Extraction from PDFs: Extracting balance sheet amounts
In this tutorial, we show you how to use Snorkel Flow to extract balance sheet amounts from the SEC filings of public companies.
Snorkel Flow supports the extraction of structured information from semi-structured documents such as PDFs, HTML, and docx files. Some example use cases are extracting from financial filings, insurance claims, and medical reports. These documents are converted to a special format called "Rich Doc" in the platform. This allows you to leverage text, layout and image modalities to write labeling functions (LFs) and train models.
In this tutorial, you will learn how to:
- Upload data into Snorkel Flow
- Create an application
- Add ground truth
- Create labeling functions
- Train a model
Upload data
Data can be ingested into Snorkel Flow from a range of storage options including cloud storage, databases or local files. For PDF extraction applications we require the input data to have the following fields:
| Field name | Data type | Description |
|---|---|---|
uid | int | A unique id mapped to each row. This is standard across all Snorkel Flow datasources. |
url | str | The file path of the original PDF. This will be used to access and process the PDF. |
For this tutorial, we provide an example dataset that is saved in AWS S3 Cloud Storage. To create a new dataset:
- Click the Datasets option from the left menu
- Click the + Upload new dataset button on the top right corner of your screen
You will be brought to our New Dataset page. Fill in the New Dataset page with the following information:
- Type in the name
balance-sheets-dataset - Select Cloud storage as your data source.
- Under Split data by file, add a data source for each of the 3 data sources listed in the table below:
| Data Source | File path | Split |
|---|---|---|
| 1 | s3://snorkel-native-pdf-sample-dataset/splits/train.csv | train |
| 2 | s3://snorkel-native-pdf-sample-dataset/splits/valid.csv | valid |
| 3 | s3://snorkel-native-pdf-sample-dataset/splits/test.csv | test |
Once all information above is added, you can click Verify data source(s) to run data quality checks to ensure data is cleaned and ready to upload.
After clicking Add data source(s), you will see a UID column drop-down box. Select uid, which is the unique entry ID column in the data sources, and again click Add data source(s) to continue.
Once the data is ingested from all three data sources, you have created a new PDF extraction dataset and can move on to the next step. For more information about uploading data, see Data upload.
Create an application
There are two categories of PDF documents, native and scanned. Native PDFs are documents that were created digitally. These can be parsed without additional processing. Scanned PDFs are created from scans of printed documents. They don't have the metadata that we need to parse layout information. Scanned PDFs require additional preprocessing with an optical character recognition (OCR) library. The application creation process is slightly different for these two formats.
The documents that are used in this tutorial are native. We would like to extract the numbers from the Consolidated Balance Sheets provided in public company filings, and classify these numbers into the following classes: ASSETS, LIABILITIES and EQUITY.
Click the Applications option in the left-side menu and select Create application to create a new application. Enter the values provided in the table below.
| Stage | Field | Value |
|---|---|---|
| Data | Application name | line-item-classification |
| Dataset | balance-sheets-dataset | |
| Label schema | Data type | |
| Task type | Extraction | |
| PDF type | Native PDF | |
| PDF URL field | url |
We selected the dataset that we created in the previous step, balance-sheets-dataset, defined the data and task type, and specified where the PDFs can be found (url).
Click Generate Preview after the entering the values from the table. This will generate and display a preview sample on the right from the input documents. We will now edit the label schema table:
- Click Add new label, and then add
ASSETS,LIABILITIESandEQUITYto the table. These are the entities that we would like to extract. - Edit the
NEGATIVElabel and rename it toOTHER. Any data point that does not fall into one of the positive classes will be labeled asOTHER. - The
UNKNOWNlabel can remain as is. This is used for unlabelled data.
In the Preprocessors modal, select the following preprocessing operations to perform on the dataset:
| Stage | Field | Value |
|---|
| Preprocessors
| Split docs into pages | Yes |
| Page split method | PageSplitter |
| PageSplitter window_size | 0 |
| Extraction method | NumericSpanExtractor |
| NumericSpanExtractor field | rich_doc_text |
Click Commit for both the PageSplitter and the NumericSpanExtractor operators. Operators perform transformations on your input data. These transformations are visualized in the Preview sample pane on the right side of your screen.
- The
PageSplitteroperator splits the documents into pages. This helps us decrease memory usage, retrieve metadata more efficiently, and improve latency. - The
NumericSpanExtractoroperator is used to extract all numeric values as candidate spans from the raw text. You will see the numeric values highlighted in the Preview sample pane. - We add other operators in the background to pre-compute useful features that can be used when defining labeling functions. For more information on these operators, see PDF-based operators.
Click Next. This will start a job that runs the preprocessing operators on the entire dataset. Once the ongoing jobs are completed, select Go To Studio.
The process to set up a Scanned PDF application is very similar. In this case, you would select the Scanned PDF, no need to run OCR option for PDF type instead. For more information about preprocessing scanned PDFs, see Scanned PDF Guide.
Add ground truth
Snorkel Flow allows you to label your unlabeled data with programmatic labels. However, we still need some ground truth to validate performance! When you start a new project, you can annotate your data using our Annotation Studio.
For this tutorial, we have annotated some data for you. Click Develop to go to the Overview page. Click View Data Sources to view the data sources that we have added. In this view, you can see the total number of datapoints that are extracted for each data source. Click the Upload GTs button in the top-right corner. Enter the following details, then click Add.
| Field | Value |
|---|---|
| File path | s3://snorkel-native-pdf-sample-dataset/native_pdf_ground_truth.csv |
| File format | CSV |
| Label column | label |
| UID column | x_uid |
Refresh the page after uploading the ground truth. You should now see that the # of GT labels column has non-zero values. Click Go To Studio to return to the Studio page.
Review data in Studio
In Snorkel Flow, we perform extraction using a candidate span-based approach. Candidate spans are extracted from the raw text of the document using a heuristic. Common span types that we extract include numbers, dates and email addresses. We then define labeling functions to assign labels to the candidate spans in the document. The labels are aggregated and used to train a classification model. The spans are highlighted with bounding boxes and color-coded by label.
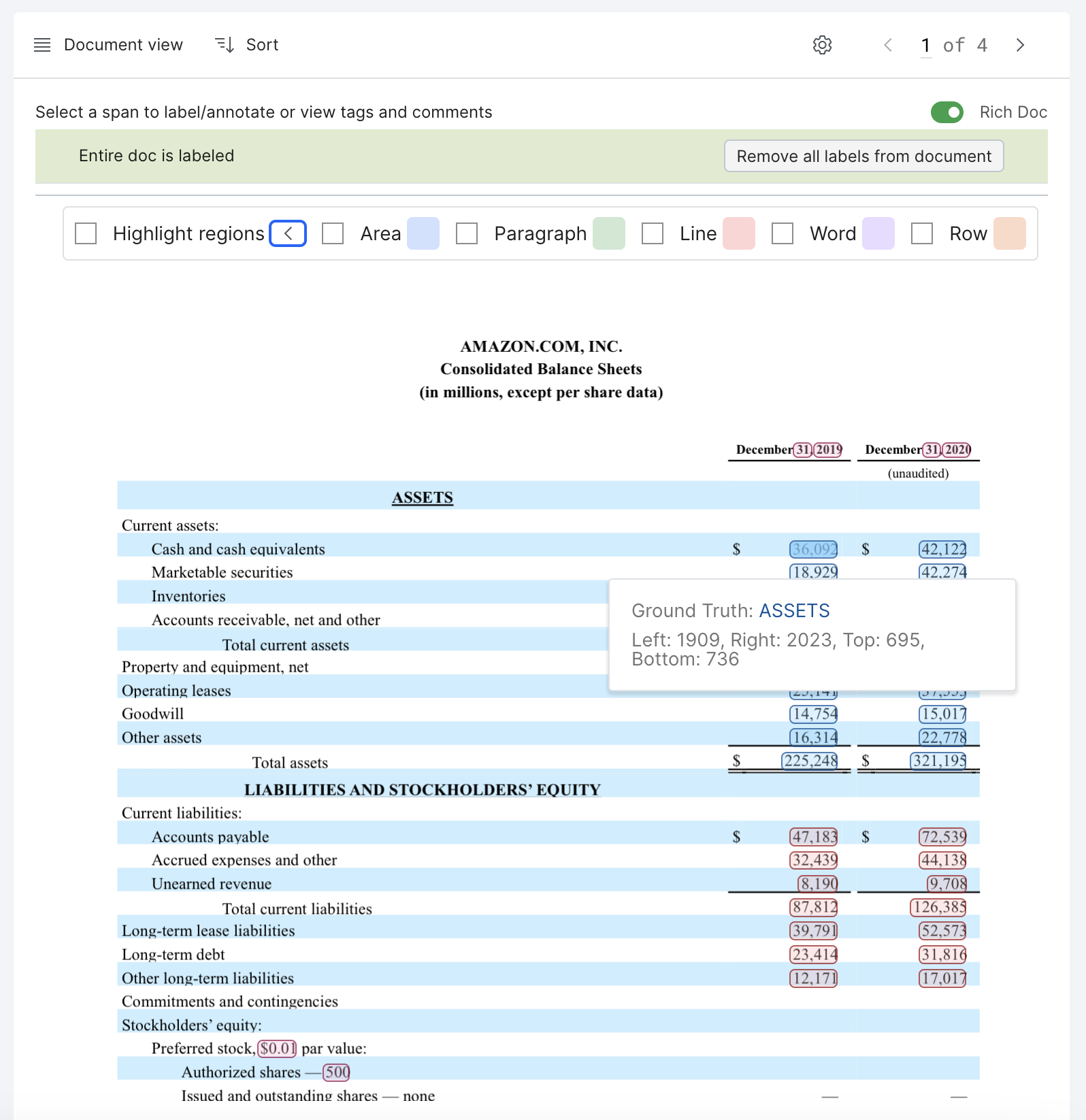
Use your cursor to hover over any word in the document. You can see the bounding box coordinates of the word (measured in pixels). Click the Rich Doc toggle, this will show you the raw text extracted from the document. Lastly, click the arrow to expand Highlight regions. This allows you to highlight the bounding boxes of the different regions in the document: row, word, line, paragraph and area.
In the Studio view, you will see that the "dev" split is loaded. This is a sample of the train split that we will use for iterating on labeling functions. Click the Dev set dropdown in the top toolbar, select Resample data, and then set the Sample size to 4. Click the Resample dev split button. We are now ready to define labeling functions.
Define labeling functions
The key data programming abstraction in Snorkel, a labeling function (LF), is a programmatic rule or heuristic that assigns labels to unlabeled data. Each labelling function votes on whether a data point has a particular class label. The Snorkel label model is responsible for estimating LF accuracies and aggregating them into training labels.
For PDF extraction applications, we add a few text fields that are useful for defining LFs using the RichDocSpanRowFeaturesPreprocessor operator. These fields are based on heuristics, and are defined below:
| Field | Description |
|---|---|
rich_doc_row_text_inline | text in the same row as the span |
rich_doc_row_header | text that is the furthest to the left of the span |
rich_doc_inferred_row_headers | text that is above the span and indented to the left |
rich_doc_row_text_before | text in the row before the span |
rich_doc_row_text_after | text in the row after the span |
You can use these columns to define text-based LFs, which you may have seen in other lessons. You can also use the word bounding boxes (top, left, bottom and right) to define location-based LFs. Here are a few example LFs to try over these columns:
| LF Template | Settings | Label | Explanation |
|---|---|---|---|
| Keyword Builder | rich_doc_inferred_row_headers [CONTAINS] Assets, Cash, Land | ASSETS | The LF checks if the inferred row header of the span contains the keywords Assets, Cash or Land. |
| Keyword Builder | rich_doc_row_text_inline [CONTAINS] Liabilities, Payable, Debt | LIABILITIES | The LF checks if the text in the same as the span contain the keywords Liabilities, Payable or Debt. |
| Regex Builder | rich_doc_row_header [CONTAINS] Total.{1,15}equity | EQUITY | The LF checks if the row header of the span matches the regex pattern. |
| Numeric Builder | right [<=] 1200 | OTHER | The LF checks if the span's right boundary is less than or equal to 1200 pixels i.e. if the span is on left side of the page. |
Some LF templates are only available for PDF extraction applications. These allow us to combine the text and layout information to define LFs. Here are some examples you can try:
| LF Template | Settings | Label | Explanation |
|---|---|---|---|
| Span Regex Proximity Builder | If the span is up to [6] [LINE(s)] [AFTER] the regex pattern current assets: | ASSETS | This LF specifies that spans up to 6 lines after the expression “current assets:” will be labeled ASSETS. |
| Span Regex Row Builder | If the span is [0] rows before and [5] rows after the regex pattern current liabilities: | LIABILITIES | This LF specifies that spans up to 5 rows after the expression “current liabilities:” will be labeled LIABILITIES. |
| Rich Doc Expression Builder | Evaluate Common stock with SPAN.left > PATTERN1.right and SPAN.top >= PATTERN1.top | EQUITY | This LF specifies that spans to the right and below the expression “Common stock” will be labeled as EQUITY. |
For more information on Rich Doc builders, see Rich document LF builders. Snorkel Flow allows you to encode your custom labeling function logic using the Python SDK. Please refer to the SDK reference for examples using the RichDocWrapper object.
Train a model
The labeling functions that we defined above can be aggregated and used to train a model. Click the Train model button and select Logistic Regression (TFIDF). We'll want to include the text fields we used to define labeling functions. Click Input Fields and select rich_doc_row_text_inline, rich_doc_row_header and rich_doc_inferred_row_headers from the dropdown. Under training sets, leave the default option Create a new training set unchanged. Select Train custom model. This will initiate a process to generate labels using the LFs, and train a logistic regression model using the labels. Snorkel Flow offers default configurations for several commonly used models. For more information on models, see Model training.
Once the model training is completed, you will see your first model under the Model tab. Snorkel Flow enables users to iteratively generate better labels and better end models. Review the Analysis section to view metrics and get suggestions on how to improve model performance. For more information please refer to Analysis: Rinse and repeat.
Conclusion
You have now learned how to set up and iterate on a PDF extraction application in Snorkel Flow! To keep learning about PDF extraction features in Snorkel, please see our other documentation on this:
- Learn how to work with scanned documents with our OCR guide.
- Read more about PDF-based Operators.
- Check out more examples of Rich Document Builders.
The Snorkel Flow Python SDK provides greater flexibility to define custom operations. Select Notebook on the left-side pane to access the SDK. See the SDK reference to learn more about custom operators and custom labeling functions.