Multi-label classification: Predicting tags of posts on Stack Exchange
We will demonstrate how to use Snorkel Flow for a simple multi-label classification problem: predicting tags that were added to posts on Stack Exchange, specifically on the Cross Validated board which covers: “statistics, machine learning, data analysis, data mining, and data visualization.” Each data point contains the text of the posted question title, question body, answer, some generic metadata; as well as tags which will be our independent variable. Given that a datapoint may contain 0 to N tags where N is the number of possible tags, we will use Snorkel Flow’s Multi-Label Application Template.
- How to create a multi-label classification application
- How to write labeling functions for multi-label datasets
Create a dataset
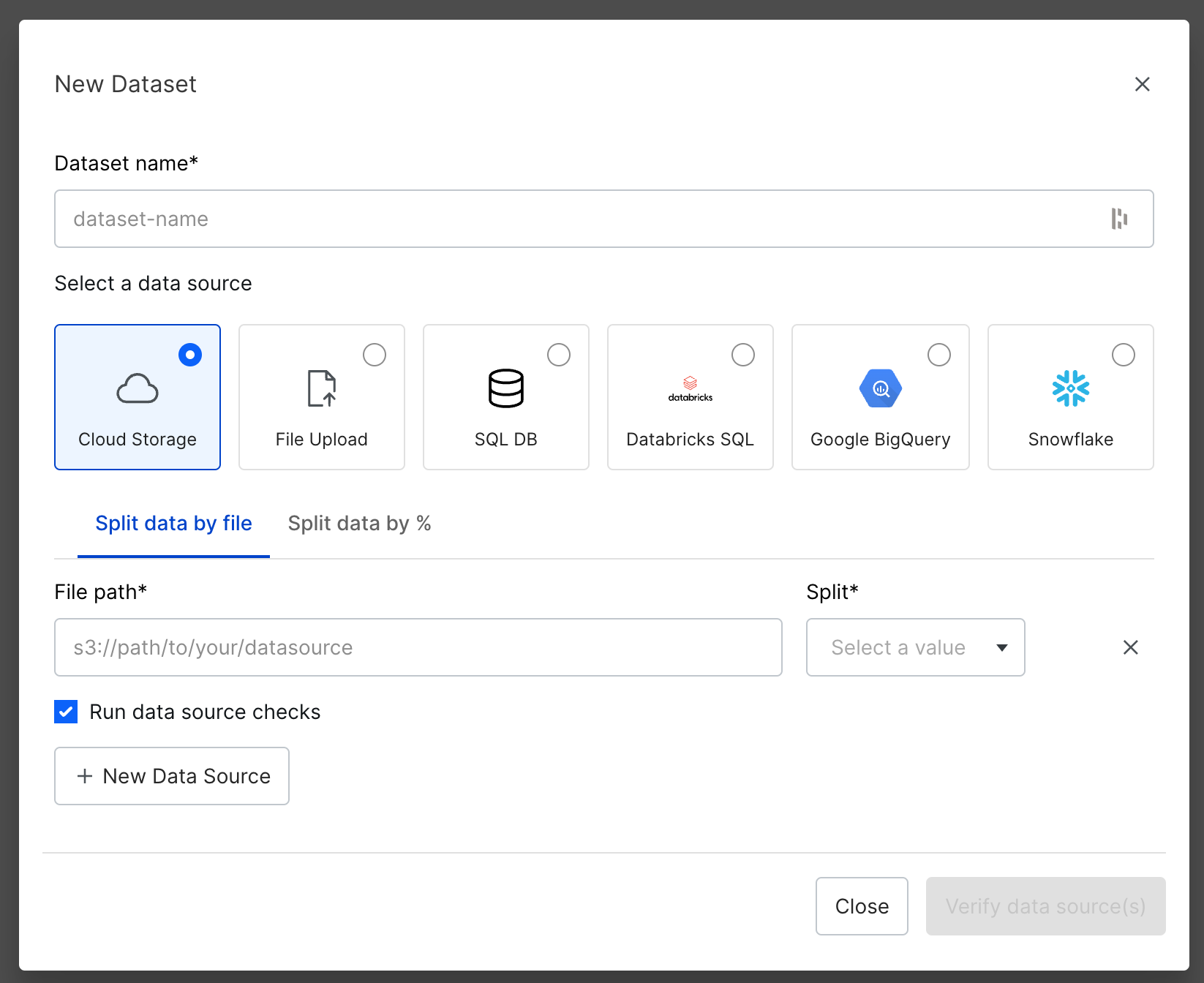
Navigate to the Datasets page from the sidebar menu. Click on + New dataset.

Use stats-questions as your dataset name and the following parquet-based data sources with the specified splits. Use Id as the UID column.
| split | path |
|---|---|
| train | s3://snorkel-statsquestions-dataset/train_n20.parquet |
| valid | s3://snorkel-statsquestions-dataset/valid_n20.parquet |
| test | s3://snorkel-statsquestions-dataset/test_n20.parquet |
Multi-label label format
In general, multi-label labels have a unique format that must be maintained to be able to upload, export, and transfer labels on the platform. Multi-label labels are a dictionary that has the label classes as keys, and the “vote” assigned to each class as values. In contrast to other libraries, which only permit a binary vote on each class, Snorkel Flow also permits you to abstain from voting on a class (your classes can be partially labeled). The “vote” values then are any of "PRESENT", "ABSENT", or "ABSTAIN".
Example:
'{
"r": "PRESENT",
"regression": "PRESENT",
"bayesian": "ABSTAIN",
"probability": "ABSENT",
"time-series":"ABSTAIN"
}'.
Importing and exporting ground truth, training set labels, and model predictions
-
Importing Ground Truth
- Import Ground Truth by file: your labels should be JSON-serialized (ie. they should be strings, not raw JSON objects). You can use SDK sf.import_ground_truth to upload your Ground Truth by file.
- Add Ground Truth for your list of datapoints using SDK function sf.add_ground_truth. deserialize the labels to be in their original data structure:
-
x_uids = ["doc::0"]
labels = ['{ "r": "PRESENT", "regression": "PRESENT", "bayesian": "ABSTAIN", "probability": "ABSENT", "time-series":"ABSTAIN" }'.]
# This will fail since the labels are JSON serialized as strings
sf.add_ground_truth(node, x_uids, labels, user_format=True)
# This will succeed since the labels have been deserialized into their original data structures
deserialized_labels = [json.loads(label) for label in labels]
sf.add_ground_truth(node, x_uids, deserialized_labels, user_format=True)
-
-
Exporting training set labels
- Use the SDK function sf.get_training_set as below, this will give you a dataframe containing all fields for training, and a field named `training_set_labels`:
-
sf.get_training_set(NODE_UID, uid=TRAINING_SET_UID, user_format=True)
-
Exporting model predictions
- Use the SDK function sf.get_predictions as below, this will give you a dataframe containing two columns:
predsandprobs: -
sf.get_predictions(NODE_UID, model_uid=MODEL_UID, user_format=True)
- Use the SDK function sf.get_predictions as below, this will give you a dataframe containing two columns:
Create a multi-label classification application
In the home page (applications page), click on the caret icon in the Create application button and select Create from template in the dropdown.

Select Multi-label Classification template on the template page.
Click the Create application button.
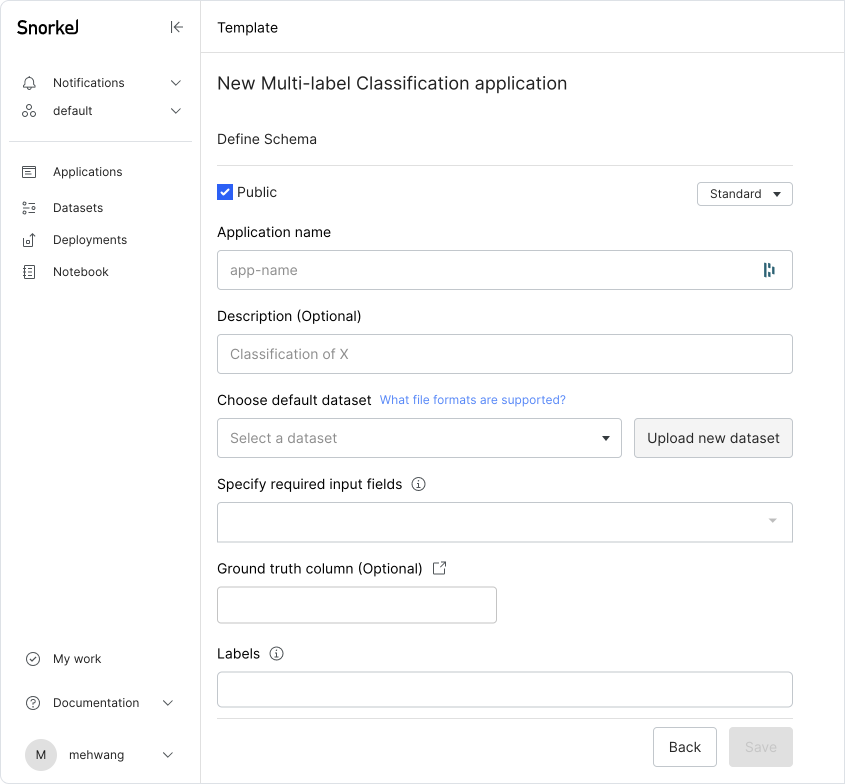
Fill out the fields as described below:
- Application name:
question-tag-clf - Description (Optional):
Multi-label classification task - Choose default dataset:
stats-questions(created above) - Specify required input fields: Click on Select all
- Ground Truth column (Optional):
Tag - Labels:
bayesian,time-series,r,regression,probability
Data splits
This task consists of three data splits: train, valid, and test. Data points in the valid and test splits have ground truth labels assigned to them. The train split is partially labeled and we’ll use Snorkel Flow to label the rest of it.
| train | valid | test | |
|---|---|---|---|
| # data points | 25,664 | 3,667 | 7,333 |
| # ground truth labels | 9,468 | 1,340 | 2,627 |
Write labeling functions
Filters
Note how filters operate somewhat differently to search for matching labels in the multi-label setting. When searching for ground truth, LF, model prediction, or training set votes, we can select from “present”, “absent”, or “abstain” for a particular class. That is, to find any doc where the “bayesian” tag exists, we use the filter Ground truth is "present" on "bayesian". In addition to just searching for a particular class, filtering can be applied on any/all classes. These filters will check that any/all non-abstain values match the condition.
- Incorrect predictions: If there is at least one mistake in predicting the presence or absence of a label when GT is not abstained
- Correct predictions: When all classes of non-abstained prediction matches all classes of non-abstained GT, it's considered correct.
- Unknown predictions: If all the classes of a datapoint are abstained, the prediction is considered as "UNKNOWN."
LF builders for multi-label classification
Our data comes with three relevant text fields:
Title: title of the postBody_q: the body of the asker’s questionBody_a: the body of the top responder’s answer
Note that for multi-label, each class can give its own vote for a single datapoint, e.g. a Title like “Time Series Analysis in R” could have a ground truth label of: time-series: PRESENT, r: PRESENT, bayesian: ABSENT, regression: ABSENT, probability: ABSENT. As such, labeling functions vote in a similar format, where each class can vote either “PRESENT”, “ABSENT”, or “ABSTAIN”.
In a single-label setting, voting for one label implicitly tells our model that the other labels are absent. In a multi-label setting, this is not true since the presence of one label doesn’t give any information about the other labels. Therefore, we should try to write labeling functions over both “PRESENT” examples and “ABSENT” examples for each class. If a class only has “PRESENT” votes, the model will naively learn to vote “PRESENT” on every example!
Below are some sample labeling functions you can try out. You can combine multiple labeling functions using Add another builder (and) or Add another builder (or) from the LF builder dropdown.

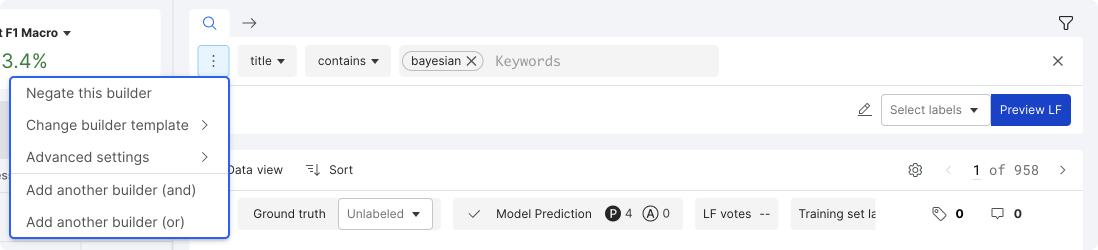
-
KEY-bayesian
-
Pattern Based LFs > Keyword Builder
TitleCONTAINS["bayesian"]
-
OR -
Pattern Based LFs > Keyword Builder
Body_qCONTAINS["bayesian", "MCMC", "GMM"]
-
Label:
bayesian: PRESENT, time-series: ABSENT
-
-
KEY-regression
-
Pattern Based LFs > Keyword Builder
Body_qCONTAINS["linear regression"]
-
OR -
Pattern Based LFs > Keyword Builder
TitleCONTAINS["regression"]
-
Label:
regression: PRESENT
-
-
KEY-time-series
-
Pattern Based LFs > Keyword Builder
Body_qCONTAINS["time series"]
-
Label:
time-series: PRESENT, bayesian: ABSENT, regression: ABSENT, probability: ABSENT
-
-
RGX-probability
-
Pattern Based LFs > Regex Builder
Body_aprobabili
-
AND -
Pattern Based LFs > Regex Builder
Titleprobabili
-
Label:
probability: PRESENT, time-series: ABSENT
-
-
RGX-R
-
Pattern Based LFs > Regex Builder
Body_q\bin R\W
-
Label:
r: PRESENT, time-series: ABSENT
-
After saving an LF, you’ll see the macro-averaged score for that LF across all voted classes. The View Incorrect button can be used to iterate on the LF.
Train a model
Model training is allowed without covering every class with present and absent votes, though it is recommended for the reasons above. After creating a labeled dataset, try training a simple Logistic Regression (TFIDF) model. For input fields, use the same fields we used for writing labeling functions: Title, Body_q, Body_a.
View errors and iterate
In a single-label setting, we have a single analysis page that covers all labels. In the case of multi-label, we have per-class analysis sections for each label class.
Class level metric: This table displays the classic metrics (accuracy, recall, precision, and F1) for each individual class and is shown by default when entering the Analysis section for the first time.
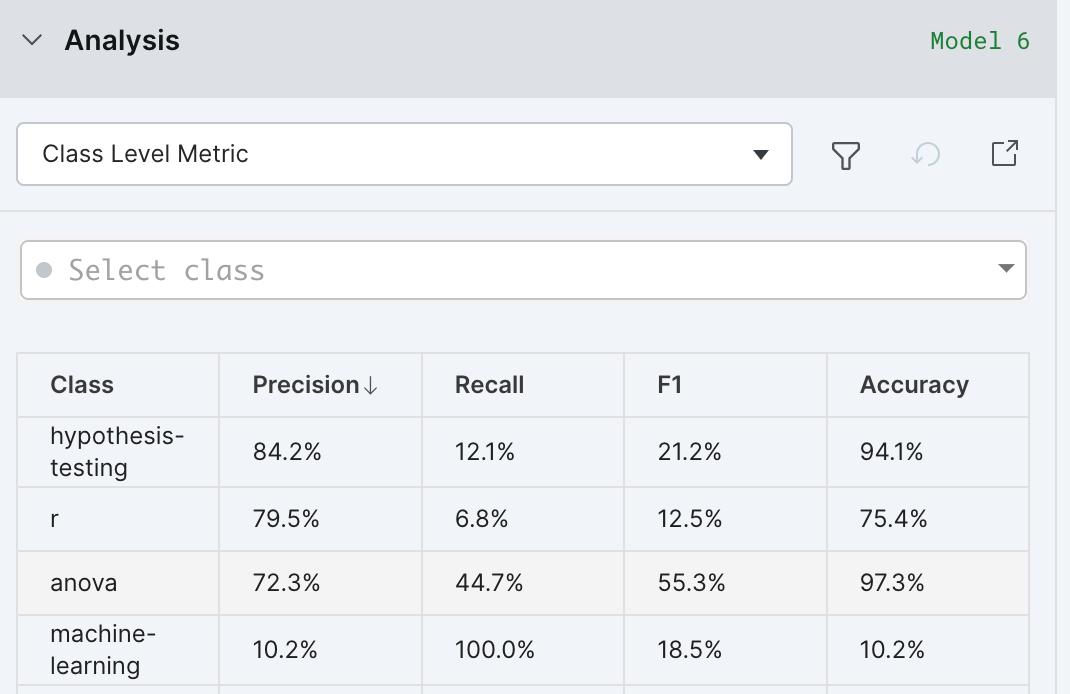
Recommended analysis flow is to sort by any metric of interest in the class level metric table to determine the class to work on. Then select that class in the class selector to proceed to do per class analysis with other analysis tools of your choice like clarity matrix, confusion matrix etc.,. Repeat these steps for each class until a desired model performance is reached.
Clarity matrix: only contains datapoints relevant to the current class. Every data point with ground truth is represented exactly once in each per-class clarity matrix.
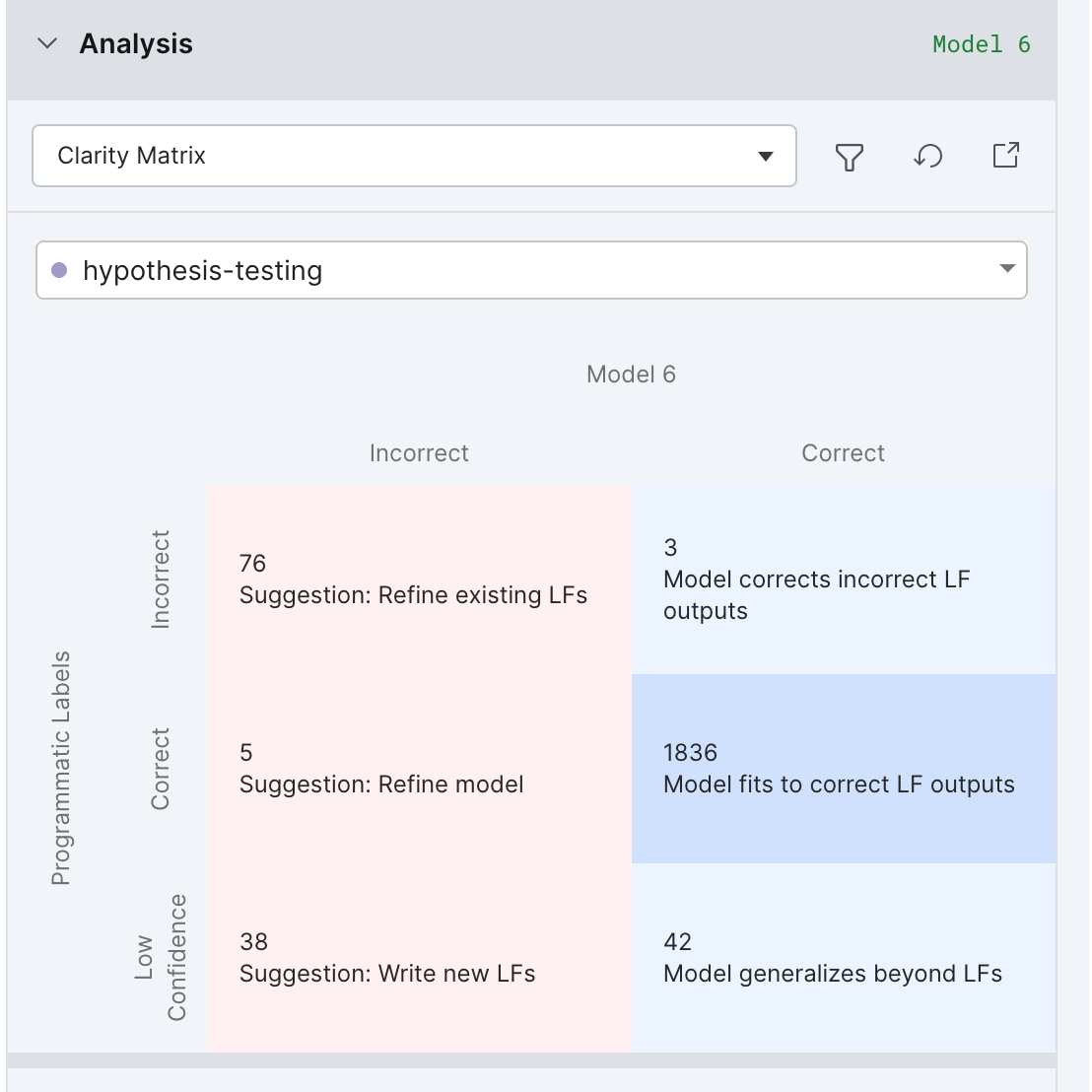
Confusion matrix: only contains datapoints relevant to the current class.
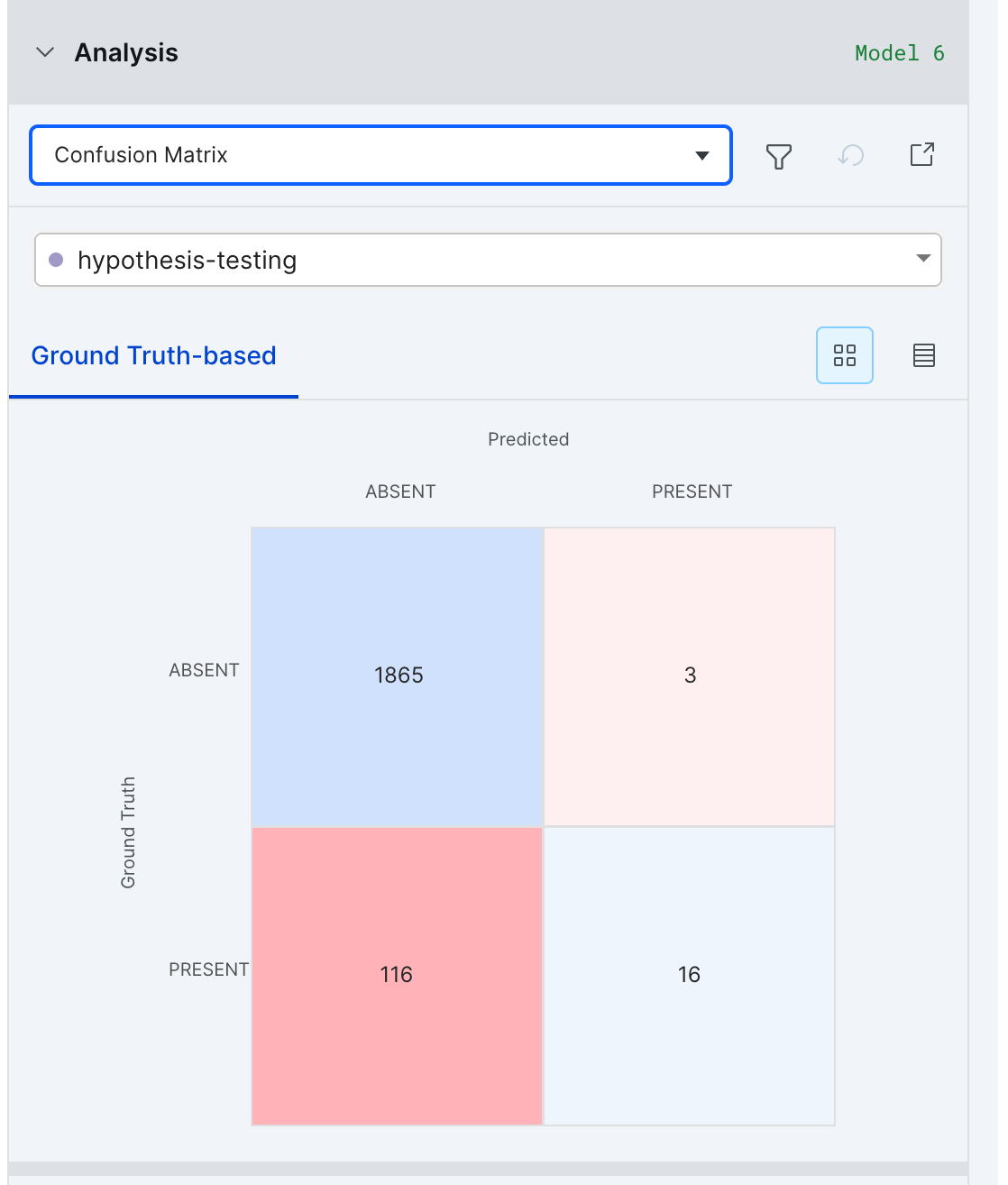
Metrics
Snorkel Flow provides a set of metrics that help power our analysis suite and guide iteration.
- Standard metrics: In a traditional multi-class classification problem, the definitions of various metrics (such as accuracy, precision, and recall) align with their standard textbook definitions. In a multi-label setting, we instead opt to take the macro-averaged forms of these metrics, meaning we calculate per-class metrics over all classes and then take the average. We only calculate these metrics over points where neither the ground truth nor the prediction are
ABSTAINs. - Aggregated metrics: Multi-label classification also supplies aggregate set-valued metrics, described in the platform as
any-presentandall-present. For a data point to receive a score under these metrics, the ground truth and prediction must overlap (non-abstain) on at least one class; and at least one of them must votePRESENTon a class in the “overlap”. If one of the two votes abstains, we do not count that class in our metric calculation. Of the classes in the “overlap”,any-presentis true when both the ground truth and prediction votePRESENTon at least one class, andall-presentis true when both the ground truth and prediction votePRESENTon all the same classes.-
Example:
ground_truth: {"Class0": "PRESENT", "Class1": "ABSENT", "Class2": "ABSTAIN"}
prediction: {"Class0": "PRESENT", "Class1": "PRESENT", "Class2": "ABSENT"}
ALL: False, since not all PRESENT votes line up among points where neither abstained.
ANY: True, since one PRESENT vote lines up among points where neither abstained.
ground_truth: {"Class0": "PRESENT", "Class1": "ABSENT", "Class2": "ABSENT"}
prediction: {"Class0": "ABSTAIN", "Class1": "ABSENT", "Class2": "ABSENT"}
ALL: Not counted, since classes where neither abstained do not have any PRESENT votes.
ANY: Not counted, since classes where neither abstained do not have any PRESENT votes.
-
- Inter-annotator agreement metric: In contrast to the macro-averaged form of the aforementioned standard metrics, the inter-annotator agreement metric, often quantified using Krippendorff's Alpha, is evaluated by considering all classes simultaneously. For a given datapoint, the labels assigned to all classes must precisely match between the ground truth and the predicted values in order to be considered accurate.
Known limitations of multi-label classification
- End model does not support use LF as features
- Label model can not be used as end model
- Custom metrics are not supported