Suggested LFs
Introduction to autosuggest in Snorkel Flow
Creating the initial labeling functions (LFs) can sometimes be challenging when working on a new ML task. To help bootstrap LF development, Snorkel Flow allows users to automatically generate LFs using several strategies that vary by application template. This guide walks through automated strategies and how best to incorporate them into your iterative, data-centric development process.
What is autosuggest?
Autosuggest within Snorkel Flow can be divided into two broad categories: few-shot and zero-shot learning strategies. In the case of few-shot learning, Snorkel Flow expects at least some labeled documents per class to recommend high-quality LFs to the user. These labeled documents or data points must be available within your train sample (i.e., dev set). In the case of zero-shot, where no labeled data is required, these strategies rely solely on the class names that are incorporated into a Foundation Model (FM) or just a simple pattern-based lookup in select fields. For more information about FM support in Snorkel Flow, see Foundation model suite.
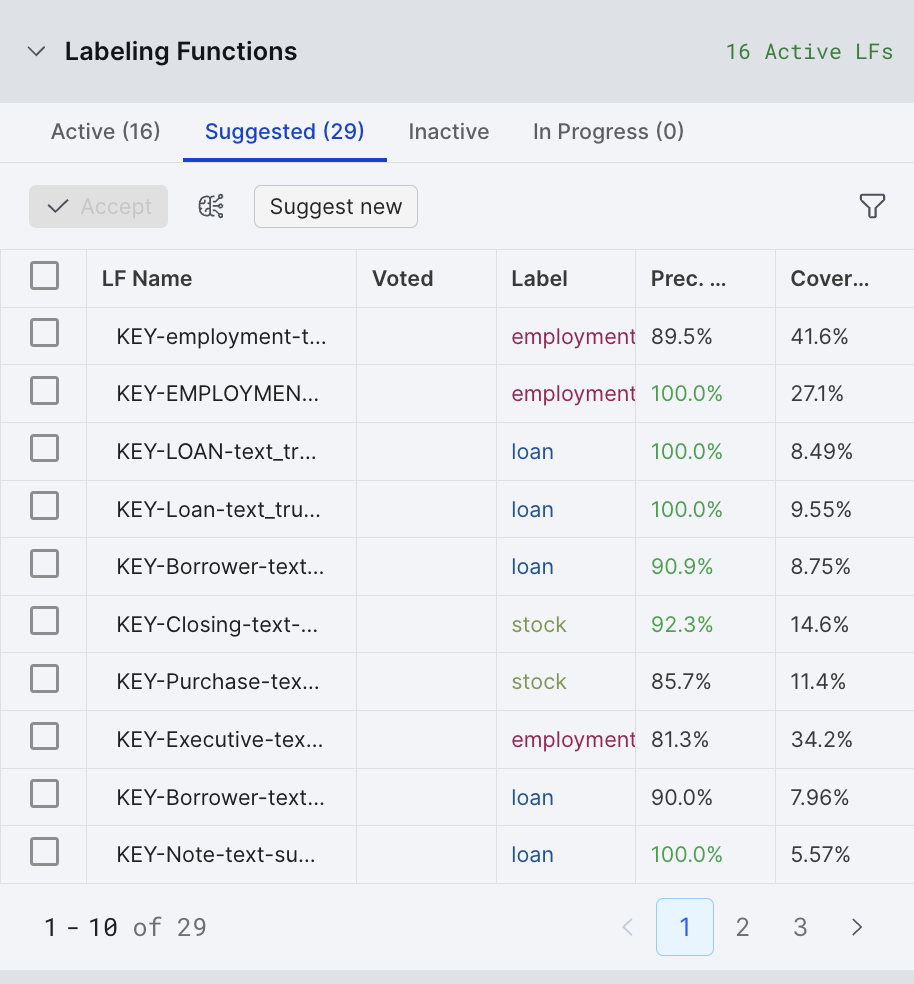
Figure 1: LF autosuggest strategies can be run manually by selecting the Suggest new button or automatically during Studio load. You can review them individually in the Suggested pane.
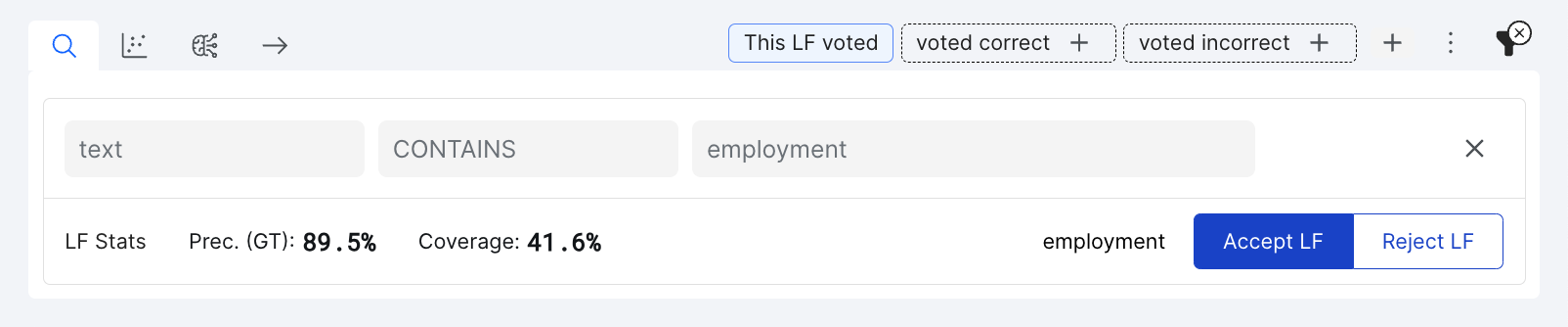
Figure 2: you can also find LF suggestions by selecting the lightning bolt icon in the search box
How does Autosuggest work?
Most of the existing Autosuggest LF strategies are supervised approaches, meaning you need at least a few ground truth (GT) examples for each class labeled before you can use the approach. The more GT you have in your sample, the better the suggested LFs will be in terms of generalization. If you don’t have enough GT, there’s a chance that your LFs could overfit to your small labeled set. In addition, some strategies may require an operator or two in the DAG before you can employ the suggestion strategy. These operators featurize the data (e.g., add embeddings for a specific field) and cache them for later use.
See the Strategies section below to get more detail on each method.
- Text classification
- PDF classification (OCR and native PDF)
- Multi-label classification
- Text extraction
- Sequence tagging
- PDF extraction (hOCR and native PDF)
- Utterance / conversation classification
When to use autosuggest?
Each application template has a default, “push-based” suggestion strategy that runs when you load your application in Studio. This assumes that your application has at least some labeled data in your dev split (a sample of the train split). Once the default LF suggestion strategy has returned some LFs, they will remain available for review. If you’d like to refresh the suggestions, you may generate them manually by selecting the suggestion strategy and options from the Suggested pane.
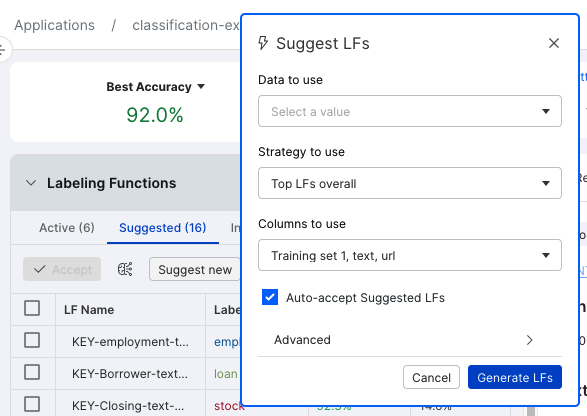
Figure 3: LF suggestions are populated below the Suggested pane.
Once generated, you can review and accept or reject the LFs. You also have the option to automatically accept all suggested LFs from a given strategy.
Autosuggest strategies by application template
Text classification
| LF Suggestion Strategies | Input | Description |
|---|---|---|
| Simple Keyword | Text fields | Given an ngram range, Keyword LFs are generated from selected text fields that are tokenized (case sensitive, English stopwords excluded) and run through a CountVectorizer. Keywords are then sorted by the count of the word in class X minus the count of the word in all other classes. |
| Simple Keyword/Numeric | Float or int fields | In addition to the Simple Keyword strategy, uses int or float-based fields, and calculates a linear threshold (e.g., x > 10) that achieves a minimum desired precision. Note: This is the default strategy for this application template. |
| TFIDF | Text fields | Generate a keyword LF that is based on the sorted logistic regression coefficients of absolute value. Model features are generated using TF-IDF. |
| Keyword Count | Text fields | Similar to TFIDF strategy, but instead, a Keyword Count LF is created based on the frequency of the keyword. |
| Model-base generator (experimental) | Text or numeric fields | The standard options include a Logistic Regression model trained over text (TF-IDF) or numeric features. |
| Embedding Based | Embedding field | An SVM model is trained over embeddings computed over a text field. Requires adding the EmbeddingFeaturizer operator to the DAG. |
| Embedding Nearest Neighbor | Embedding field | For each datapoint we compute the nearest class based on the embedding of the class. We use cosine similarity to compute the nearest neighbor. Output of this strategy is a multipolar LF. |
| Hierarchical TF-IDF | Text fields | We compute top ngrams for each class using TFIDF in a hierarchical fashion and create a multipolar keyword based LF. |
| Search for Class Name (experimental) | Text fields | For each label does a case insensitive lookup of the name in the provided fields and returns the most commonly occurring label as the LF. |
PDF classification (OCR and native PDF)
| LF Suggestion Strategies | Input | Description |
|---|---|---|
| Simple Keyword | Text fields | Given an ngram range, Keyword LFs are generated from selected text fields that are tokenized (case sensitive, English stopwords excluded) and run through a CountVectorizer. Keywords are then sorted by the count of the word in class X minus the count of the word in all other classes. |
| Simple Keyword/Numeric | Float or int fields | In addition to the Simple Keyword strategy, uses int or float-based fields, and calculates a linear threshold (e.g., x > 10) that achieves a minimum desired precision. Note: This is the default strategy for this application template. |
| TFIDF | Text fields | Generates a keyword LF that is based on the sorted logistic regression coefficients of absolute value. Model features are generated using TF-IDF. |
| Model-base generator (experimental) | Text or numeric fields | The standard options include a Logistic Regression model trained over text (TF-IDF) or numeric features. |
| Embedding Based: | Embedding field | An SVM model is trained over embeddings computed over a text field. Requires adding the EmbeddingFeaturizer operator to the DAG. |
| Embedding Nearest Neighbor | Embedding field | For each datapoint we compute the nearest class based on the embedding of the class. We use cosine similarity to compute the nearest neighbor. Output of this strategy is a multipolar LF. |
| Hierarchical TF-IDF | Text fields | We compute top ngrams for each class using TFIDF in a hierarchical fashion and create a multipolar keyword based LF. |
| Search for Class Name (experimental) | Text fields | For each label, does a case-insensitive lookup of the name in the provided fields and returns the most commonly occurring label as the LF. |
Multi-label classification
| LF Suggestion Strategies | Input | Description |
|---|---|---|
| Simple Keyword | Text fields | Given an ngram range, Keyword LFs are generated from selected text fields that are tokenized (case sensitive, English stopwords excluded) and run through a CountVectorizer. Keywords are then sorted by the count of the word in class X minus the count of the word in all other classes. Note: This is the default strategy for this application template. |
| Simple Keyword/Numeric | Float or int fields | In addition to the Simple Keyword strategy, uses int or float-based fields, and calculates a linear threshold (e.g., x > 10) that achieves a minimum desired precision. |
| TFIDF | Text fields | Generates a keyword LF that is based on the sorted logistic regression coefficients of absolute value. Model features are generated using TF-IDF. |
| Model-base generator (experimental) | Text or numeric fields | The standard options include a Logistic Regression model trained over text (TF-IDF) or numeric features. |
| Search for Class Name (experimental) | Text fields | For each label does a case-insensitive lookup of the name in the provided fields and returns the most commonly occurring label as the LF. |
Text extraction
| LF Suggestion Strategies | Input | Description |
|---|---|---|
| Simple Keyword | Text fields | Given an ngram range, Keyword LFs are generated from selected text fields that are tokenized (case sensitive, English stopwords excluded) and run through a CountVectorizer. Keywords are then sorted by the count of the word in class X minus the count of the word in all other classes. |
| Simple Keyword/Numeric | Float or int fields | In addition to the Simple Keyword strategy, uses int or float-based fields, and calculates a linear threshold (e.g., x > 10) that achieves a minimum desired precision. |
| TFIDF | Text fields | Generates a keyword LF that is based on the sorted logistic regression coefficients of absolute value. Model features are generated using TF-IDF. |
| Span-Based | span_text field | Generates keywords from span_text and its corresponding context windows. Note: This is the default strategy for this application template. |
| Model-base generator (experimental) | Text or numeric fields | The standard options include a Logistic Regression model trained over text (TF-IDF) or numeric features. |
| Search for Class Name (experimental) | Test fields | For each label does a case insensitive lookup of the name in the provided fields and returns the most commonly occurring label as the LF. |
Sequence tagging
| LF Suggestion Strategies | Input | Description |
|---|---|---|
| Embedding-based | Embedding field | An SVM model is trained over embeddings computed over candidate spans. Requires adding two operators to the DAG: a featurizer that creates a new column with candidate spans (e.g., NounChunkSpanFeaturizer, VerbPhraseFeaturizer) and the EmbeddingCandidateFeaturizer that converts the candidate features into embeddings. Note: This is the default strategy for this application template. |
| Spacy NER / Property-based | Spacy generated “doc” field OR “NER” field from Spacy or BERT | Requires the SpacyPreprocessor to extract these entities. Must select the “doc” field OR “NER” fields from Spacy or BERT when using this strategy. |
PDF extraction (hOCR and native PDF)
| LF Suggestion Strategies | Input | Description |
|---|---|---|
| Simple Keyword | Text fields | Given an ngram range, Keyword LFs are generated from selected text fields that are tokenized (case sensitive, English stopwords excluded) and run through a CountVectorizer. Keywords are then sorted by the count of the word in class X minus the count of the word in all other classes. Note: This is the default strategy for this application template. |
| Simple Keyword/Numeric | Float or int fields | In addition to the Simple Keyword strategy, uses int or float-based fields, and calculates a linear threshold (e.g., x > 10) that achieves a minimum desired precision. |
| Model-base generator (experimental) | Text or numeric fields | The standard options include a Logistic Regression model trained over text (TF-IDF) or numeric features. |
| Search for Class Name (experimental) | Test fields | For each label does a case-insensitive lookup of the name in the provided fields and returns the most commonly occurring label as the LF. |
Utterance / conversation classification
| LF Suggestion Strategies | Input | Description |
|---|---|---|
| Simple Keyword | Text fields | Given an ngram range, Keyword LFs are generated from selected text fields that are tokenized (case sensitive, English stopwords excluded) and run through a CountVectorizer. Keywords are then sorted by the count of the word in class X minus the count of the word in all other classes. |
| Simple Keyword/Numeric | Float or int fields | In addition to the Simple Keyword strategy, uses int or float-based fields, and calculates a linear threshold (e.g., x > 10) that achieves a minimum desired precision. |
| TFIDF | Text fields | Generates a keyword LF that is based on the sorted logistic regression coefficients of absolute value. Model features are generated using TF-IDF. |
| Model-base generator (experimental) | Text or numeric fields | The standard options include a Logistic Regression model trained over text (TF-IDF) or numeric features. |
| Embedding-based | Embedding field | An SVM model is trained over embeddings computed over a text field. Requires adding the EmbeddingFeaturizer operator to the DAG. |
| Embedding Nearest Neighbor | Embedding field | For each datapoint we compute the nearest class based on the embedding of the class. We use cosine similarity to compute the nearest neighbor. Output of this strategy is a multipolar LF. |
| Hierarchical TF-IDF | Text fields | We compute top ngrams for each class using TFIDF in a hierarchical fashion and create a multipolar keyword based LF. |
| Conversation-Based Input | Utterance field | Returns keywords based on the same strategy as the Keyword strategy, but the input field consists of joined utterances (no speaker names) |
Note: This is the default strategy for this application template. | | Search for Class Name (experimental) | Test fields | For each label does a case-insensitive lookup of the name in the provided fields and returns the most commonly occurring label as the LF. |
Best practices
- Since most of the suggestion strategies require some GT labels, increasing the amount of labeled data and re-running the suggestion strategies can generate higher-quality LFs, even when running the same strategy.
- Think carefully about which fields you feed to the suggestion strategies. For example, if you’ve preprocessed your data and truncated a text field, passing both the truncated and untruncated fields to the suggestion algorithm will likely return similar LFs.
- Try to incorporate multiple different LF autosuggest strategies to increase the diversity of signals. Simple, interpretable techniques like Keyword or Numeric LFs combined with more sophisticated, model, or embedding-based strategies can improve overall performance.
FAQ
- I created a new application and see zero suggestions in the Suggested pane. Why?
There are three possibilities: your application does not have enough labeled data per class, the LF suggestion strategy didn't identify any LFs that meet the minimum performance thresholds, or the DAG does not have the required operators for suggested strategies to perform. If you manually re-run the LF suggestion strategy and no new LFs are identified, you will see a message stating this. To fix this, you can try a different LF suggestion strategy and/or label more GT and re-run the suggestion strategy.
- What if suggested LFs are similar to active or other suggested LFs?
On the one hand, it can still be helpful to manually ensure that the suggested LFs that you accept are unique and not duplicative with existing LFs. You can also do this proactively by being mindful of duplicative signals in the fields you feed to the automated suggestion strategies. On the other hand, it’s not absolutely necessary to deduplicate similar LFs since the label model has the ability to differentiate between LF signals by examining their agreements and disagreements.