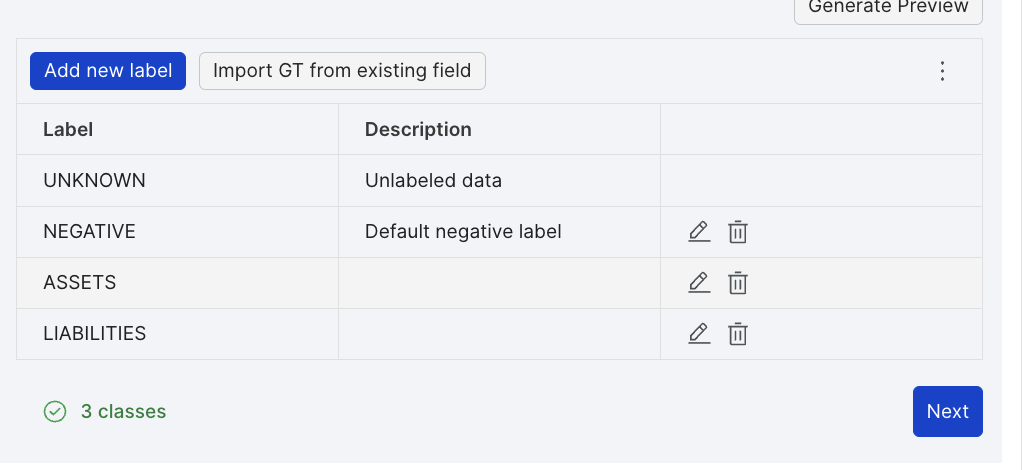
- Create a label schema. In this example, we are exploring using an LLM extractor to extract assets and liabilities from a balance sheet.
Define the LLM extractor
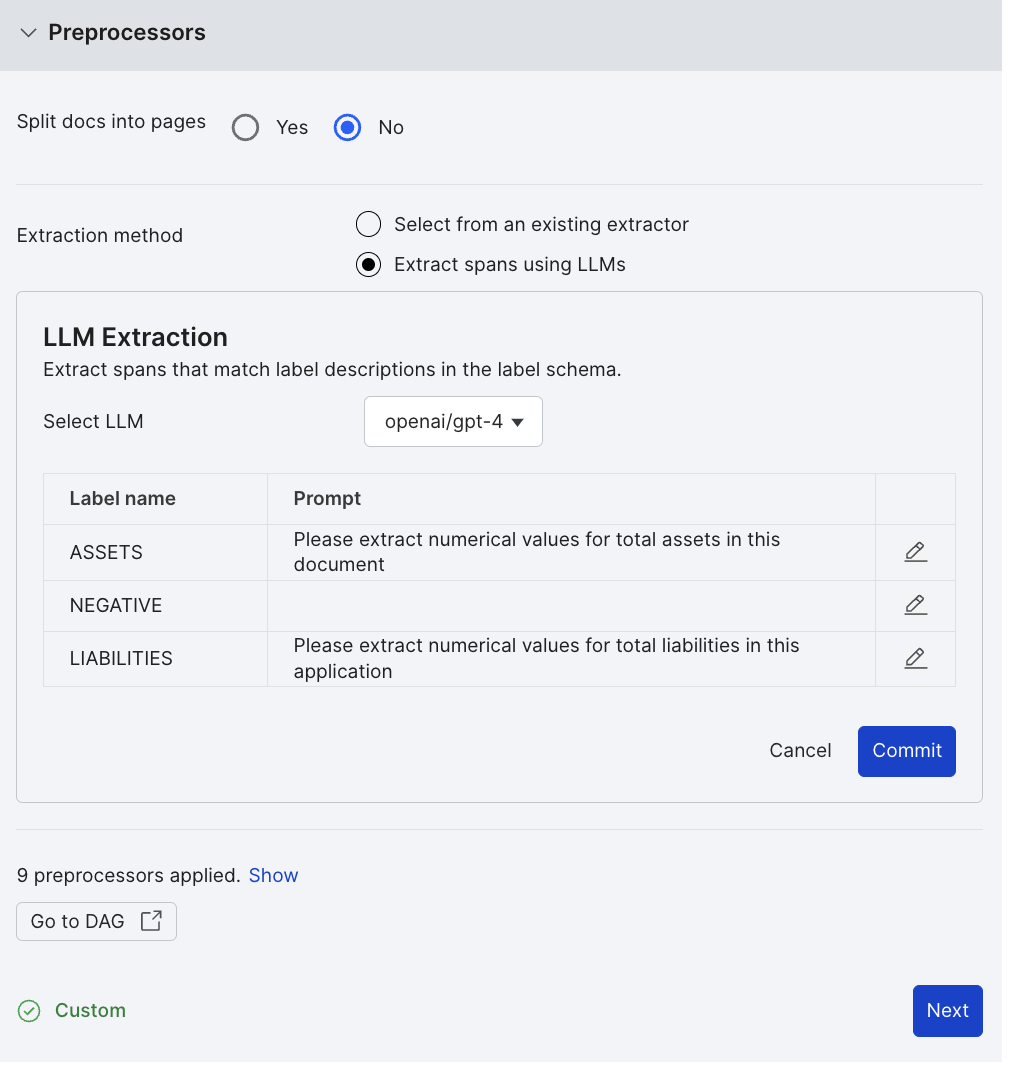
On the Preprocessors accordion, define an LLM extractor:
- Select an LLM model from the available options (e.g.,
openai/gpt-4). - Write prompts for extracting entities for each label. In this example:
- Assets prompt: Please extract numerical values for total assets in this document.
- Liabilities prompt: Please extract numerical values for total liabilities in this document.
- Click Commit to commit the extractor configuration.
Preview and refine the extracted spans
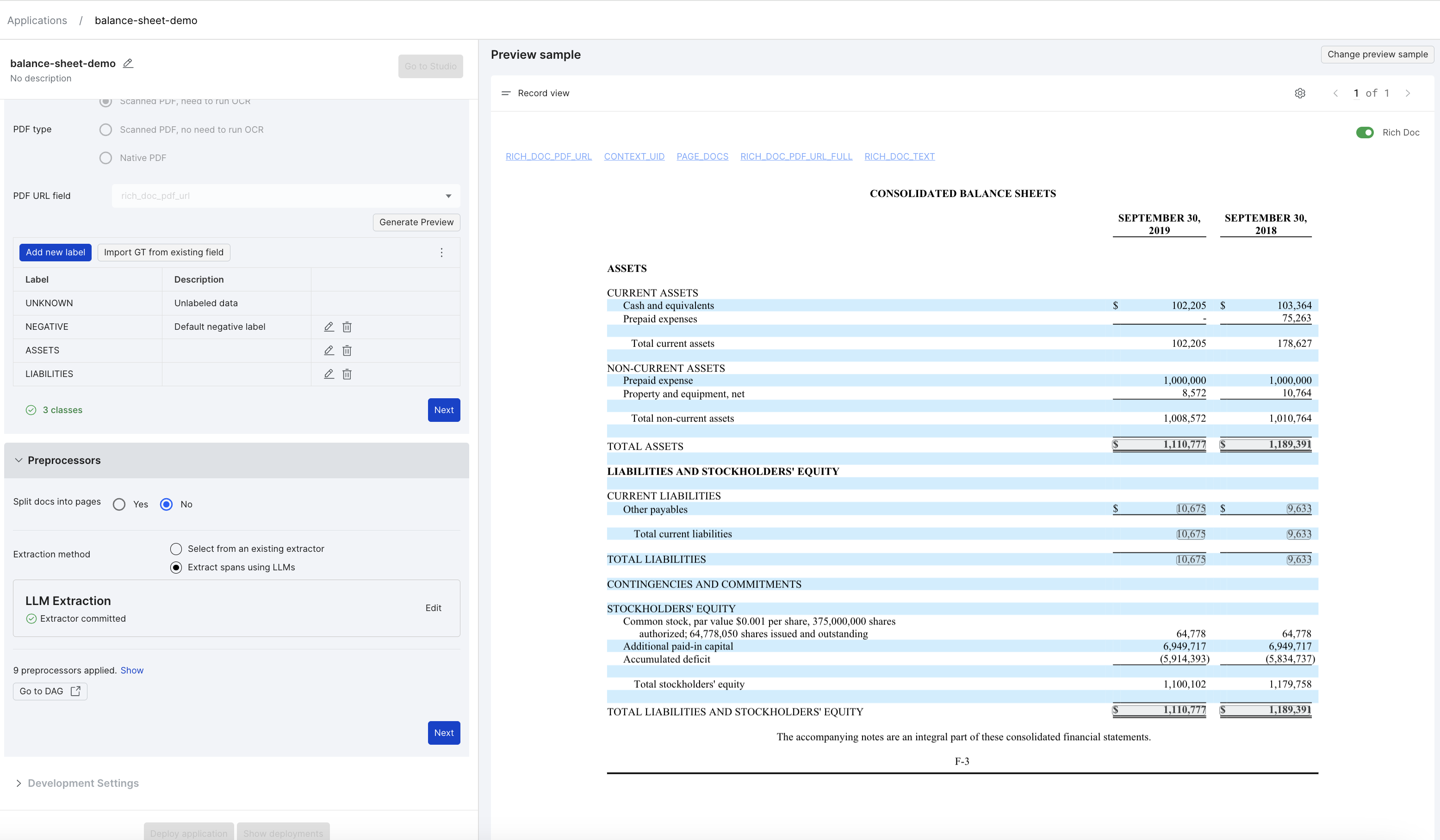
You can view the extracted spans on the Preview sample pane. This will help you evaluate the effectiveness of the extractor. You can then modify and commit the extractor as many times as you need until you are happy with the output of the extractor.
Run the extractor on all data splits
Once you are satisfied with the extracted spans, click Next to run the extractor on all data splits.
One job for each label class will automatically be kicked off to create zero-shot labeling functions on the extracted spans. For more information about zero-shot LFs, see Warm LF types.
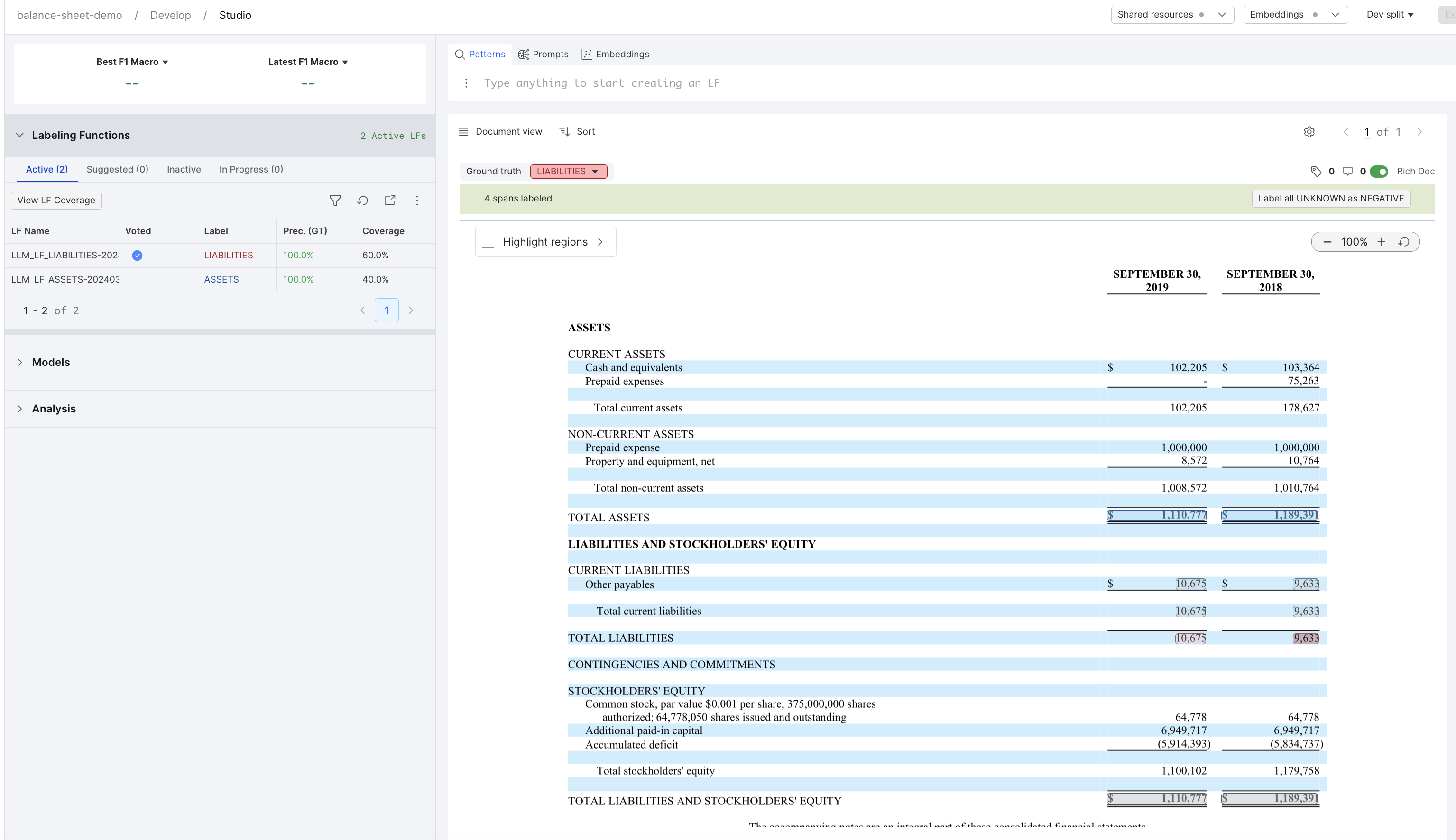
View the extracted spans
Once you have finished setting up your application, open it in Studio.
- In the dataviewer, you'll be able to see the extracted spans for each PDF.
- In the Labeling Functions pane, you'll be able to see the zero-shot labeling functions that were created.
Summary
By leveraging LLMs, you can streamline the process of defining span extractors for PDF extraction applications. This approach improves efficiency and reduces the need for manual annotation and review of documents.